 JemmyH
commented
3 years ago
JemmyH
commented
3 years ago epoll 相关的数据结构与方法
与 epoll 相关的系统调用有以下三个:
这三个方法可以在 Linux 系统的机器上通过
man 2 xxx的方式查看具体用法/* 返回 epoll 实例的文件句柄,size 没有实际用途,传入一个大于 0 的数即可。 */ int epoll_create(int size);
/ 让 epoll(epfd)实例 对 目标文件(fd) 执行 ADD | DEL | MOD 操作,并指定”关心“的事件类型 /
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
/ 阻塞等待所”关心“的事件发生 / int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
与 `select` 相比,`epoll` 分清了 **频繁调用** 和 **不频繁调用** 的操作。例如,`epoll_ctl` 是不太频繁调用的,而 `epoll_wait` 是非常频繁调用的。
这是 `epoll` 最常见的 demo:
```c
#include <stdio.h>
#include <unistd.h>
#include <sys/epoll.h>
int main(void)
{
int epfd,nfds;
struct epoll_event ev; // ev用于注册事件,表示自己关心的事哪些事件
struct epoll_event events[5]; // events 用于接收从内核返回的就绪事件
epfd = epoll_create(1); // 创建一个 epoll 实例
ev.data.fd = STDIN_FILENO; // 我们关心的是命令行输入
ev.events = EPOLLIN|EPOLLET; //监听读状态同时设置ET模式(这个后面会讲,可以简单理解成:文件内容发生变化时才会触发对应的事件)
epoll_ctl(epfd, EPOLL_CTL_ADD, STDIN_FILENO, &ev); // 注册epoll事件
for(;;)
{
nfds = epoll_wait(epfd, events, 5, -1); // 进入死循环,最后的 -1 表示无限期阻塞,直到有事件发生
// epoll_wait 返回,表示有对应的事件发生,事件的信息存储在 events 数组中。nfds 表示数组的长度。接下来逐个处理事件
for(int i = 0; i < nfds; i++)
{
if(events[i].data.fd==STDIN_FILENO)
printf("welcome to epoll's word!\n");
}
}
}接下来我们看看 epoll 相关的数据结构。
eventpoll
/*
* This structure is stored inside the "private_data" member of the file
* structure and represents the main data structure for the eventpoll
* interface.
*/
struct eventpoll {
// 保护 rbr(红黑树) 和 rdllist(等待队列)
struct mutex mtx;
// 等待队列,用来保存对一个 epoll 实例调用 epoll_wait() 的所有进程。
// 当调用 epoll_wait 的进程发现没有就绪的事件需要处理时,就将当前进程添加到此队列中,然后进程睡眠;后续事件发生,就唤醒这个队列中的所有进程(也就是出现了惊群效应)
wait_queue_head_t wq;
// 当被监视的文件是一个 epoll 类型时,需要用这个等待队列来处理递归唤醒。
// epoll 也是一种文件类型,因此一个 epoll 类型的 fd 也是可以被其他 epoll 实例监视的。
// 而 epoll 类型的 fd 只会有“读就绪”的事件。当 epoll 所监视的非 epoll 类型文件有“读就绪”事件时,当前 epoll 也会进入“读就绪”状态。
// 因此如果一个 epoll 实例监视了另一个 epoll 就会出现递归。如 e2 监视了e1,e1 上有读就绪事件发生,e1 就会加入 e2 的 poll_wait 队列中。
wait_queue_head_t poll_wait;
// 就绪列表(双链表),产生了用户注册的 fd读写事件的 epi 链表。
struct list_head rdllist;
// 保护 rdllist 和 ovflist 。
rwlock_t lock;
/* RB tree root used to store monitored fd structs */
// 红黑树根结点,管理所有”关心“的 fd
