 dubslow
commented
6 years ago
dubslow
commented
6 years ago From @Tilps on May 8, 2018 9:51
https://lichess.org/e07JvP6g - I started analyzing this - the position after the blunder has a 0.11% policy for a move which is checkmate. Takes 20k visits to get its first look and then it obviously gets every visit. I haven't tested how that varies with noise applied.


 Screenshot 2 shows Analysis by ID288 in Arena on my machine:
Screenshot 2 shows Analysis by ID288 in Arena on my machine:
 Screenshot 3 shows Analysis by ID94 in Arena on my machine (Rc7 not listed):
Screenshot 3 shows Analysis by ID94 in Arena on my machine (Rc7 not listed): Configuration: CCLS Gauntlet
Network ID: 288
Time control: 1 min + 1 sec (increment)
Comment: Game was streamed on May 14th 2018.
Configuration: CCLS Gauntlet
Network ID: 288
Time control: 1 min + 1 sec (increment)
Comment: Game was streamed on May 14th 2018.  Screenshot 2 shows Analysis by ID288 in Arena on my machine:
Screenshot 2 shows Analysis by ID288 in Arena on my machine:
 Screenshot 3 shows Analysis by ID94 in Arena on my machine (Ra6 not listed):
Screenshot 3 shows Analysis by ID94 in Arena on my machine (Ra6 not listed):
 Configuration: CCLS Gauntlet
Network ID: 288
Time control: 1 min + 1 sec (increment)
Comment: Game was streamed on May 14th 2018.
Configuration: CCLS Gauntlet
Network ID: 288
Time control: 1 min + 1 sec (increment)
Comment: Game was streamed on May 14th 2018.  Configuration: CCLS Gauntlet
Network ID: 288
Time control: 1 min + 1 sec (increment)
Comment: Game was streamed on May 14th 2018.
Configuration: CCLS Gauntlet
Network ID: 288
Time control: 1 min + 1 sec (increment)
Comment: Game was streamed on May 14th 2018.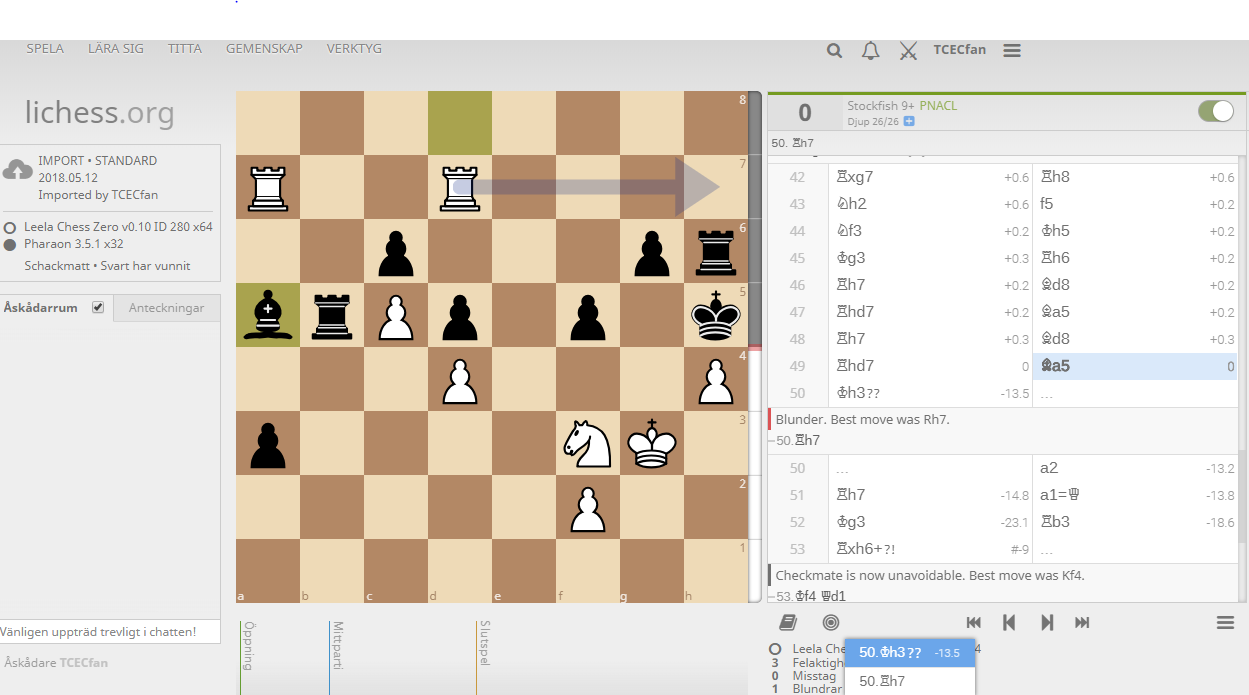 Stockfish 9 gives Rh7 as the only move
Stockfish 9 gives Rh7 as the only move
 Configuration: CCLS Gauntlet
Network ID: 280
Time control: 1 min + 1 sec (increment)
Comment: Does Leela handle 3-fold repetition correctly?
Configuration: CCLS Gauntlet
Network ID: 280
Time control: 1 min + 1 sec (increment)
Comment: Does Leela handle 3-fold repetition correctly?
 ASilver
ASilver The 50-move counter reset here means that it will be in effect on move 182 (move 50). Clearly a draw here, as black has pawn and can exchange bishop any day for white's piece. But then on move 179.... It gives up its bishop for NO reason at all, and instantly loses:
The 50-move counter reset here means that it will be in effect on move 182 (move 50). Clearly a draw here, as black has pawn and can exchange bishop any day for white's piece. But then on move 179.... It gives up its bishop for NO reason at all, and instantly loses:
From @mooskagh on May 8, 2018 7:23
Important!
When reporting positions to analyze, please use the following form. It makes it easier to see what's problematic with the position:
lc0/lczeroversion, operating system, and non-default parameters (number of threads, batch size, fpu reduction, etc).(old text below)
There are many reports on forums asking about blunders, and the answers so far had been something along the lines "it's fine, it will learn eventually, we don't know exactly why it happens".
I think at this point it makes sense to actually look into them to confirm that there no some blind spots in training. For that we need to:
--temperature=1.0 --noise)" to see how training data would look like for this position.Eventually all of this would be nice to have as a single command, but we can start manually.
For
lc0, that can be done this way:--verbose-move-stats -t 1 --minibatch-size=1 --no-smart-pruning(unless you want to debug specifically with other settings).Then run UCI interface, do command:
(PGN move to UCI notation can be converted using
pgn-extract -Wuci)Then do:
see results, add some more nodes by running:
And look how counters change.
Counters:
Help wanted:
Copied from original issue: glinscott/leela-chess#558