 KlausT
commented
6 years ago
KlausT
commented
6 years ago That's wierd. I would have expected at least 1080Ti speed, which is 60-65 or something. Did you manually set the intensity?
Open eruditej opened 6 years ago
KlausT
commented
6 years ago That's wierd. I would have expected at least 1080Ti speed, which is 60-65 or something. Did you manually set the intensity?
 eruditej
commented
6 years ago
eruditej
commented
6 years ago Tried your stock 8.17: avg 41MH/s Built one as well with the same results. Same results on your 8.16. Wondered if cuda9 was the issue, tried cuda8 builds, same results. Wondered if the changes for Titan cards were the culprit, went back to 8.15. Same results.
Default options only, no modifications to the code.
I am thinking it is maybe missing a match somewhere and doing too few threads in lyra2v2, I am reading the output from here: https://www.reddit.com/r/nvidia/comments/7iq5tk/just_got_a_titan_v_this_morning_ask_me_to/dr1y7x1/
So over a 1000 more cores than a 1080ti. Looking at code now to figure out if threads per block is getting underset due to something something __CUDA_ARCH__ 700 or something causing an issue.
Is there a way to see TPB at runtime printed out?
KlausT
commented
6 years ago You can actually see the threads per block in the code.
When you have a kernel call like this for example:
lyra2v2_gpu_hash_32_2 <<< grid4, block4, 0, gpustream[thr_id] >>> (threads);
then it's the block4 value (32 in this case).
Or you could add two lines of code to each kernel:
if(thread == 0)
printf("%d %d\n", blockDim.x, blockDim.y);In the lyra code, I wanted to make a quick bisection. I tried to force the 1080 code in lyra2v2.cu: /* #if __CUDA_ARCH__ >= 500 / then i commented out the corresponding else and modified lyra2v2_cpu_hash_32 accordingly.
It failed to build, there isn't any condition around #include cuda_lyra2v2_sm3.cuh that keeps it from not being included.
After I commented out the sm3.cuh header include, build succeeded with the forced >=500 code on.
So I suspect something is wonky in the macro processing and this has been defaulting to lower than 128 TPB for everything.
I tested the new binary, but still at 40MH/s, so this wasn't the issue. But I am still looking.
The ccminer_nanashi code results in i=19 default and 524288 threads at runtime for 99-100MH/s.
I am trying to find the printfs where that code displays that info and add that to my local build of klaust.
eruditej
commented
6 years ago after adding some applog code CUDA_SAFE_CALL(cudaMalloc(&d_hash2, 16ULL 4 4 sizeof(uint64_t) throughputmax)); CUDA_SAFE_CALL(cudaMalloc(&d_hash, 8ULL sizeof(uint32_t) throughputmax));
+/** Add diagnostic info like the other ccminer variants */
+applog(LOG_INFO, "%u cuda threads", thr_id, throughput);C:\miners\ccminer-817-cuda91-x64>ccminer.exe -a lyra2v2 --benchmark ccminer 8.17-KlausT (64bit) for nVidia GPUs Compiled with Visual Studio 2015 using Nvidia CUDA Toolkit 9.1
Based on pooler cpuminer 2.3.2 and the tpruvot@github fork CUDA support by Christian Buchner, Christian H. and DJM34 Includes optimizations implemented by sp-hash, klaust, tpruvot and tsiv.
[2017-12-22 17:55:02] NVML GPU monitoring enabled. [2017-12-22 17:55:02] 2 miner threads started, using 'lyra2v2' algorithm. [2017-12-22 17:55:02] 524288 cuda threads [2017-12-22 17:55:03] 524288 cuda threads [2017-12-22 17:55:03] GPU #1 Found nonce 804c4e29 [2017-12-22 17:55:03] GPU #1 Found nonce 8065d03e [2017-12-22 17:55:03] GPU #1: TITAN V, 41.24 MH/s [2017-12-22 17:55:03] Total: 41.24 MH/s
So, it says I have as many threads as the nanashi build, I'll have to keep poking.
