 andkov
commented
8 years ago
andkov
commented
8 years ago 2015-Dec-19 version

Open andkov opened 8 years ago
andkov
commented
8 years ago 2015-Dec-19 version
 ampiccinin
commented
8 years ago
ampiccinin
commented
8 years ago Oooooo – nice! What do you think?
Fluid can be purple or red, though it would be best to know/check what it is first to know which is better.
ampiccinin
commented
8 years ago ….except some of the detail seems to have disappeared…
So - we want the general name along the left, but the test name should as much as possible remain in the individual cells.
andkov
commented
8 years ago I agree, let's wait (anybody's checking on that?) and decide on the colour when we know. I am more concerned with the following question: should the difference in colour convey any meaning? That is, is there a reason why language and fluency are sort of similar hue, while workmemory and speed are visually more contrasting. In other words, in your understanding the color is purely categorical and implies no order, not even partial?
ampiccinin
commented
8 years ago Sorry – and prose is the same as proserecall.
ampiccinin
commented
8 years ago Knowing it is EAS I can check, but if you have renamed it I will need to know the original name. A
andkov
commented
8 years ago @ampiccinin , i don't understand your comment about except some of the detail seems to have disappeared. Details of the graph? Details of the data? Is it good thing, bad thing? Do you want them back? Which ones? Could you be more specific please?
andkov
commented
8 years ago I recoded prose into proserecall and tried a different color scale. The new scale doesn't follow the logic of color @ampiccinin suggested, simply maximizes the contrast across all colours and adjoining elements.
 @ampiccinin , what do you think, should we try to imbue color with some meaning or just maximize the contrast? I would prefer the former, but i'm failing to get to a good system in which this would make sense. Also, the latter choice is simpler technically, which may be a factor if we add more domains.
@ampiccinin , what do you think, should we try to imbue color with some meaning or just maximize the contrast? I would prefer the former, but i'm failing to get to a good system in which this would make sense. Also, the latter choice is simpler technically, which may be a factor if we add more domains.
On a related note, do you see a way to condense the domain map even further? Would that even be desirable?
