 famoreno
commented
7 years ago
famoreno
commented
7 years ago I agree with @jlblancoc. There is no need for a PR, I'll use your fork.
Closed jlblancoc closed 7 years ago
famoreno
commented
7 years ago I agree with @jlblancoc. There is no need for a PR, I'll use your fork.
 raghavendersahdev
commented
7 years ago
raghavendersahdev
commented
7 years ago Thanks @jlblancoc @famoreno . I will commit code for some of the opencv wrappers in CFeatureExtraction and fill in the evaluation tonight !
raghavendersahdev
commented
7 years ago Hi @famoreno I have added the AKAZE detector and the LSD line detector, I will add the LATCH and BSD Descriptor by June 30. Will try to finish week 5 stuff over the weekend. I made changes to the files CFeatureExtraction.h, CFeature.h, types.h, CFeatureExtraction_common.cpp, CFeature.cpp and added CFeatureExtraction_LSD.cpp and CFeatureExtraction_AKAZE.cpp
raghavendersahdev
commented
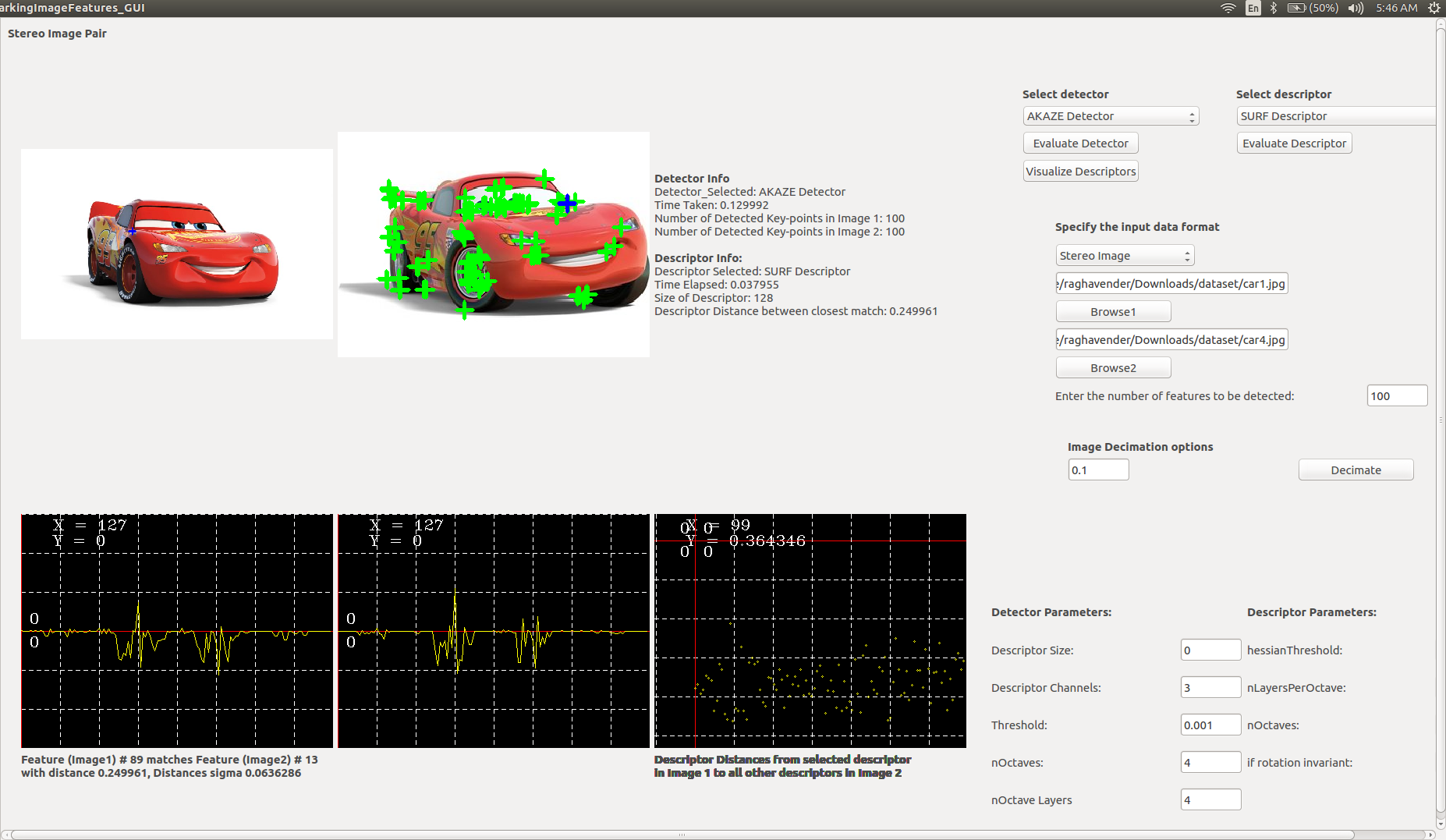
7 years ago Hi @famoreno, I commented the code for each of function headers, I will add more comments within function, about global variables and clean up the code in the following weeks. current output of the app looks like this. I had a few questions about the evaluation metrics:
Regarding the vision tasks to be evaluated using the detector/descriptor combination, I am currently thinking of evaluating on 3 tasks
I wanted to finish 2 of these tasks before the second evaluation (would that be fine?). then as per time-line I can do the one remaining vision task in week 9 and 2 weeks for building the ROS package which can playback MRPT datasets and final week for wrap-up, documentation, etc.
raghavendersahdev
commented
7 years ago Alternatively to keep things simple can I use this for monocular VO and extend it for different detectors/descriptors for the app...
famoreno
commented
7 years ago Hi @raghavendersahdev. Sorry for the delay in the answer! Just some thoughts about the first part of your post:
DETECTORS: repeatability of detectors: how should I evaluate this, I understand repeatability is the ability to detect key-points at the same location in the image under different conditions (view point changes, illumination changes, etc.)