struct rb_root_cached rbr;
// 单链表,当 rdllist 被锁定遍历向用户空间发送数据时,rdllist 不允许被修改,新触发的就绪 epitem 被 ovflist 串联起来,
// 等待 rdllist 被处理完了,重新将 ovflist 数据写入 rdllist
struct epitem *ovflist;
/* wakeup_source used when ep_scan_ready_list is running */
struct wakeup_source *ws;
/* The user that created the eventpoll descriptor */
// 创建 eventpoll 的用户结构信息。
struct user_struct *user;
// eventpoll 对应的文件结构,Linux 中一切皆文件,epoll 也是一个文件。
struct file *file;
/* used to optimize loop detection check */
u64 gen;
struct hlist_head refs;
};如上面 demo 中所示,
epitem
// 红黑树用于管理所有的要监视的文件描述符 fd。当我们向系统中添加一个 fd 时,就会对应地创建一个 epitem 结构体。
// epitem 可以添加到红黑树,也可以串联成就绪列表或其它列表。
struct epitem {
union {
/* RB tree node links this structure to the eventpoll RB tree */
// 所在的红黑树
struct rb_node rbn;
/* Used to free the struct epitem */
struct rcu_head rcu;
};
/* List header used to link this structure to the eventpoll ready list */
// 所在的 eventpoll 的就绪列表
struct list_head rdllink;
/* Works together "struct eventpoll"->ovflist in keeping the single linked chain of items. */
// 关联的 eventpoll 中的 ovflist
struct epitem *next;
/* The file descriptor information this item refers to */
// 为最开始的 fd 创建 epitem 时的文件描述符信息
struct epoll_filefd ffd;
/* List containing poll wait queues */
// poll 等待队列
struct eppoll_entry *pwqlist;
/* The "container" of this item */
// 所在的 eventpoll
struct eventpoll *ep;
/* List header used to link this item to the "struct file" items list */
struct hlist_node fllink;
/* wakeup_source used when EPOLLWAKEUP is set */
struct wakeup_source __rcu *ws;
/* The structure that describe the interested events and the source fd */
struct epoll_event event;
};
select 的缺陷
目前对于高并发的解决方案是 一个线程处理所有连接,在这一点上
select和epoll是一样的。但 当大量的并发连接存在、但短时间内只有少数活跃的连接时,select的表现就显得捉襟见肘了。首先,
select用在有活跃连接时,所以,在高并发的场景下select会被非常频繁地调用。当监听的连接以数万计的时候,每次返回的只是其中几百个活跃的连接,这本身就是一种性能的损失。所以内核中直接限定死了select可监听的文件句柄数:其次,内核中实现
select的方式是 轮询,即每次检测都会遍历所有的fd_set中的句柄,时间复杂度为O(n),与fd_set的长度呈线性关系,select要检测的句柄数越多就会越费时。下面这张图中所表达的信息中,当并发连接较小时,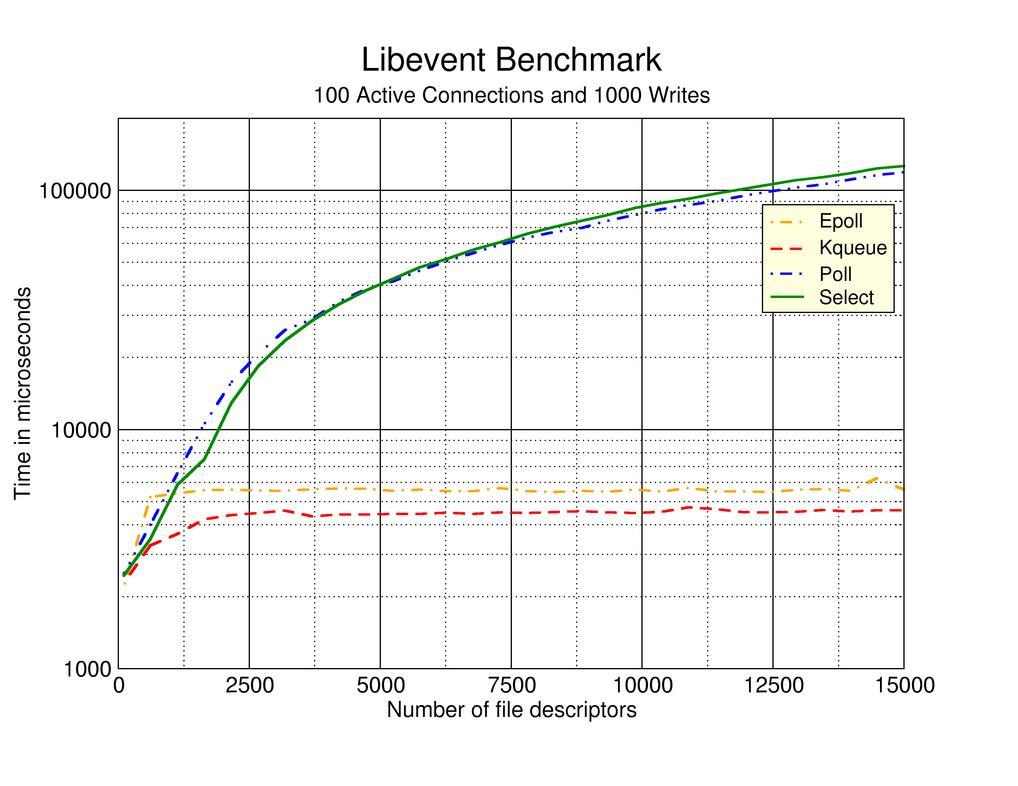
select和epoll差距非常小,当并发数逐渐变大时,select性能就显得非常乏力:需要注意的是,这个前提是 保持大量连接,但是只有少数活跃连接,如果活跃连接也特别多,那
epoll也会有性能问题。