The newly created sectors which replace the sectors that are to be disaggregated. Either with the same amount of columns as idx_src or with an additional column or several additional columns.
Disaggregation information. I call this "disaggregation vector". The sum of a disaggregation vector should always be 1. Otherwise balancing has to be applied (?).
The disaggregation procedure is as follows and the comments should sufficiently explain the code. Obviously, some improvements can be made in the code but this also depends on the specific use case and possibly comes with trade-offs. For now, I found the function to work reasonably fast.
def disaggregate(
df,
idx_src,
idx_trg,
disaggregation_vector,
axis='both',
**kwargs
):
"""
Disaggregate a pd.DataFrame.
Parameters
----------
df : pd.DataFrame
pd.DataFrame with MultiIndex.
idx_src : list
List with tuples of index entries that are to be disaggregated.
idx_trg : list
List with tuples of new index entries that replace
the index entries that are to be disaggregated.
disaggregation_vector : list
List with tuples of the disaggregation vectors.
axis : str or int, optional
Axis to disaggregate. Permissible inputs are 'rows', 'columns',
0, 1, and 'both'. The default is 'both'.
**kwargs : list, optional
List with new `index.names` and `columns.names` if the length
of a tuple in `idx_trg` is longer than the original index.
Returns
-------
df : pd.DataFrame
The disaggregated pd.DataFrame.
"""
###############
# Check inuts #
###############
if axis not in ['rows', 'columns', 0, 1, 'both']:
raise Exception(
"Invalid input for `axis`. Only "
"'rows', 'columns', "
"0 ('rows'), 1 ('columns') "
"and 'both' "
"are valid inputs!"
)
def generic(df):
"""
Disaggegate based on a input lists. See outer function.
The disaggregation is always performed along the rows.
If the disaggregation is to be performed along
the columns. `axis` in `disaggregate` has to be se
to either 'both' (for rows and columns) or 'columns'.
In this case, the pd.DataFrame is transposed before
it is passed on to this function and transposed
again after it is returned by this function.
Parameters
----------
df : pd.DataFrame
Pandas dataframe with multi-index.
Returns
-------
df : pd.DataFrame
Disaggregated pandas dataframe with multi-index.
"""
for i in range(len(disaggregation_vector)):
######################
# Disaggregate index #
######################
# Determine the integer position
# of the original sector
# in the original index
cols = len(idx_src[i])
# Keep n first columns
test = [i[:cols] for i in df.index]
# Get the index position
idx_pos = test.index(idx_src[i])
del cols
# Turn the list of tuples of the disaggregated
# (new) index into a DF
try:
idx_new = pd.DataFrame(
idx_trg[i],
columns=df.index.names
)
# Except if the original.columns cannot be re-assigned.
# This happens if the new index has more columns
# than the original index. In that case, use `idx_trg_new_cols`
# as new columns
except ValueError:
idx_new = pd.DataFrame(
idx_trg[i],
columns=kwargs.get('idx_trg_new_cols')
# columns=kwargs.get('idx_trg_new_cols')
)
# # Concatenate the new index
idx_new = pd.concat([
# Before
df.index.to_frame().iloc[:idx_pos],
# New
idx_new,
# After
df.index.to_frame().iloc[idx_pos+1:, :]
], ignore_index=True)
######################
# Disaggregate matrix #
######################
df = pd.DataFrame(
np.concatenate([
# Rows before idx
df.iloc[:idx_pos, :],
# New rows
np.outer(df.iloc[idx_pos, :],
disaggregation_vector[i]).T,
# Rows after idx
df.iloc[idx_pos+1:, :]
]),
index=pd.MultiIndex.from_frame(idx_new),
columns=df.columns
)
return df
###################################
# Process rows or columns or both #
###################################
if axis in ['rows', 1]:
df = generic(df)
elif axis in ['columns', 0]:
df = generic(df.T).T
elif axis == 'both':
df = generic(df)
df = generic(df.T).T
return df
Let me give you an example. If I use Target index - No new columns and run ...
... an additional level in the pd.MultiIndex is created ...
The function can be applied on Y in the same manner although axis should probably be set to axis='rows'.
Does the function work correctly (albeit being obviously a very simple disaggregation procedure)? If I am right, we can check this by calculating the production-based inventory of the entire final demand of a satellite account which only contains ones (e.g. np.ones(len(io_table_Z_disaggregate))). If the production-based inventory equals the satellite account, the disaggregation has worked (am I correct?). In fact, this is the case (note that sector at index position five is an exception because the corresponding value in the disaggregation vector is zero which means no value in the satellite account can be allocated). In addition, the sum of the production-based and the consumption-based inventory should be the same which is the case (54).
Secondly, the sums of the original tables (Z and Y) and the disaggregated tables (Z and Y) should be exactly the same. Both is the case.
Full code below. RuntimeWarning: invalid value encountered in true_divide is printed in the console. Probably because of division by zero.
