 YodaEmbedding
commented
2 months ago
YodaEmbedding
commented
2 months ago Please see the following two sections:
- https://yodaembedding.github.io/post/learned-image-compression/#probabilistic-modeling-for-data-compression
- https://yodaembedding.github.io/post/learned-image-compression/#entropy-modeling
Briefly, each element of y is encoded using a probability distribution p. The y_likelihoods represent the value p(y).
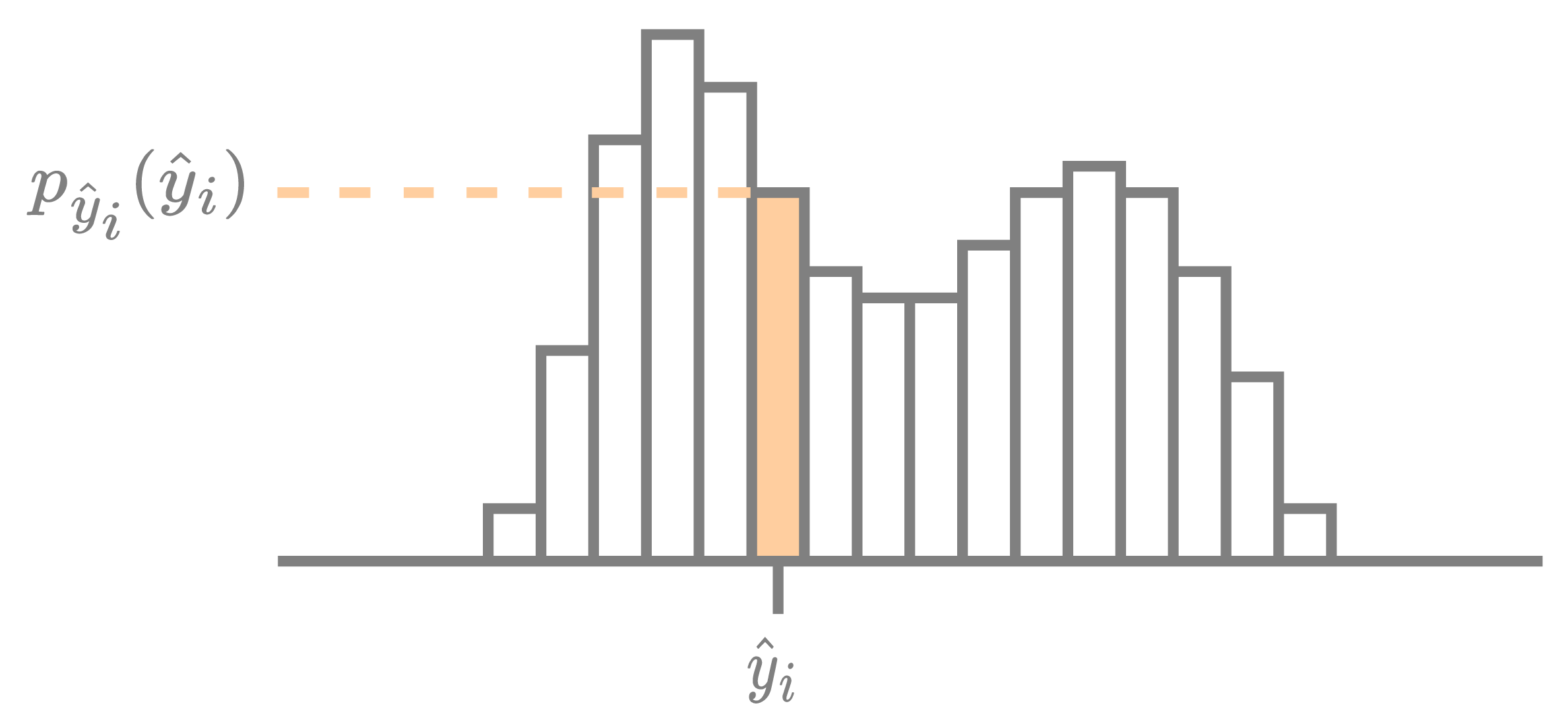
A given element $\hat{y}_i \in \mathbb{Z}$ of the latent tensor $\boldsymbol{\hat{y}}$ is compressed using its encoding distribution $p_{{\hat{y}}_i} : \mathbb{Z} \to [0, 1]$, as visualized in the figure below. The rate cost for encoding $\hat{y}_i$ is the negative log-likelihood, $R_{{\hat{y}}_i} = -\log_2 p_{{\hat{y}}_i}({\hat{y}}_i)$, measured in bits. Afterward, the exact same encoding distribution is used by the decoder to reconstruct the encoded symbol.
Visualization of an encoding distribution used for compressing a single element $\hat{y}_i$. The height of the bin $p_{\hat{y}_i}(\hat{y}_i)$ is highlighted since the rate is equal to the negative log of this bin.
 Bian-jh
Bian-jh
Sorry to bother you, I am recently been in the area of compression, take VARIATIONAL IMAGE COMPRESSION WITH A SCALE HYPERPRIOR as example, what is the meaning of each element in y_likelihoods matrix("likelihoods": {"y": y_likelihoods})?