 whikloj
commented
8 years ago
whikloj
commented
8 years ago Regarding 2ii above, by separate I mean two separate actions. So you can create the basic image resource, and then later you can add the binary.
Closed whikloj closed 8 years ago
whikloj
commented
8 years ago Regarding 2ii above, by separate I mean two separate actions. So you can create the basic image resource, and then later you can add the binary.
 ruebot
commented
8 years ago whikloj
commented
8 years ago
ruebot
commented
8 years ago whikloj
commented
8 years ago About that image though, here is the thing I am wondering about.
If we put a JPG up, then we automatically have a place in Fedora 4 to store metadata about that JPG (the /fcr:metadata endpoint). So every ldp:NonRdfSource also has an ldp:RdfSource associated with it.
Then each binary can have it's FITS (or whatever) metadata applied on it's RdfSource and we don't have to have a separate FITS file. Unless you really want to add a file of metadata, but I'd just stick the metadata as properties.
ruebot
commented
8 years ago FITS... yeah. That is complicated. I'd honestly leave it as a NonRdfSource; xml file on the file system. But! BUT! @acoburn and I lead this working-group-sub-group, which created a Technical Metadata Application Profile. Maybe we're finally there? :smile:
whikloj
commented
8 years ago @DiegoPino you mentioned you are working on this, yes?
 DiegoPino
commented
8 years ago
DiegoPino
commented
8 years ago @whikloj, yes i am. So open to suggestions
whikloj
commented
8 years ago Nope, was just going to assign it to you. All good.
DiegoPino
commented
8 years ago @ruebot & @whikloj can you give https://www.ebu.ch/metadata/ontologies/ebucore/ a look and give me some guides/ideas if this is enough to describe tech metadata for now? We can add as many other extra nonRdfSources if needed (like FITS) but i would like to have some base ones as RDF too.
ruebot
commented
8 years ago @DiegoPino how about this?
That's the group @acoburn and I led last year.
ruebot
commented
8 years ago ...and my preference would still be to have FITS xml file stored (wearing my preservationista hat). So, I'm sure I'll be create a FITS service sooner or later for that.
DiegoPino
commented
8 years ago @ruebot, yeah that is fine (Hydra links), but there is no agreement right now there right?And this is limiting us to a few ebucore entities? I mean, if we have the whole ontology available, why limit us self to a subset and also put other namespaces in place too to complement? 100% with you on FITS.
DiegoPino
commented
8 years ago Also, what about EXIF?
ruebot
commented
8 years ago @DiegoPino the second link is the agreement. That's what the Hydra folks are implementing.
ruebot
commented
8 years ago EXIF is in FITS
DiegoPino
commented
8 years ago @ruebot, ok, the agreement has non existing stuff, e.g pcdm:Document can't be the domain of (not a class?), do they mean https://github.com/duraspace/pcdm/blob/master/pcdm-ext/file-format-types.rdf? pronom also? Ok, i would vote for this on Claw: lets make FITS happen. Also, cool: http://projects.iq.harvard.edu/fits/news/fits-web-service-v111-released We need a way to extract the data anyway. Then transform FITS to ebucore and Exif (exif RDF, not the xml). We will still have the hydrastuff, + our own extras. Sounds good?
ruebot
commented
8 years ago Sorry, I'm confused, is this meant to be in the image service? It seems to be like there should be a standalone/complimentary file characterization/identification service. Because more than image is going to need it. Might be getting ahead of ourselves?