andkov
commented
8 years ago So - we want the general name along the left, but the test name should as much as possible remain in the individual cells.
@ampiccinin, Could you please give an example of what labels on the left side of the graph ( for example for , raven and codingtask) should read? I'm not sure I follow your thought. The names on the left side of the graph come directly from the file names of the submitted models. Do you mean we may need two labels to describe one cognitive measure? (in addition to classifying them into domains).
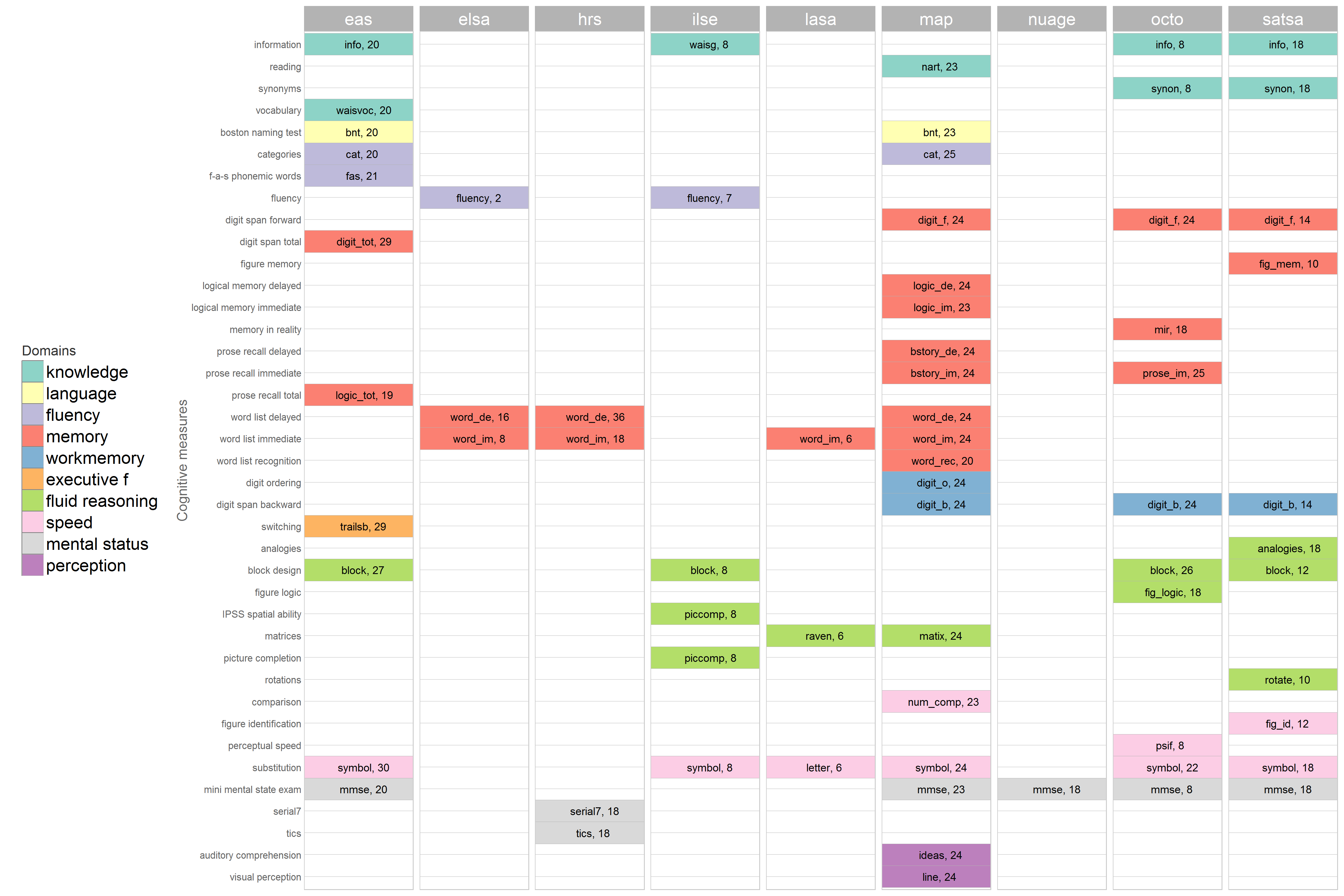
Here's the current model count in the physical-cognitive track by cognitive measure and study BEFORE RENAMING
eas elsa hrs ilse lasa nuage octo radc satsa
block . . . . . . 20 . .
codingtask . . . . 6 . . . .
delayedrecall . 8 . . . . . . .
digitbackward . . . . . . 18 . .
digitforward . . . . . . 18 . .
digitsymbol . . . . . . 18 . .
executive 19 . . . . . . 50 10
figurelogic . . . . . . 12 . .
fluency 57 2 . 7 . . . 23 .
fluid 10 . . . . . . . .
global 10 . . . . 18 8 . 16
immediaterecall . 8 4 . 6 . . . .
knowledge 34 . . 8 . . 16 23 54
language 10 . . . . . . 47 .
memory 49 . 36 . . . 32 188 28
mental 10 . 36 . . . . 45 2
mirrecall . . . . . . 12 . .
nocog 32 . . 10 . 40 . . .
prose . . . . . . 6 . .
proserecall . . . . . . 14 . .
raven . . . . 6 . . . .
reasoning 28 . . 24 . . 16 24 12
speed 30 . . 8 . . 16 47 30
visuospatial . . . . . . . 4 10 Here is the current list of unique cognitive measures across studies (after renaming and classification into domains)
|cognitive_construct |cognitive_measure | count|
|:-------------------|:-----------------|-----:|
|executive |executive | 79|
|fluency |fluency | 89|
|knowledge |knowledge | 135|
|language |language | 57|
|memory |delayedrecall | 8|
|memory |digitsforward | 18|
|memory |memory | 333|
|memory |mirrecall | 12|
|memory |proserecall | 20|
|memory |wordlistimmed | 18|
|mental |mental | 93|
|speed |codingtask | 6|
|speed |speed | 131|
|speed |symbol | 18|
|vsreasoning |block | 20|
|vsreasoning |figurelogic | 12|
|vsreasoning |raven | 6|
|vsreasoning |reasoning | 104|
|vsreasoning |visuospatial | 14|
|workmemory |digitsbackward | 18|
|NA |fluid | 10|
|NA |global | 52|
|NA |nocog | 82|you can review the details of renaming and classification in scripts/post-processing/rename_and_classify.R
ampiccinin
commented
8 years ago @andkov – please see rows for “reason” in red and “memory” in blue.