"""Function for performing a simple disaggregation of io-data."""
import numpy as np
import pandas as pd
import pymrio
def disaggregate(
df,
idx_src,
idx_trg,
disaggregation_vector,
axis='both',
**kwargs
):
"""
Disaggregate a pd.DataFrame.
Parameters
----------
df : pd.DataFrame
pd.DataFrame with MultiIndex.
idx_src : list
List with tuples of index entries that are to be disaggregated.
idx_trg : list
List with tuples of new index entries that replace
the index entries that are to be disaggregated.
disaggregation_vector : list
List with tuples of the disaggregation vectors.
axis : str or int, optional
Axis to disaggregate. Permissible inputs are 'rows', 'columns',
0, 1, and 'both'. The default is 'both'.
**kwargs : list, optional
List with new `index.names` and `columns.names` if the length
of a tuple in `idx_trg` is longer than the original index.
Returns
-------
df : pd.DataFrame
The disaggregated pd.DataFrame.
"""
###############
# Check inuts #
###############
if axis not in ['rows', 'columns', 0, 1, 'both']:
raise Exception(
"Invalid input for `axis`. Only "
"'rows', 'columns', "
"0 ('rows'), 1 ('columns') "
"and 'both' "
"are valid inputs!"
)
def generic(df):
"""
Disaggegate based on a input lists. See outer function.
Parameters
----------
df : pd.DataFrame
Pandas dataframe with multi-index.
Returns
-------
df : pd.DataFrame
Disaggregated pandas dataframe with multi-index.
"""
for i in range(len(disaggregation_vector)):
######################
# Disaggregate index #
######################
# Determine the integer position
# of the original sector
# in the original index
cols = len(idx_src[i])
# Keep n first columns
test = [i[:cols] for i in df.index]
# Get the index position
idx_pos = test.index(idx_src[i])
del cols
# Turn the list of tuples of the disaggregated
# (new) index into a DF
try:
idx_new = pd.DataFrame(
idx_trg[i],
columns=df.index.names
)
# Except if the original.columns cannot be re-assigned.
# This happens if the new index has more columns
# than the original index. In that case, use `idx_trg_new_cols`
# as new columns
except ValueError:
idx_new = pd.DataFrame(
idx_trg[i],
columns=kwargs.get('idx_trg_new_cols')
# columns=kwargs.get('idx_trg_new_cols')
)
# # Concatenate the new index
idx_new = pd.concat([
# Before
df.index.to_frame().iloc[:idx_pos],
# New
idx_new,
# After
df.index.to_frame().iloc[idx_pos+1:, :]
], ignore_index=True)
######################
# Disaggregate matrix #
######################
df = pd.DataFrame(
np.concatenate([
# Rows before idx
df.iloc[:idx_pos, :],
# New rows
np.outer(df.iloc[idx_pos, :],
disaggregation_vector[i]).T,
# Rows after idx
df.iloc[idx_pos+1:, :]
]),
index=pd.MultiIndex.from_frame(idx_new),
columns=df.columns
)
return df
###################################
# Process rows or columns or both #
###################################
if axis in ['rows', 1]:
df = generic(df)
elif axis in ['columns', 0]:
df = generic(df.T).T
elif axis == 'both':
df = generic(df)
df = generic(df.T).T
return df
def io_analysis(Q, Z, Y):
"""Doc."""
x = Z.sum(axis=1) + Y.sum(axis=1)
x[np.isnan(x)] = 0
# Identity matrix
IM = np.identity(len(Z))
# Technical coefficients
A = np.divide(Z, x)
A[np.isnan(A)] = 0
# Direct externalities
f = np.diag(
np.divide(Q, x)
)
f[np.isinf(A)] = 0
f[np.isnan(A)] = 0
# Leontief inverse
L_linverse = np.linalg.inv(IM - A)
L_linverse[np.isnan(L_linverse)] = 0
# Total intensities
F_linverse = np.dot(f, L_linverse)
F_linverse[np.isnan(F_linverse)] = 0
# Scale to final demand
E_linverse = np.multiply(F_linverse, Y.sum(axis=1))
E_linverse[np.isnan(E_linverse)]
print('\nProduction-based-inventory:')
print(E_linverse.sum(axis=1)) # Outputs/Production (Rows)
print('\nConsumption-based-inventory:')
print(E_linverse.sum(axis=0)) # Inputs/Consumption (Columns)
# %% Test run
# %%% Input data
# Source index
idx_src = [
# Sector 1
('reg1', 'food'),
# Sector 2
('reg2', 'food'),
# Sector 3
('reg3', 'food')
]
# Target index - New columns
idx_trg = [
# Newly disaggregated sectors #1
[('reg1', 'food', 'McDonalds'),
('reg1', 'food', 'Burger King'),
('reg1', 'food', 'Pizza Hut'),
('reg1', 'food', 'SubWay'),
('reg1', 'food', 'FiveGuys')],
# Newly disaggregated sectors #2
[('reg2', 'food', 'McDonalds'),
('reg2', 'food', 'Burger King')],
# Newly disaggregated sectors #3
[('reg3', 'food', 'McDonalds'),