DiegoPino
commented
8 years ago https://github.com/Islandora-CLAW/CLAW/issues/212 was just keeping the conversation here, out of scope of course but related to any pcdm:Object like
DiegoPino
commented
8 years ago @ruebot and @whikloj, @acoburn, @br2490, @nigelgbanks, @edf, @dltj. Last intervention before coding: Do we really need a difference between basic image, large image, or any other type of visual/2D non moving content modelling? It's all about the derivatives at the end and the viewers. So what about "Let's do an Still Image Microservice?"
ruebot
commented
8 years ago http://pcdm.org/2015/10/14/file-format-types#Image
That would be my vote.
 acoburn
commented
8 years ago
acoburn
commented
8 years ago @ruebot: you mean something like, trigger on:
<> dcterms:format pcdmformat:Image@acoburn I think it would have to be a combination of pcdm:Image plus mime-type. But, then we hit the problem @daniel-dgi and I talked about early on in the project. An image could be just a plain old jpg like we have now with the Basic Image SP. Or a tiff/jp2, which could be a still image (digitized photograph), or digitized page of a book. So, then, does it get OCR'd as well? Or maybe that can be solved with another predicate... like what we were considering our SPs to become. A combination of predicates on objects, plus services.
DiegoPino
commented
8 years ago @ruebot i will follow your advice (mm...i feel so much pcdm is redefining what is already in place...exact matches everywhere!), but in this case i would go anything. I see Fits service digest almost anything.
DiegoPino
commented
8 years ago @ruebot definitively a predicates + rdf:type match. I would say, lets process only what is a preservation master or is marked to be processed somehow. Avoid derivatives to trigger this. Also: OCR and this type of further processing would (in my preference) not be a data modelling issue, but a decision based on formats. So a image could have OCR triggered if the user wants so. This brings us closer to the reality of RDF versus our old/fixed Content models.
acoburn
commented
8 years ago @ruebot sure, the matching predicate for this can arbitrarily complex. But remember, we can follow Borges's pattern with https://en.wikipedia.org/wiki/The_Garden_of_Forking_Paths
Binary (mime/type = x) -> endpoint a, b
Binary (mime/type = y) -> endpoint c
Binary (mime/type = z) -> endpoint a, c, dI guess this my cue for further complicating things by suggesting we make use of the Archivematica Format Policy Registry... https://www.archivematica.org/en/docs/fpr/
DiegoPino
commented
8 years ago @ruebot, no further complication at all. This is what we talked a few months ago: I think this is fine: So i will add to my workflow Archivematica Format Policy Registry and research that side (i don't have an Archivematica background good enough for this stuff, but will learn)
ruebot
commented
8 years ago paging @jhsimpson -- you might be interested in where this conversation is going.
 jhsimpson
commented
8 years ago
jhsimpson
commented
8 years ago Is the PCDM use ontology relevant here: https://github.com/duraspace/pcdm/blob/master/pcdm-ext/use.rdf
The Archivematica Format Policy Registry currently uses PRONOM id's as the key for identifying file formats, and there is no rdf version of pronom (yet). So that is a problem. The current version of the FPR also does not understand linked data.
I am not sure if the timing will work out, but I think work on a new, linked data based version of the FPR will be getting under way soon. There is a short video I made a year ago describing the idea: https://www.youtube.com/watch?v=dfRtZFiRp6U&feature=youtu.be
We made a format policy registry mailing list last year also, which never really got off the ground: https://groups.google.com/forum/#!forum/format-policy-registry
@DiegoPino @ruebot I would encourage you to ask questions about the fpr on that list.
@mjordan wrote a proof of concept FPR module for Islandora last year: https://github.com/mjordan/islandora_fpr
That might be one place to start?
ruebot
commented
8 years ago @jhsimpson would you be willing to join us on CLAW Call in the next couple weeks to flesh this out a bit more? I'm happy to devote an entire call to it if need be.
jhsimpson
commented
8 years ago Yes for sure definitely. Let me know a time. On Apr 27, 2016 18:55, "Nick Ruest" notifications@github.com wrote:
@jhsimpson https://github.com/jhsimpson would you be willing to join us on CLAW Call in the next couple weeks to flesh this out a bit more? I'm happy to devote an entire call to it if need be.