KlausT
commented
6 years ago By the way, if you can figure out how to use the Nvidia Visual Profiler, then we can maybe find out which CUDA kernel is making problems, if any. With my GTX1070 it looks like this:
42.1% cubehash256_gpu_hash_32
35.7% lyra2v2_gpu_hash_32_2
7.2% blakekeccak256_gpu_hash_80
5.5% skein256_gpu_hash_32
4.7% lyra2v2_gpu_hash_32_1
2.8% lyra2v2_gpu_hash_32_3
1.8% bmw256_gpu_hash_32I fully merged this change into your code for cubehash256 https://github.com/Myrinia/ccminer/commit/9e1c1739d5d9d3fb6ff4dca76fdbeee0a9dcf047
Result: slightly faster (and cleaner) but still almost less than half as fast as tprot. Looking at the profiler but these tools are new to me.
So, by order of elimination, it isn't cubehash256
eruditej
commented
6 years ago I am still working on this, but this is all new code to me. Myrinia looks to be cleaning up the lyra2 (not v2) code with the same style used to clean cubehash. I'm still assuming that at half hash rates, it has to be something simple and easily overlooked. I started looking at the TBx/gpu_hash in lyra2v2. But none of my tests made a difference so far.
You go with 128 while tpru defaults to 32, but you calculate the _2 differently and you hard code 32 as the launch bound for _2. I tried redoing it his way, but it made no difference.
Everytime I try profiling I get out of memory errors, so I may have to take an hour to get used to the profiler.
That, or I may need to add more applog calls to see what is happening when/where.
I want a good clean codebase that was 9.1 clean (like yours) and builds in VS15/17 so I could test some Tensor core matrix math to see if sped up anything.
KlausT
commented
6 years ago There's also a command line profiling tool:
nvprof --timeout 60 D:\code\ccminer\Release\x64\ccminer -a lyra2v2 --benchmark
eruditej
commented
6 years ago ==7252== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 68.11% 38.9521s 4602 8.4642ms 8.4298ms 10.407ms lyra2v2_gpu_hash_32_2(unsigned int)
18.10% 10.3545s 9204 1.1250ms 1.1234ms 1.1280ms cubehash256_gpu_hash_32(unsigned int, unsigned
int, uint2*)
3.89% 2.22525s 4602 483.54us 482.76us 501.64us blakeKeccak256_gpu_hash_80(unsigned int, unsigned
int, unsigned int*)
2.63% 1.50461s 4602 326.95us 320.93us 336.16us skein256_gpu_hash_32(unsigned int, unsigned int,
unsigned __int64*)
2.44% 1.39550s 4602 303.24us 301.16us 307.30us lyra2v2_gpu_hash_32_1(unsigned int, uint2*)
2.43% 1.39045s 4716 294.83us 1.0560us 23.325ms [CUDA memcpy DtoH]
1.53% 876.38ms 4602 190.43us 180.29us 202.08us lyra2v2_gpu_hash_32_3(unsigned int, uint2*)
0.85% 488.74ms 4602 106.20us 103.84us 112.93us bmw256_gpu_hash_32(unsigned int, unsigned int, That gpu_hash32_2! I was close in my previous post just going through the bisection process.
eruditej
commented
6 years ago [2017-12-23 16:14:40] GPU #0 Found nonce 3b5436b7 [2017-12-23 16:14:40] GPU #0: TITAN V, 85.48 MH/s [2017-12-23 16:14:40] GPU #0 Found nonce 3d85beef [2017-12-23 16:14:40] GPU #0: TITAN V, 88.85 MH/s [2017-12-23 16:14:40] GPU #1 Found nonce c032dcf5 [2017-12-23 16:14:40] GPU #1: TITAN V, 91.23 MH/s [2017-12-23 16:14:40] Total: 178.68 MH/s
Closer! went from 88MH/s to 178.68.