“reason” and “memory” should be the row labels, but in each of the blue or red boxes we should see something more about what that memory measure is. Didn’t we have this before? Maybe they were always just labeled memory and I just did not notice before? (maybe it is only now clear since the graph is streamlined?) Same with reason.
Another, perhaps simpler, example, is digitsbackward: “digitsbackward” is the row label, but the cell label is only “digits”, which provide less, rather than (the desirable) more information (i.e., the detail to which I was referring).
I see, too, that we run into a challenge when a study has more than one measure for a domain. While we want this, we need a good way to deal with it. I thought we could do this with, e.g., different memory domains (word list, prose, etc.), but there could also be situations with more than one within a domain (e.g., MAP has East Boston and Logical Memory) so we need a way to include both without needing too many row (or something).
Also, several studies have a digitsymbolsubstitution task, but the graph now seems to only contain one (LASA).
Hmmm… and part of the difficulty is that our “row labels” are a mix of the “domains” and the “measures”. Rest assured this is an ongoing problem. The issue is that there are often several levels of details within a domain – more for some than others. Dow this help in thinking how to organize the material?
Hope this helps.
 wibeasley
commented
8 years ago
wibeasley
commented
8 years ago Two suggestions
Use white text in the boxes with dark backgrounds. The black text is harder to read against the dark green, blue, and red fills. If you need to expand to more categories, this helps expand the available color space to darker backgrounds.
Move a lot of the metadata from code into data files. In this case, I'm thinking a single csv with one row per distinct observed entry (eg, c("bostonmaning", "nostonnaming", "bostonnaming") represents three rows). The CSV would have at least three columns: (a) entry, (b) category/construct, (c) domain. If I understand correctly, this structure would also address @ampiccinin's concern that "but there could also be situations with more than one within a domain".
The CSV might start like:
| Category | Entry | Domain |
|---|---|---|
| bnt | bostonmaning | cognitive |
| bnt | nostonnaming | cognitive |
| bnt | bostonnaming | cognitive |
This CSV could be interpreted & edited by anyone; not just those with R knowledge. A second advantage is that the metadata is separated from the code, so the structure can be reused in more places (both within a workshop, and for new workshops).
The recategorization code is fairly simple; use a left join to add a new column. For cleaning misspelled words, I use something like plyr::mapvalues(), which replaces values in an existing column.
If you want to take this approach, tell me how you'd like me to help. Start the CSV first though.
andkov
commented
8 years ago It does, thanks, @ampiccinin. Some of these things are limitations of the medium: when long strings are used (e.g. Digitsfowrardsubstitution) it messes up the chart display, so I had resort to shortening each variable name to its first six characters followed by the number of models observed with this predictor.
But I think you raise a bigger issue. We don't know how many cognitive measures there will be. Probably more than we can comfortably analyze. Breaking them down into domains help us think about groups of cognitive measures as clusters. We don't know how many clusters there should be or how many and what items should constitute each cluster. In addition, whatever system we develop right now, it may break down in the future as we have more cognitive measures or the cognitive measures would be of different assortment.
So realizing that this, as you said, is a recurring problem, should help us shape our efforts. Namely, we should expect that the problem of mapping cognitive measures into a domain does not have some fixed solution that could be applied automatically after updating input. Instead, The most current version of the model tally in any given track of the Portland project (e.g. Physical-cognitive) should be a product of deliberate human attention and documented decision.