— You are receiving this because you were mentioned. Reply to this email directly or view it on GitHub https://github.com/Islandora-CLAW/CLAW/issues/179#issuecomment-215284708
jhsimpson
commented
8 years ago May 18th - yep, I will be there.
ruebot
commented
8 years ago @jhsimpson awesome! I've updated the agenda, and have a FITS Web Service item on there -- @DiegoPino @acoburn -- since it might be a good overlap discussion.
jhsimpson
commented
8 years ago Here are some details about how to interact with the Archivematica FPR Server, as it exists right now:
This should give you a list of all the end points: https://fpr.archivematica.org/fpr/api/v2/?format=json
Lets say you have a file, that you have already identified as a GIF, and you know the pronom id: https://fpr.archivematica.org/fpr/api/v2/format-version/?pronom_id=fmt/4&format=json this returns info about GIF 1989a
take the uuid from that and put it in this url:
take the uuid of that fp-rule and plug it into this :
now you have the command line for convert, the utility in imagemagick that conversts the gif to a jpg.
for additional info, you can get details about the version of the tool (convert) with this: https://fpr.archivematica.org/fpr/api/v2/fp-tool/?format=json&uuid=8d81cd4f-20ee-4a82-9eca-455699509cd5
DiegoPino
commented
8 years ago @jhsimpson++. This is very cool. Thanks a lot
 axfelix
commented
8 years ago
axfelix
commented
8 years ago Since I'm assuming we never ever ever want to do derivative generation at ingest time ever again for scalability reasons, what would be the simplest way to implement this currently? Something like:
ruebot
commented
8 years ago @axfelix Apache Camel :smile:
...we can expand more on this later... since I'm about to give another presentation here at OR.
axfelix
commented
8 years ago OK, sure. I do not know anything about Camel at this point so I'm not sure how much of my spitballing is already handled :)
DiegoPino
commented
8 years ago @axfelix we are giving Fedora 4 API-X a look also (had a CLAW API-X FEDORA 4 meeting here at OR2016). And guess what. First prototype will be based on our php MicroServices idea. Async, cross platform and based on existing good practices (Archivematica).I'm look to have a talk about this in the next Claw call and you are very well invited to join us. Thanks for bringing this up1
axfelix
commented
8 years ago I'll be there! I'm not sure how many cycles I'll have for this and I'm neither qualified for nor interested in "low-level" PHP architecting (which is why I've stayed out of CLAW discussions so far) but I do want to see how this part shapes up.
acoburn
commented
8 years ago @ruebot I have already written such a service in camel/OSGi. More on that soon.
acoburn
commented
8 years ago @ruebot Here's my implementation of the image service: https://gitlab.amherst.edu/acdc/repository-extension-services/tree/master/acrepo-image-service
It streams binary data directly from Fedora through ImageMagick and then back out. It handles format conversions, resizes, etc. Basically, anything convert can handle.
acoburn
commented
8 years ago Oh, and you can completely ignore the owl inference stuff (i.e. the OPTIONS endpoint). It's completely half-baked and quite possibly wrong -- I'd like to get some feedback from @DiegoPino on that. The idea is that for API-X, services should provide a set of OWL restrictions so that services can be dynamically bound to certain resources, but none of that inference piece has actually been implemented.
acoburn
commented
8 years ago ...and also, we have a FITS metadata extraction service in the works -- should be ready this week. It exposes a REST endpoint and then pipes fedora:Binary resources through the FITS-servlet web application (which must be running somewhere) and returns the FITS xml document.
ruebot
commented
8 years ago @acoburn y'all are pretty awesome :smile:
...skimming through the other services and issues you have there...
