 jeremyjpj0916
commented
5 years ago
jeremyjpj0916
commented
5 years ago We were able to reproduce again with predictability.
6 Worker processes too do note.
-
Start heavy 100+ TPS load test on a given route path on your gateway, monitor the status codes coming off of it(use the termination plugin make it throw a 200 success or what have you to get high throughput to the Kong node).
-
We already have a decent number of services and routes already in place on our gateway so understand we are making a new service and route where 130+ are already existing. But create a new service and route pair during that load test.
-
Watch as the route taking the load at that instance in time will throw 404's from a certain # of worker processes. Use the correlation id plugin globally to get those worker as uuid#counter and you will generally see some % of worker processes seemed to have managed to rebuild router while under that specific load just fine, the other worker processes throw the Kong 404 no route available error during that window on the route under load.
What does this mean? I believe Kong needs to implement router rebuild mutex in place so as Kong figures out changes to routes it has a temp cache to leverage of all the "existing" routes during the window of rebuild(I think @p0pr0ck5 implemented a mutex like this around Service resource create/updates/deletes for Kong 1.0 ).
Some interesting thoughts trailing off on this though as well. IF it was just the instance in time of rebuild that had issue why did we see existing routes like our /F5/status endpoint persist the 404 no route found error with certain worker processes? Maybe a timing thing or Kong invalidly caches that bad "miss" as a truth and continues to persist that miss even if its present in the db? I am not sure, but I believe the mutex lock would probably stop that from happening anyways.
Let us know if we can provide you any further help but I think Kong will be able to reproduce at this point!
UPDATE: Was told in gitter chat that 1.0RC3 has the router mutex in place. Will see if that resolves the described issues here.
 p0pr0ck5
p0pr0ck5


 bungle
bungle thibaultcha
thibaultcha

 rsbrisci
rsbrisci
Summary
We have noticed in our Kong Gateway nodes times when common endpoints the gateway exposes throwing 404 route not found on a % of API calls. The specific proxy we focused on with this post( "/F5/status") does not route, has no auth, and serves as a ping up time endpoint that returns static 200 success. We do notice this as well on other endpoints that have auth and plugins as well, but the frequency in which our ping endpoint gets consumed is consistent and provides the best insight.
Steps To Reproduce
Reproducing consistently seems impossible from our perspective at this time, but we will elaborate with as much detail and screenshots as we can.
Create combination of services and resources 1 to 1. We see 130 service route pairs. 300 plugins. Some global, some applied directly to routes(acl/auth).
Add additional services + routes pairs with standard plugins over extended time.
Suspicion is eventually the 404's will reveal themselves, and we have a high degree of confidence it does not happen globally across all worker processes.
New arbitrary Service+Route was made on the Gateway, specific important to note is created timestamp:
Converted to UTC:
Above time matches identically with when the existing "/F5/status" began throwing 404 route not found errors:
You can see a direct correlation to when that new service+route pair was created to when the gateway began to throw 404 not found errors on a route that exists and previously had no problems. Note the "/F5/status" endpoint takes consistent traffic at all time from health check monitors.
Interesting bit its the % of errors to this individual Kong Node, we run 6 worker processes and the error rate % is almost perfect for 1 worker process showing impact: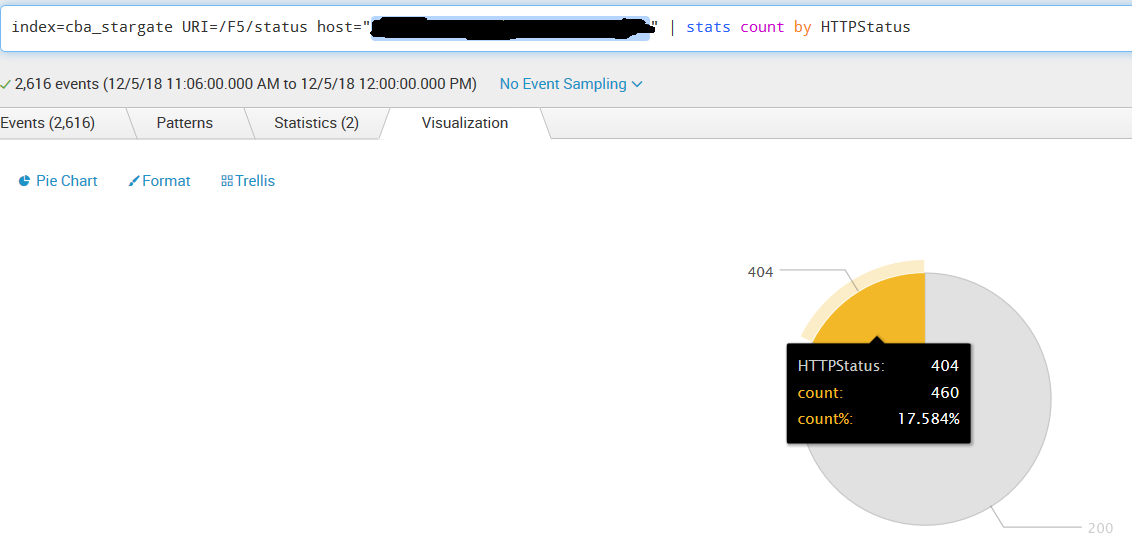
To discuss our architecture we run Kong with Cassandra 3.X in 2 datacenters, 1 Kong node per data center. We run a 6 node Cassandra cluster, 3 C* nodes per datacenter. The errors only occurred in a single datacenter on the Kong node in our examples above, but both datacenters share identical settings. We redeploy Kong on a weekly basis every Monday early AM, but this error presented above Started on a Wednesday so we can't correlate the problem to any sort of Kong startup issue.
To us the behavior points to cache rebuilding during new resource creation based on what we can correlate. Sadly nothing in Kong logging catches anything of interest when we notice issue presenting itself. Also note it does not happen every time obviously so its a very hard issue to nail down.
We also notice the issue correcting itself too at times, we have not traced the correction to anything specific just yet, but I assume very likely its when further services and routes are created after the errors are occurring and what seems to be a problematic worker process has its router cleaned up again.
Other points I can make are that production has not seen this issue with identical Kong configurations and architecture. But production has fewer proxies and has new services or routes added at a much lower frequency(1-2 per week vs 20+ in non-prod).
I wonder at this time if it may be also safer for us to switch cache TTL back from the 0 infinity value to some arbitrary number of hours to force cycle on the resources. I suppose if it is indeed the cache as we suspect that that would actually make the frequency of this issue more prevalent possibly though.
I may write a Kong health script that just arbitrarily grabs all routes on the gateway and calls each 1 one by 1 to ensure they don't return a 404 as a sanity check to run daily too right now. My biggest fear is as production grows in size and/or higher frequency in services/routes created daily we may begin to see the issue present itself there as well and that would cause dramatic impact to existing priority services if they start to 404 respond due to Kong not recognizing the proxy route exists in the db and caching appropriately.
Sorry I could not provide a 100% reproducible scenario for this situation, can only go off the analytics we have. Although if it yields some underlying bug in how Kong currently manages services and routes, that would bring huge stability to the core product.
Additional Details & Logs
Kong version 0.14.1
Kong error logs - Kong Error logs reveal nothing about the 404 not found's from Kong's perspetive. Nothing gets logged during these events in terms of normal or debug execution.
Kong configuration (the output of a GET request to Kong's Admin port - see https://docs.konghq.com/latest/admin-api/#retrieve-node-information)