Change: added this to lyra2v2_cpu_hash_32: cudaFuncSetAttribute(lyra2v2_gpu_hash_32_2, cudaFuncAttributePreferredSharedMemoryCarveout, 50);
ref: http://docs.nvidia.com/cuda/volta-tuning-guide/index.html#l1-cache ref2: http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#shared-memory-7-x
Need more testing, and setting it at 50 was just first try. No conditional code either to check for <sm_70
eruditej
commented
6 years ago [2017-12-23 16:26:58] GPU #0 Found nonce 2d0158f0 [2017-12-23 16:26:58] GPU #0: TITAN V, 99.20 MH/s [2017-12-23 16:26:58] GPU #0 Found nonce 2f40fff8 [2017-12-23 16:26:58] GPU #0: TITAN V, 99.89 MH/s [2017-12-23 16:26:58] GPU #1 Found nonce b00ddbf9 [2017-12-23 16:26:58] GPU #1: TITAN V, 100.83 MH/s [2017-12-23 16:26:58] Total: 196.27 MH/s
With the carveout set to 100, it is now on parity with ccminer2.2.3.
eruditej
commented
6 years ago at -i22: [2017-12-23 16:33:58] GPU #0 Found second nonce 1394a30e [2017-12-23 16:33:58] GPU #0 Found nonce 13b2563c [2017-12-23 16:33:58] GPU #0: TITAN V, 109.13 MH/s [2017-12-23 16:33:58] GPU #0 Found nonce 154b0036 [2017-12-23 16:33:58] GPU #0: TITAN V, 110.38 MH/s [2017-12-23 16:33:58] GPU #1 Found nonce 96746b65 [2017-12-23 16:33:58] GPU #1: TITAN V, 112.31 MH/s [2017-12-23 16:33:58] Total: 221.52 MH/s
wooooooooooooooo
KlausT
commented
6 years ago Nice. I have added the line. Would you like to test the binary? ccminer.zip
You are probably the only one using a Titan V, but you never know :-)
eruditej
commented
6 years ago Your ccminer is the only one really leveraging shared memory, and the volta is a shared memory speed beast.
Still doing some testing on my own.
probably needs to be wrapped in: if (cuda_arch[thr_id] >= 700)
KlausT
commented
6 years ago Looks like my 1070 doesn't care. I think I willl have to fix the cryptonight miner too, since there's shared memory too.
eruditej
commented
6 years ago Then this issue would be resolved.
eruditej
commented
6 years ago But since I was already in cubehash256:
__global__
void cubehash256_gpu_hash_32(uint32_t threads, uint32_t startNounce, uint2 *g_hash)
{
uint32_t index = blockIdx.x * blockDim.x + threadIdx.x;
uint32_t stride = blockDim.x * gridDim.x;
for (int thread = index; thread < threads; thread += stride)
{
uint2 Hash[4];
Hash[0] = __ldg(&g_hash[thread]);
Hash[1] = __ldg(&g_hash[thread + 1 * threads]);
Hash[2] = __ldg(&g_hash[thread + 2 * threads]);
Hash[3] = __ldg(&g_hash[thread + 3 * threads]);
uint32_t x[2][2][2][2][2] =
{
0xEA2BD4B4, 0xCCD6F29F, 0x63117E71, 0x35481EAE,
0x22512D5B, 0xE5D94E63, 0x7E624131, 0xF4CC12BE,
0xC2D0B696, 0x42AF2070, 0xD0720C35, 0x3361DA8C,
0x28CCECA4, 0x8EF8AD83, 0x4680AC00, 0x40E5FBAB,
0xD89041C3, 0x6107FBD5, 0x6C859D41, 0xF0B26679,
0x09392549, 0x5FA25603, 0x65C892FD, 0x93CB6285,
0x2AF2B5AE, 0x9E4B4E60, 0x774ABFDD, 0x85254725,
0x15815AEB, 0x4AB6AAD6, 0x9CDAF8AF, 0xD6032C0A
};
x[0][0][0][0][0] ^= Hash[0].x;
x[0][0][0][0][1] ^= Hash[0].y;
x[0][0][0][1][0] ^= Hash[1].x;
x[0][0][0][1][1] ^= Hash[1].y;
x[0][0][1][0][0] ^= Hash[2].x;
x[0][0][1][0][1] ^= Hash[2].y;
x[0][0][1][1][0] ^= Hash[3].x;
x[0][0][1][1][1] ^= Hash[3].y;
rrounds(x);
x[0][0][0][0][0] ^= 0x80U;
rrounds(x);
Final(x, (uint32_t*)Hash);
g_hash[thread] = Hash[0];
g_hash[1 * threads + thread] = Hash[1];
g_hash[2 * threads + thread] = Hash[2];
g_hash[3 * threads + thread] = Hash[3];
}
}
__host__
void cubehash256_cpu_hash_32(int thr_id, uint32_t threads, uint32_t startNounce, uint64_t *d_hash)
{
int blockSize;
int minGridSize;
int gridSize;
cudaOccupancyMaxPotentialBlockSize(&minGridSize, &blockSize,
(void*)cubehash256_gpu_hash_32, 0, threads);