DiegoPino
commented
8 years ago @jhsimpson and @ruebot just got this one from @rosiel (thanks a lot Rosie!). Not sure if this is the right spot for new ideas for provenance ontologies, but since there is still no archivematica github repo for discussing, i will just copy here for posterity. http://www.ics.forth.gr/isl/index_main.php?l=e&c=656 and http://doc.objectspace.org/cidoc/
{kind=link}
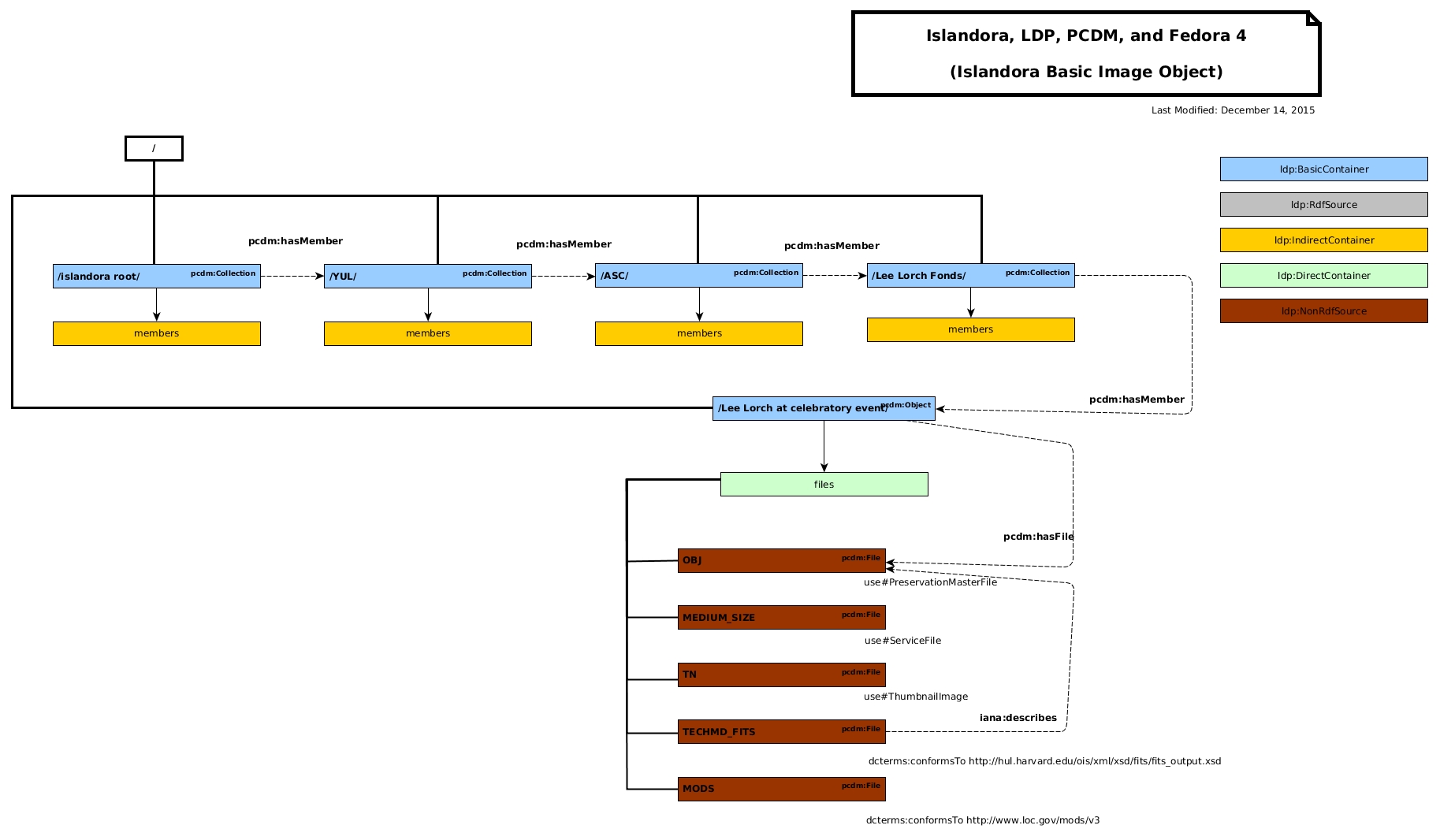
We need a basic image microservice.
This will generate a pcdm:Object with a UUID and hasURN like the existing Collection microservice.
Questions: