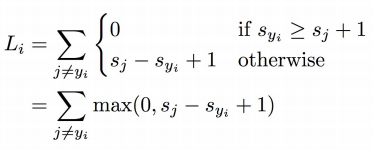JinwoongKim
commented
6 years ago
JinwoongKim
commented
6 years ago Stochastic Gradient Descent
def train(self, X, y, learning_rate=1e-3, reg=1e-5, num_iters=100,
batch_size=200, verbose=False):
....
# Sample batch_size elements from the training data and their
# corresponding labels to use in this round of gradient descent.
choices = np.random.choice(X.shape[0], batch_size)
#X_batch = np.take(X, choices)
#y_batch = np.take(y, choices)
X_batch = X[choices]
y_batch = y[choices]
# evaluate loss and gradient
loss, grad = self.loss(X_batch, y_batch, reg)
loss_history.append(loss)
# perform parameter update
# Update the weights using the gradient and the learning rate.
self.W += -(learning_rate * grad)
def predict(self, X):
"""
Use the trained weights of this linear classifier to predict labels for
data points.
Inputs:
- X: A numpy array of shape (N, D) containing training data; there are N
training samples each of dimension D.
Returns:
- y_pred: Predicted labels for the data in X. y_pred is a 1-dimensional
array of length N, and each element is an integer giving the predicted
class.
"""
y_pred = np.zeros(X.shape[0])
Store the predicted labels in y_pred. #
pred_scores = X@self.W
y_pred = np.argmax(pred_scores, axis=1)
return y_predprint out
print(pred_scores[0])
print(y_pred[0])[-1.52662675 0.06893752 -0.61177559 0.71873429 0.57737909 0.88258464
1.41015005 0.54151162 -1.50519876 -0.55446969]
6

svm_loss_naive
SVM loss function