 leonardtschora
commented
3 years ago
leonardtschora
commented
3 years ago So here is a workaround to solve this problem: I wrapped the models that need to share hyper-parameters into a composite model that also has the model's hyper-parameters. Then I redefined the update method of this wrapper so that everytime that the wrapper's hyper-parameter change, the sub models are also refitted.
Here is the Sub model:
mutable struct Sub <: Unsupervised
hp1::Int
end
function MLJ.fit(s::Sub, verbosity::Int, X)
fitresult = s.hp1
return fitresult, nothing, nothing
end
function MLJ.transform(s::Sub, fitresult, X)
return fitresult * X
endAnd there is the wrapper
mutable struct C <: UnsupervisedComposite
hp1::Int
end
function MLJ.fit(c::C, verbosity::Int, X)
Xs= source(X)
s1 = Sub(c.hp1)
m1 = machine(s1, Xs)
out1 = transform(m1, Xs)
s2 = Sub(c.hp1)
m2 = machine(s2, Xs)
out2 = transform(m2, Xs)
out = 0.5 * (out1 + out2)
fit!(out)
fitresult = out
cache = (s1=s1, s2=s2)
return fitresult, cache, nothing
end
function MLJ.transform(model::C, fitresult::Node, X)
return fitresult(X)
end
function MLJ.update(c::C, verbosity::Int, old_fitresult::Node, old_cache, X)
# c's hp1 has changed, need to update the submodel's hp1.
old_cache.s1.hp1 = c.hp1
old_cache.s2.hp1 = c.hp1
out = old_fitresult
fit!(out)
fitresult = out
cache = old_cache
return fitresult, cache, nothing
endThen, we can run the following piece of code:
c = C(2)
m = machine(c, X)
fit!(m)
transform(m, X)
c.hp1 = 3
fit!(m)The last call to fit!(m) gives
[ Info: Updating Machine{C4} @324. [ Info: Updating Machine{Sub} @269. [ Info: Updating Machine{Sub} @649. Machine{C4} @324 trained 2 times. args: 1: Source @955 ⏎
AbstractArray{ScientificTypes.Continuous,2}
Note that if we don't redefined update, then while calling fit! with a changed model, then the 2 submodels are not retrained.
Let me know what you think about this (I still think there should be other simpler ways to solve this problem, such as having a "double range" that force 2 hyper-parameters of the same model to have the same value, or maybe declaring submodels instantiation as nodes so that MLJ knows they have to be retrained because hyper-parameters have changed?) Thanks.
 OkonSamuel
OkonSamuel ablaom
ablaom
Hi everyone, as usual, thanks for helping me out on those issues!
I have 2 models that are NOT of the same type but they share common hyperparameters (not all of them, the set of shared hyperparameters is a subset of both sets of hyperparameters of both models).
As I understand it from Learning Networks
It is indeed possible to write
And both
ma1andma2will have to be retrained if one modifies hp1 or hp2, enabling an easy hyper-parameter search.However, my case is slightly more complex:
Note : It does not really matters what A and B are in terms of type of Models, they can be Unsupervised, Supervised, etc... The idea is that they are both used sequentially to produce an output, and I want to find the optimal set of hyper-parameters for this learning network.
Here is a summary of the situation: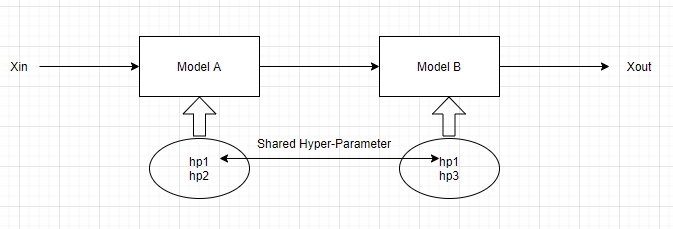
I migth have missed something to make this work easily, I am still new to MLJ. If it is currently not possible, my suggestion would be to allow to pass a list of hyperparameters to the
rangefunction. The idea would be to give the same values for different specified hyperparameters during tuning. The solution would then be:range(xout, [:(a.hp1), :(b.hp2)], ....)
If I did not make myself clear enough just let me know I'll try to explain iot better.
Thanks a lot for your help and support.