gridSize = (threads + blockSize - 1) / blockSize;
cubehash256_gpu_hash_32<<<gridSize, blockSize, 0, gpustream[thr_id]>>>(threads, startNounce, (uint2*)d_hash);
CUDA_SAFE_CALL(cudaGetLastError());
if(opt_debug)
CUDA_SAFE_CALL(cudaDeviceSynchronize());
}ref: http://docs.nvidia.com/cuda/cuda-c-programming-guide/#occupancy-calculator
This is just a demonstration, for performance it is currently a no-op versus the hard coded values since they match. However, this gets rid of ugly invariants and makes the code more future-proof.
I had deleted the arch<500 code for troubleshooting, not for the purpose of this test. Here I just wanted to make sure our guesses about TPB/threads/etc were correct, and found that we were hard coding things cuda provides already.
Sadly, I was looking at the cuda9 feature cooperative groups and trying to figure out if it added anything, stumbled onto grid-stride (which this includes), and found : https://devblogs.nvidia.com/parallelforall/even-easier-introduction-cuda/
Then I realized none of this cubehash code looked like modern deterministic cuda.
 syoyo
commented
6 years ago
syoyo
commented
6 years ago You are probably the only one using a Titan V, but you never know :-)
I can also contribute testing on Titan V + Linux(I'm installing Titan V on Ubuntu 16.04)
I have tested cuda9 branch on Ubuntu 16.04 but faced this issue:
https://github.com/KlausT/ccminer/issues/84
(It sill works when I use --no-cpu-verify but hashrate is not good. 87 MH/s)
Also doing this
added this to lyra2v2_cpu_hash_32: cudaFuncSetAttribute(lyra2v2_gpu_hash_32_2,cudaFuncAttributePreferredSharedMemoryCarveout, 50);
resulted in wrong computation(shares rejected).
 Sephiroth4269
commented
6 years ago
Sephiroth4269
commented
6 years ago I am terribly sorry for this novice question, but I cannot get ccminer to work properly. I have downloaded it from github, and most of the locations didn't come with the ccminer.exe file, which is located in this thread. However even after doing so and moving a few other files around, it still doesn't launch any algorithm. I assume it has to do with there not being a "config" file, but I am not sure what it needs to look like or copying and pasting a similar file into that folder would work.
I have a Titan V as well, I am familiar enough with software and reading code, but this is clearly beyond my realm of knowledge. I am trying to maximize the usage of my Titan V but for instance lyra2z algorithm simply causes my computer to freeze, neoscrypt has high output as well but doesn't work when it's ccminer or NVIDIA based. What I am not understanding is why the "excavator" versions of those scripts are working, but none of the rest? I believe my issue lies in the solution you found in the ccminer.exe file you added in comments, which brings me to my first question: what am I doing wrong with the setup/installation?
KlausT
commented
6 years ago You are using Windows, right? Here is a version with the latest changes included: ccminer-820-Feb19-cuda91-x64.zip You can start mining neoscrypt like this:
ccminer.exe -a neoscrypt -i 18 -o stratum+tcp://hub.miningpoolhub.com:12012 -u username -p password
Replace the 18 with the highest value that still works.
Sephiroth4269
commented
6 years ago I am once again sorry for this novice question, you have already gone above and beyond what I would expect, or have hoped. I wrote start.bat file with that information, correctly changing username/password to the proper information, and it still didn't run. Is it a .cmd file, or what?
I keep getting a stratum error.