Would you mind meeting sometimes early next week to settle on the current version of the model tally for the physical � cognitive track?
andkov
commented
8 years ago @wibeasley, I was just starting to think through the flow of using this metadata csv. I'll get started on this in a couple of hours, I'm in a much better position to know what you mean now.
ampiccinin
commented
8 years ago Monday morning would work for me.
wibeasley
commented
8 years ago when long strings are used (e.g. Digitsfowrardsubstitution) it messes up the chart display, so I had resort to shortening each variable name to its first six characters followed by the number of models observed with this predictor.
Your descriptions (especially the quoted text above) suggests to me that there should be at least two metadata CSVs. The first has one row per entry. The second has one row per category.
Entry Table:
| domain | category_short | entry | notes |
|---|---|---|---|
| cognitive | bnt | bostonnaming | |
| cognitive | bnt | bostonmaning | misspelled |
| cognitive | bnt | nostonnaming | misspelled |
Category Table:
| domain | category_short | category_long | category_multiline | color_fill | color_text |
|---|---|---|---|---|---|
| cognitive | bnt | Boston Naming Test |
Boston\nNaming\nTest |
#030542 |
#FFFFFF |
| cognitive | ant | Auntie Naming Test |
Auntie\nNaming\nTest |
#EEDECA |
#000000 |
andkov
commented
8 years ago @wibeasley , I've created a .csv file `./scripts/post-processing/filter_table.csv that contains renaming and classification instructions. I've decided to combine data into a single frame; please explain the benefits of keeping them separate.
The filter in this .csv file is supposed to carry out the same function as the script ./scripts/post-processing/rename-and-classify.R.
Columns alt1 through altK give alternative names and spellings of the same entry. If the name of the cognitive measure matches ANY of the values in entry, alt1:altK then the values to the left of the column entry are being assigned to this entry.
I've created the script ./scripts/post-processing/rename-and-classify-filter.R to test it against the older, manual version.
wibeasley
commented
8 years ago please explain the benefits of keeping them separate.
It avoids the "alt1", "alt2"... pattern, and some of the clean up code is simpler.
Conceptually, database architects prefer the "normalized" one-to-many structure. It's kinda similar ot one MLM data is stored before flattening out (to send to something like lmer).
andkov
commented
8 years ago ah, I see. I need to re-think think this. I'll make separate files, entry_table.csv and category_table.csv and follow your pattern strictly, i think I get it now.
andkov
commented
8 years ago @ampiccinin , @smhofer , @GracielaMuniz , @annierobi , @casslbrown , @andreazammit , @ph-rast
The new informational display for the census of the Portland Workshop is here

This represents the registry of cognitive outcomes for this workshop. We have one final editing to do, before we commit this structure to the REDCap Survey. This is the structure that will go in all the publications, representing how we organized these cognitive variables.
Please help us finalize this organization.
Please study this graph and offer your comments about the structure of this graph. I thought this would be easier that looking at the spreadsheet. Please formulate your comments as instructions of how this graph should be corrected (e.g. "block design should be classified as a workmemory domain" or the like). Please feel free to ask me any questions and thanks for your ideas!
andkov
commented
8 years ago 
andkov
commented
8 years ago 
 MarcusPraetorius
commented
8 years ago
MarcusPraetorius
commented
8 years ago Hi Andriy, First, very nice graph. You are definitely very talented. I have one comment specific regarding OCTO-twin and one regarding memory in general (with focus on the OCTO-twin data).
It seems that Thurstone´s picture memory is missing. It can be included as figure memory (I think that Thurstone´s picture memory is also included in SATSA) Is there a reason of why you do not separate short-term memory (i.e. digit span) and episodic long-term memory? Both are right now included as memory but their characteristics are quite different in terms of age-related change. It can also be questioned why they are not separated into two domains when knowledge (i.e. semantic memory) and working memory are defined as two sub-memory domains. My suggestion is four memory domains, i.e. short-term memory (digit span f), working memory (digit span b), semantic memory/or if you prefer, knowledge (info, synonyms) and episodic memory (mir, Thurstone´s picture memory and prose recall).@MarcusPraetorius , thanks a lot for your input.