('reg3', 'food', 'Burger King'),
('reg3', 'food', 'Pizza Hut')]
]
if False:
# Target index - No new columns
idx_trg = [
# Newly disaggregated sectors #1
[('reg1', 'McDonalds'),
('reg1', 'Burger King'),
('reg1', 'Pizza Hut'),
('reg1', 'SubWay'),
('reg1', 'FiveGuys')],
# Newly disaggregated sectors #2
[('reg2', 'McDonalds'),
('reg2', 'Burger King')],
# Newly disaggregated sectors #3
[('reg3', 'McDonalds'),
('reg3', 'Burger King'),
('reg3', 'Pizza Hut')]
]
# Disaggregation vectors
disaggregation_vector = [
[0.25, 0.5, 0.125, 0.125, 0],
[0.25, 0.75],
[1/3, 1/3, 1/3]
]
# %% % Disaggregation
io_table = pymrio.load_test() # https://pymrio.readthedocs.io/
sum_before_z = io_table.Z.sum().sum()
sum_before_y = io_table.Y.sum().sum()
io_table_Z_disaggregate = disaggregate(
df=io_table.Z.copy(),
idx_src=idx_src,
idx_trg=idx_trg,
disaggregation_vector=disaggregation_vector,
axis='both',
# `idx_trg_new_cols` is redundant if a tuple in `idx_trg`
# has the same length as a tuple in the original index
idx_trg_new_cols=['region', 'sector', 'gourmet']
)
io_table_Y_disaggregate = disaggregate(
df=io_table.Y.copy(),
idx_src=idx_src,
idx_trg=idx_trg,
disaggregation_vector=disaggregation_vector,
axis='rows',
# `idx_trg_new_cols` is redundant if a tuple in `idx_trg`
# has the same length as a tuple in the original index
idx_trg_new_cols=['region', 'sector', 'gourmet']
)
print(sum_before_z)
print(io_table_Z_disaggregate.sum().sum())
print(sum_before_y)
print(io_table_Y_disaggregate.sum().sum())
# %%% Inventory-test
io_table_full_Q = np.ones(len(io_table_Z_disaggregate))
# Sector 5 (Five Guys) is zero because the value in
# the disaggregation matrix is zero
io_analysis(
io_table_full_Q,
io_table_Z_disaggregate.values,
io_table_Y_disaggregate.values
)
Is this procedure correct (given the simplified assumptions)? Would it be interesting to implement this function in pymrio? If yes, could you point me in the direction of where exactly in the pymrio-code it would make sense to integrate this functionality?
Hello Konstantin & everyone,
I I wrote a function for performing a most simple disaggregation of io-data as described e.g. in UN Statistics Division (1999).
We can use
pymrio.load_test()for demonstration. My function requires three inputs. All of them are a list of tuples.idx_srcor with an additional column or several additional columns.The disaggregation procedure is as follows and the comments should sufficiently explain the code. Obviously, some improvements can be made in the code but this also depends on the specific use case and possibly comes with trade-offs. For now, I found the function to work reasonably fast.
Let me give you an example. If I use
Target index - No new columnsand run ...... the original table ...
... receives some new sectors ...
If I use
Target index - New columnsand run ...... an additional level in the
pd.MultiIndexis created ...The function can be applied on
Yin the same manner althoughaxisshould probably be set toaxis='rows'.Does the function work correctly (albeit being obviously a very simple disaggregation procedure)? If I am right, we can check this by calculating the production-based inventory of the entire final demand of a satellite account which only contains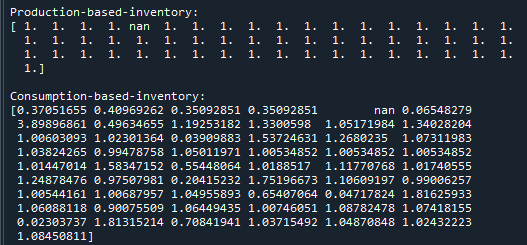
ones(e.g.np.ones(len(io_table_Z_disaggregate))). If the production-based inventory equals the satellite account, the disaggregation has worked (am I correct?). In fact, this is the case (note that sector at index position five is an exception because the corresponding value in the disaggregation vector is zero which means no value in the satellite account can be allocated). In addition, the sum of the production-based and the consumption-based inventory should be the same which is the case (54).Secondly, the sums of the original tables (Z and Y) and the disaggregated tables (Z and Y) should be exactly the same. Both is the case.
Full code below.
RuntimeWarning: invalid value encountered in true_divideis printed in the console. Probably because of division by zero.Is this procedure correct (given the simplified assumptions)? Would it be interesting to implement this function in
pymrio? If yes, could you point me in the direction of where exactly in the pymrio-code it would make sense to integrate this functionality?