KlausT
commented
6 years ago Looks like username or password are not correct. What pool do you want to use?
Sephiroth4269
commented
6 years ago I think I figured it out. Now here's another question. I was using the multipoolhub algorithm and software. There are apparently different coins that can be "mined" using the same algorithm, as well as different iterations of the same algorithm: ccminer.nanashi, nvidia.nanashi for example.
According to the readout one is exponentially more valuable than the other. How does ccminer determine that?
Sephiroth4269
commented
6 years ago 
Alright I'm just lost now...this happened after I ran on neoscrypt...
KlausT
commented
6 years ago Something's wrong there. I don't know if it's my code, or your card. Maybe I will have to make one or two small changes.
Sephiroth4269
commented
6 years ago I'm not sure, what I am noticing is that tuning algorithms with the titan v doesn't seem to work at all. Whether I change threads, blocks, difficulty divider, etc. Not a DAMN thing changes...
I know the titan v is new technology, but with current mining scripts it is leaving a whole lot of power on the table. In theory older scyrpts using older CUDA makes it look like the titan v can do exponentially more than during its 9.1v.
There has to be a solution somewhere in the middle that is correct. im thinking the issues im having and mentioned in this thread are a result of underutilization of the cores...
Now another issue is that, on the same program it freezes on neoscrypt when lyra2z dips... What would cause my computer to freeze dyring mining? I never had this issue with nicehash2, and from what I can tell only with neoscrypt palgin.
KlausT
commented
6 years ago Would you please test if you are still getting validation errors with neoscrypt with this version? ccminer-820-Feb20-cuda91-x64.zip
on the same program it freezes on neoscrypt when lyra2z dips
What do you mean with this? Are you trying to run two mining programs at the same time?
Sephiroth4269
commented
6 years ago I am still getting the nonce error. I am not running two at a time what happens is the software determines the most profitable algorithm at the time and switches to it. I think I'm still struggling with the issue that the hash rates that the program says it gives, versus what the pool receives are way out of whack. Secondly it's to the point where Nice hash 2 won't even run daggermoto pascal algorithm...
I'm trying to find a reason to keep the Titan V but I keep having ridiculous issues that are way above my skill set to troubleshoot. The Titan V should be able to mine .001+ BTC worth of crypto a day. None of the current algorithms that "function" are doing so. I can use claymore and it works but my cards get really hot. Yet it doesn't work via minergate when I try and use that program? I'm a little lost as too the nature of my problems which seem to be solely compatibility issues.
What is the correct software, the correct algorithm, and correct settings for my Titan V to maximize it's usability in mining because so far I have hit a brick wall.
Sephiroth4269
commented
6 years ago  I'm thinking it could be the port in this particular instance, the mining pool port. Can you perhaps share with me a known correct mining pool address, I'll make an account if need be and see if that is the issue. Otherwise maybe Neoscrypt simply isn't compatible with titan V?
I'm thinking it could be the port in this particular instance, the mining pool port. Can you perhaps share with me a known correct mining pool address, I'll make an account if need be and see if that is the issue. Otherwise maybe Neoscrypt simply isn't compatible with titan V?