Note to self: The substantive proximity of the domains can be reflected in the order of the domain, not the color. The purpose of color here is to maximize the ease of perception, not convey meaningful information by similarity in hue.
 andreazammit
commented
8 years ago
andreazammit
commented
8 years ago @andkov thank you for this Andrey! The colors and the graphics certainly help to visualize things!! And I do agree with what @MarcusPraetorius said, that specific tests reflect specific types of memory. However, I'm going to suggest something depending on how we are going to plan to interpret/report the results:
While referring to specific domains of memory, etc, don't you think it would be more straight forward to group these tests into the three major domains of cognition i.e. episodic memory, general ability, and executive function? Except, of course cyrstallized IQ (or semantic memory) and global cognition (what you call mental status in the spreadsheet).
So in other words, while mentioning that specific studies had specific tests that reflected very specific domains, pointing out that all, or most studies, covered the major domains of cognition (I have references on these), and then reporting by the major domains...(even though you may hint at specific tests showing specific results) but the reader would get a general feel that episodic memory plays a more prominent role than general ability for gait speed, and for grip strength executive function comes up as more significant etc etc...
Just a thought. Maybe @ampiccinin @GracielaMuniz @ph-rast can also comment on this?
 GracielaMuniz
commented
8 years ago
GracielaMuniz
commented
8 years ago Hi all,
I like Andrea's suggestion. I think that if there was a new column on the left with the names of the major domains and then, within each domain we still had the specific tests, we could see things collected by domain. In terms of reporting, I also like the suggestion of reporting by domain, but still think that within domain, we should at least try to report by test- I am slightly concerned about the possibility of the different tests having different psychometric properties that make one more sensitive to change than another test, so there could be variations across tests within domains.
Andrea @ampiccinin may have some other suggestions though..
ampiccinin
commented
8 years ago I agree.
It is always a struggle to have particular tests fit neatly within any particular set of domains – especially since there are different potential organizational systems, in some places we need more levels/differentiation than others (e.g., memory), and as new studies and measures are added there seems to almost always be a need to expand. Please suggest any other adjustments you think would be appropriate. Andrey and I have struggled with this for a while, as have Maelstrom and I.
andkov
commented
8 years ago While I agree with the last comment of @ampiccinin , I would like to remind everyone that we are not trying to set in stone how the filed of cognitive testing should cluster it in general, but merely how we should cluster it, in the context of this specific workshop, that is for this specific collection of outcomes. A different set of outcomes may render a different domain organization, so while it's important to keep the bigger picture in mind, we can just focus on the set of items in hand.
ampiccinin
commented
8 years ago Oh. I guess I misinterpreted your “can’t change it after this”.
 casslbrown
commented
8 years ago
casslbrown
commented
8 years ago Sorry to be slow in contributing! I think this looks great. I have one MAP specific note. Although complex ideational material (labeled ideas) could be considered perception I would group it with language. My thoughts on the issue of the domain groupings are that I think the way it has been grouped is a good level of detail. It allows a quick view of what kinds domains were tested. Although I agree memory could be further subdivided I think this grouping into the two categories of working memory and memory is fairly common and those interested will look at specific tests. To get around the issue of grouping digits forward with more episodic memory tasks I am wondering if would couldn't just put digits forward into working memory as it is in standard test batteries such as the WAIS?
andkov
commented
8 years ago back @GracielaMuniz ,
I think that if there was a new column on the left with the names of the major domains and then, within each domain we still had the specific tests, we could see things collected by domain.
I think the graph is already doing what you are talking about here. Notice that the row labels and cell labels are not the same. ( for example a general item "information" is represented by a specific test info in EAS and by waisg in ILSE). The structure anticipates that a general item (for another example substitution) would be operationalized by various specific test (symbol in ILSE, MAP, OCTO, and SATSA, but by letter in LASA). This produces a three tree structure DOMAIN - GENERAL item - SPECIFIC test. Let me know if you are talking about something else.
andkov
commented
8 years ago back @ampiccinin
Oh. I guess I misinterpreted your “can’t change it after this”.
