 JemmyH
commented
3 years ago
JemmyH
commented
3 years ago 服务器线程模型
在高性能的网络 I/O 设计中,有两个著名的模型: Reactor模型 和 Proactor模型,前者用于 同步 I/O,后者用于 异步 I/O。有一点可以明确,不管是哪个模型,其目的都是提高服务端程序的并发能力。
对于支持多连接的服务器,一般情况下可以总结为 2种fd 和 3种事件:
 2种fd:
2种fd:
listen fd: 一般情况下只有一个,用来监听特定的端口,代表服务器程序;connect fd:每当客户端和服务器建立连接,就会产生一个connect fd,此后客户端的所有操作如收发数据都是通过这个connect fd。
3种事件:
listen fd进行Accept监听客户端的连接,创建新的connect fd;- 用户态/内核态 拷贝数据,每个
connect fd都有两个缓冲区read buffer和write buffer; - 处理
connect fd发来的数据,进行对应的逻辑处理后,将数据发送到对应的write buffer中。
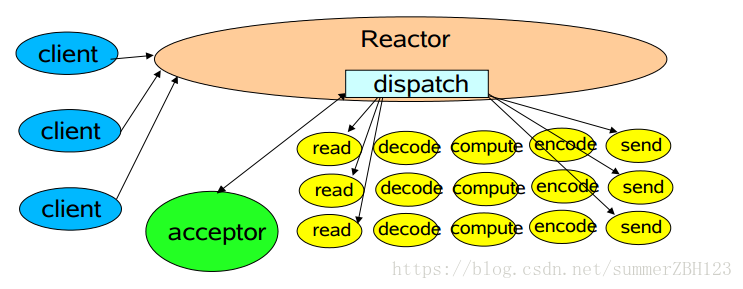
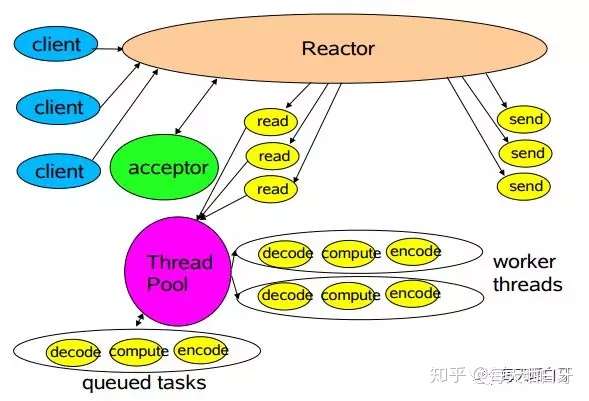


Reator 是一种事件处理模型,并发处理请求,然后对请求进行多路分解,并将它们同步分派给关联的请求处理程序。本 issue 旨在搞清楚此模型的运作方式、高效的原因 以及 有哪些对其进行的相关改进措施。