 kaos-1
commented
6 years ago
kaos-1
commented
6 years ago Titan V is very compatible it does 2.61 MH/s on Neo using excavator. IT is killing it on Neo
Sephiroth4269
commented
6 years ago 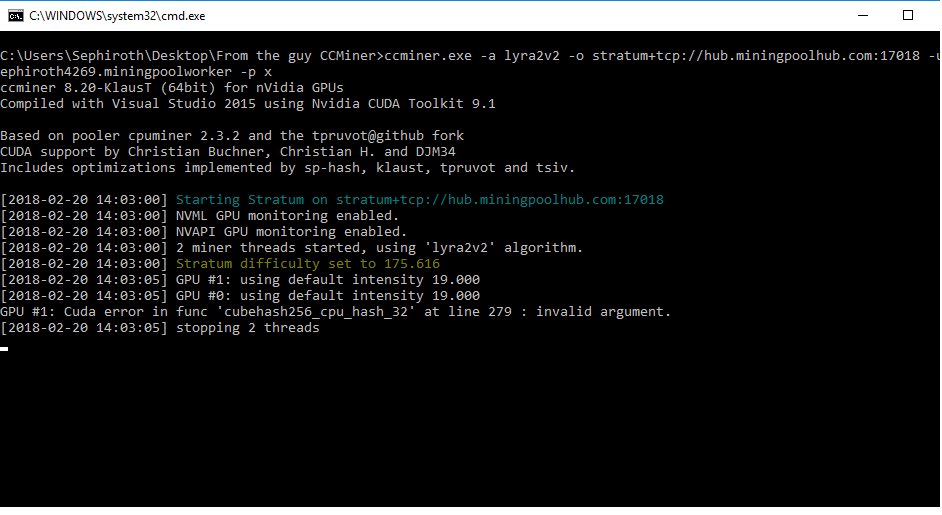
Then please tell me what I am doing wrong, and why I am having these issues. To your point, I was getting upwards of 3.5MH/s with neo, and lyra2z
 What mining pool are you using? Which software because I am getting nowhere with this.
What mining pool are you using? Which software because I am getting nowhere with this.
KlausT
commented
6 years ago Ok, one last try: ccminer-820-Feb20-lasttry-cuda91-x64.zip
What Nvidia driver version are you using?
Sephiroth4269
commented
6 years ago 
That's the latest driver. Your "last try" still gave me an error for the nonce. Meaning everything works fine except for the validation. I wrote the start.bat file for those 2 algorithms. Neither function properly. Am I not doing something correctly with the execution? I put both start.bat files in the folder you just linked.
start neoscrypt.zip start lyra2v2.zip
I'm beginning to think it has to do with the pool. The pools call for a different algorithm, although the lyra2v2 seems to be an option. Is there perhaps a conversion that needs to happen from lyra2v2 to lyra2re2?

Sephiroth4269
commented
6 years ago 
Ok it literally worked once so far! That's a start this is on Neoscrypt. Lyra2v2 which was the thread subject, still isn't functioning. I am trying to keep it thread relevant even if it doesnt seem that way haha
I'm hoping that by solving one algorithm it solves the others. Also if there is a mining pool specifically catered to lyra2v2 please point me in that direction! Perhaps that would be the primary issue?
KlausT
commented
6 years ago The validation problem has nothing to do with the pool. I'm out of ideas right now.
Sephiroth4269
commented
6 years ago What does the validation effect? would you be opposed to an email rather than this thread? Your solutions obviously worked it must either be something with the hardware, or the drivers? are you German by the way, it says you're based out of Germany?
Wen es ihnen hilft sie konnen es auch in Deutsch erklaren. Ich wil nur wissen warum meiner verdammter Titan V nicht perfekt operariert?!
KlausT
commented
6 years ago Yeah, I'm german.
When your Titan finds a share the CPU is checking if it is actually correct.
You could disable this with the option --no-cpu-verify
but this probably wouldn't solve the problem.
Sephiroth4269
commented
6 years ago Well that may be a roundabout solution to the neoscrypt issue. but do you have any ideas as to why my lyra2v2 isnt working? The person who started this thread saw numbers of 100MH after tweaking it a bit. I obviously dont have access or the knowledge to delve into the algorithm itself, but the issue I have with that particular algorithm is the fact that it won't even connect to the server in the first place which can be seen in above pictures. What would be causing that? it keeps saying invalid argument on line 279, and 280.
How can I fix that argument? what is that argument? does it have to with the pool or the algorithm?
Sephiroth4269
commented
6 years ago @eruditej Which mining pool are you using to get your numbers? I think that may very well be the issue I'm having...Considering I have been downloading and using the same zip files that have been shared in this thread the only other logical solution would be I'm aiming at the wrong mining pool?
eruditej
commented
6 years ago I use -i22 w/ lyra2rev2 and disable cpu validation with a flag.
Some of the algos may have hard coded launch bounds that run a titan V suboptimally but lyra2rev2 is set to glide stride and should perform well for you. I haven't looked much into the others because lyra2rev2 has been more profitable over a given week for the past X months.