Yes, i've struggled with the understanding of what can and cannot be flexible myself. I think this is because I'm not yet familiar with REDCap implementation of model sumbission. However, it makes sense to adjust the membership of the item in different domain during the secondary data analysis, being influenced by the exploratory process.
I think, @wibeasley , this will be an important facility to have during the manuscript production, because the specific story we will end up telling might requires finetuning that involves domain re-classification.
andkov
commented
8 years ago I forgot to add all EAS study from when I was testing the script with it (sorry, @andreazammit, blame the alphabet ) . Here's the updated graph, just for the record.
andkov
commented
8 years ago back @casslbrown , to the attention of @ampiccinin
Although complex ideational material (labeled ideas) could be considered perception I would group it with language.
if we place ideas into language domain, only line will be left in the perception domain. @casslbrown , what is line specifically( see row 57)? What existing domains can take it?
It doesn't make sense to keep such sparse domains, let avoid it if possible. (we already have executive f domain with a sinlge item). Any ideas where line can meaningfully go?
andkov
commented
8 years ago Thanks everyone for contributing excellent suggestions. I've thought about them and here is what I came up with.
Here's how these suggestions were incorporated. Please review them carefully (assume that I made several silly mistakes) and see if this structure resonates with you.

I've created two clusters of domains.
Thanks again for your contributions,everyone, we are almost there!
andkov
commented
8 years ago Just some working definitions I pulled from the net while working on this. Just to declare the common language
mental status examination is a structured assessment of the patient's behavioral and cognitive functioning. executive functions are a set of processes that all have to do with managing oneself and one's resources in order to achieve a goal. It is an umbrella term for the neurologically-based skills involving mental control and self-regulation. Fluid reasoning is the ability to think flexibly and problem solve. This area of reasoning is most reflective of what we consider to be general intelligence. Gifted students often have strong fluid reasoning skills. Speed is one of the measures of cognitive efficiency or cognitive proficiency. It involves the ability to automatically and fluently perform relatively easy or over-learned cognitive tasks, especially when high mental efficiency is required. fluency is simply a measure of how easy it is to think about something. The ability to generate words, ideas and mental associations to problems. It is an important dimension of creativity. Working memory is the part of short-term memory that is concerned with immediate conscious perceptual and linguistic processing. Short Term Memory is the part of the memory system where information is stored for roughly 30 seconds. Information can be maintained longer with the use of such techniques as rehearsal. To retain the information for extended periods of time; it must be consolidated into long-term memory where it can then be retrieved Episodic memory is a person's unique memory of a specific event, so it will be different from someone else's recollection of the same experience. Episodic memory is sometimes confused with autobiographical memory, and while autobiographical memory involves episodic memory, it also relies on semantic memory. Semantic memory is one of the two types of declarative or explicit memory (our memory of facts or events that is explicitly stored and retrieved). Semantic memory refers to general world knowledge that we have accumulated throughout our lives. ampiccinin
commented
8 years ago Trails and reasoning could all be called fluid
andkov
commented
8 years ago @ampiccinin , under "fluid" you must mean the domain fluid reasoning? or you want the new domain to be called fluid instead of fluid reasoning? could you please clarify?
I will move trailsb to the domain fluid reasoning, provided I understood correctly. This is great, it simplifies the picture.
Sorry, I don't see any item called reasoning, so i'm not sure I understand what you mean by
reasoning could be called fluid
Please be more specific on that.
ampiccinin
commented
8 years ago Yes – fluid reasoning. Thanks. A
casslbrown
commented
8 years ago Line is a judgment of line orientation task so it is really a visual perception/visuospatial task. However, I think it could potentially be included in mental status because that is a bit of a broader category and I agree it doesn't seem to make much sense to have it as the only test in the perception category.
casslbrown
commented
8 years ago @andkov I think the colour groups do make it more visually ordered and it is looking great! Moving language to the bottom, to be closer to semantic memory, makes sense to me. Executive function could then be moved to under mental status and above fluid reasoning. That way mental status would be at the top.
andkov
commented
8 years ago From the MAP documentation

andkov
commented
8 years ago The new outcome-space map is available.

What's new:
visual discriminationattentionworking memoryverbal comprehensionI like what we have right now, so I suggest @wibeasley , @Maleeha and myself proceed with this mapping unless we hear objections.
@ampiccinin please take a look
andreazammit
commented
8 years ago @andkov Andrey, wonderful graph and great job on this! I do have one objection. I have always been taught that Tails B is a pure executive function test. I am sorry to drag this, but in my opinion is it not a working memory test, especially because in order to do Trails B you need task-switching skills and inhibition (going back and forth between numbers and letters), just as in Stroop Word-Color (where you go between the two tasks of naming the color and reading the word); which is unlike working memory where you store info for a short period of time, like digit span or digit backwards, which is entirely different. BUT this is just my opinion! I know I was the one suggesting grouping tests into three big categories, but if you are going into such detail, I would go to the other extreme and would want to be very specific. I see @ampiccinin did mention that it could go into fluid reasoning in a previous post, and I would feel a bit happier for Trails B to belong to that group, which is more executive like. Again, this is just my opinion, and I do love the color-coding and the graph!
I just noticed one other thing - digit span total could be moved into working memory, because this is a combination of digit span forward (WM) and digit span backward (WM).... I would do that. See what @ampiccinin thinks!
Thanks so much!
ampiccinin
commented
8 years ago :) I think that for some of these measures we will never be able to come to a single decision about their domain since the often straddle several and where we put them may be driven by the context of which other measures are also being considered. I agree that it is considered to involve switching, but also holding in memory and "working on" it (in the sense of remembering where you are in the two sequences).
If we think of it as just a categorization scheme to keep measures organized, and understand that it does not necessarily mean that we have to treat it as such in the hypotheses/analyses/results, then I think it is OK (though admittedly confusing).
Understanding that in some cases we will have single measures to represent a domain (depends on the set of studies included) would, alternatively, let us retain the single measure domains.
andkov
commented
8 years ago Thanks, @andreazammit for the timely input. I see the opinions have split over trailsB! Here is what a colleague of mine mentioned about it that swayed me.
Executive Functioning: I personally am in the camp that trails B is not a measure of executive function. Some propose that an executive control measure can be derived from the ratio of Trails A to Trails B. A quick scan of the literature seems to suggest that most of the variance in trails B performance can be explained by processing speed and fluid cognitive abilities. Conceptually I think of it as visual attention + working memory + processing speed + task switching. I would be most likely to add it to the working memory domain, (probably not the attention domain),
Well, i was looking for a way to collapse the number of domains, so I was really looking for a justification NOT to have a domain with a single item. But now, I remember it was @ampiccinin decision to classify trialsb as executive function, so I suspect she would back you up.
So i'd like to propose a compromise. The trialsb will be classified in a separate domain executive function, but will stay in close space proximity to working memory and will gravitate towards the "blueish cluster" of domains.

andreazammit
commented
8 years ago @andkov that's a happy compromise for me, and I like how you placed Trails B close to the working memory variables while still keeping it distinct :) I am happy with this.
casslbrown
commented
8 years ago @andkov I just wanted to say that I think this is a great looking graph! I think having the line orientation included with picture completion is great. It really didn't seem to fit as anything other than a visual task and even my earlier suggestion would have been a stretch. I am also happy with keeping complex ideation separate as a verbal comprehension category. Thanks! It certainly is difficult to get agreement on which domain each task belongs in!
@ampiccinin has conceptualized domains into which cognitive measures could be organized as the following spectrum:
The Cognitive Domain Map has been update to reflect these changes as well as some other that has been raise before. Below is the current version of the cognitive domain map, showing the population of model for the physical-cognitive track of the Portland project.
The graph above is produced by the report `./reports/model_space/cog-domain-map-2. Please use the comments below to offer your constructive criticisms and directions for further developments. The most current version of the graph will be shown in the issue description