As far as an algo is concerned, you can run as much as a 1080ti on your Titan V. The bottleneck is that all the int32 cores get used at the same time during cubehash/etc. You can't beat them up anymore than they already are and the code has been optimized to the point that they've unrolled all the loops by hand. You have just as many as a 1080.
The only way to make a Titan V do more is if you go learn how to do simple matrix compute using the fp32 units and tensor units and then add code yourself to co-process matrix transforms when the int32 registers are full.
So don't bug KlausT to do that for you.
There may be some speedup in converting some code to the unified memory architecture, but this only speeds up Linux and not Windows since Windows 10 took over GPU mem management.
On Tue, Feb 20, 2018 at 2:22 PM, Sephiroth4269 notifications@github.com wrote:
Well that may be a roundabout solution to the neoscrypt issue. but do you have any ideas as to why my lyra2v2 isnt working? The person who started this thread saw numbers of 100MH after tweaking it a bit. I obviously dont have access or the knowledge to delve into the algorithm itself, but the issue I have with that particular algorithm is the fact that it won't even connect to the server in the first place which can be seen in above pictures. What would be causing that? it keeps saying invalid argument on line 279, and 280.
How can I fix that argument? what is that argument? does it have to with the pool or the algorithm?
— You are receiving this because you authored the thread. Reply to this email directly, view it on GitHub https://github.com/KlausT/ccminer/issues/101#issuecomment-367105591, or mute the thread https://github.com/notifications/unsubscribe-auth/AhKu4F6JyMtrnjXGu18kpCHbRlBAXwkTks5tWyhrgaJpZM4RLYj1 .
KlausT
commented
6 years ago The error you get when you try lyra2v2, is it always GPU#1 ?
That's your 780Ti, right?
What error message do you get when you add the option --debug ?
Sephiroth4269
commented
6 years ago I haven't tried the debug yet, or turning off the CPU validation as I wasn't aware of them, or what their effects would be regardless. I will test that out tonight when I get back from work and send a screen shot! @KlausT you have been a phenomenal help throughout all of this and I really do appreciate it. I'm sorry if it feels like I'm trying to get you to reinvent the wheel for me that isn't my intention, I am solely trying to get my hardware to work with your software.
@eruditej I would be very interested in having that conversation with you, on how to write algorithm script. I've been beating my head against the wall with the CUDA parameters, mostly because I have no idea where to start. All of the tutorials are written for advanced users (obviously), but if I can get a direction to a good starting place, which folder, which file, which editing software, etc. I think I could play around with it easily enough.
I've also noticed that when I run lyra2rev2 it crashed on the ccminer, so I looked up the other algorithms that were supported and that specific string was not anywhere to be found. That being said, I could be mistaken, or perhaps I was looking at the wrong one. That also being said I will try using that in place of the string: lyra2v2 and see what that results as.
Unfortunately I work nights so that may take a while. So far though I believe we have ruled out: Titan V, drivers, "tuning", mining pools, and the ccminer itself. The only variables left are: cpu, debug, other things I know nothing about?
Sephiroth4269
commented
6 years ago 
So the issue was that my other graphics card was causing it too fail haha.....sorry for the mess...
Sephiroth4269
commented
6 years ago @eruditej @KlausT Food for thought. I was using Multipoolminer for my mining and then I started experimenting with different .exe files, versus algorithms, and I cam across this:

Fir the record I have no idea how or why this is possible. I am using the "nanashi" .exe version of lyra2z mining and for whatever reason the 780ti is leaps and bounds better than the Titan V in this instance. This brings me to my question. These hashrates are real. They are clearly being calculated and felt by the miner. How do we translate that into received nonces and shares?
I am unsure what the issue is exactly. tpruvot 2.2.3 gives me twice the hashrate of klaust even though you are building sm_70 w/ cuda 9.1
using the latest drivers, tpruvot gives me about 90-100 MH/s klaust gives me 40-42 MH/s
The skew is so large, im suspecting something simple around the profile of the card specific code.
Also, thank you for making your code so much cleaner. I can actually load it in VS and build vs tpru where I have to redo the entire compat system to make it build on anything newer than VS13.