For this metric, the app could provide two different options:
p_(i+1) = H_i*p_i, where p_i are the point coordinates in frame i and H_i is the homography matrix between frame i and i+1 (refer to this for more information about homographies). The app could provide an option for the user to use a text file containing an homography per line.Dispersion of Image: for detector evaluation, could you point me to what dispersion means w.r.t. detectors. I could not exactly understand this.
This is just the standard deviation of the keypoints coordinates (u,v) on the image.
DESCRIPTORS: % of matches: do I simply use a distance-thresholding based approach to find out how many of the descriptors in image1 are successfully matched to those in image2.. Like if the distance between 2 descriptors is less than a particular threshold I call it a successful match else not successful.... so % of matches = successful number of descriptor matches / (total number of key-points in image 1) * 100
In general, for matching, a match is successful if the descriptor distance is below a certain threshold AND the distance to the second closest descriptor is over another threshold (i.e. the keypoints are similar enough and they are distinctive enough). Then, this metric is exactly as you suggest: % of matches = successful number of descriptor matches / (total number of key-points in image 1) * 100
false positives/ negatives: I am currently thinking to use some kind of spatial information like key-point (332,221) of image1 should be around the region (332+/-50, 221+-50) in image2, if its not in this area, I call it an incorrect detection / False positive.....else correct match. Does this sound correct?
For this case, I was thinking again in the homography approach. If the match is found outside a small area where it should be according to the homography, it is called a false positive. For the false negatives, if a keypoint in image1 should be matched to a certain keypoint in image2 according to the homography AND actually there is a keypoint in that position but the match is not found, then it's a false negative.
And regarding the vision tasks, let me think more in depth about the best options and I'll come back to you in the next days. In the meantime, keep working on the rest!
All the best!
raghavendersahdev
commented
7 years ago Thanks Paco for clarifying this. Your suggestions help :). I will find a dataset (possibly a tracking dataset where homographies/transformations are known for all subsequent frames- maybe in the form of ground truth) and evaluate the app on the dataset. I will provide the user option to use existing homography or compute homography using something like this between consecutive frames.
raghavendersahdev
commented
7 years ago Hi @famoreno I have a clear idea for the evaluation metrics and have the structure in place in the code, I need to fix some parts (for evaluation) (I need internet for this, didnt expect this). Unfortunately I do not have access to good proper internet as I am currectly attending Computer Vision Summer School, ICVSS 2017 in Sicily, Italy, I want to finish upto week 7 goals by July 18 (Week 7 end). I will be back and have access to good internet on July 16th. Could you let me know about VO so I can start developing code about the structure for the vision tasks.. and fix the missing parts when I get good internet access.
famoreno
commented
7 years ago Hi @raghavendersahdev, after talking to the org admins, we've decided that it's better to keep it as simple as possible, so adapting this to accept some detectors/descriptors should be more than enough (we don't want the MRPT codebase to grow too much, it's already kinda huge!).
Enjoy the Summer School!
raghavendersahdev
commented
7 years ago Thanks will stick to the monocular version !
raghavendersahdev
commented
7 years ago Hi @famoreno some updates on my progress:
Week 5-6: Evaluation metrics - I have finished the evaluation metrics (repeatibility, % of matches, false positives/negatives, dispersion, etc.). Sample output can be seen here, here and here . Currently I only have a simple approach for repeatability based on a spatial threshold (say 3 pixels). I need to do the homography based approach for the repeatability metric. Could you point me to some dataset which already has the homographies in the successive frames in a text file? For the false/positives I think having a simple spatial search of the keypoints should be enough rather than using homography for this as this is just for a stereo image pair so we might not need homography here. Currently I have a simple spatial search approach which works fine. what would be your thoughts here?
Week 7: Visual Odomoetry - I have finished displaying of visual Odometry, a sample output of the result can be seen here. Does this look fine? Currently the user can select any detector (and corresponding parameters for the detector). The monocular visual odometry works based on tracking the key-points detected from the selected detector. I adapted this code to work with other detectors. I will also display the odometry error next to the odometry plot so one can see which detectors give minimum error, I have it calculated using something like this . Need to double check this to make sure if its correct. I am currently doing (length of the ground truth path - length of the predicted path) / length of ground truth path * 100. However this might be wrong I will double check this. I will remove some minor bugs too in the next few days.
Next Steps:
Week 8: July 19-25. (Tracking vision task, documentation, code clean-up and tutorial) I am thinking of finishing the tracking part in the next 2 days and then focusing on cleaning up the code, documentation, fixing bugs, testing the app and writing a tutorial to use the app as required in the evaluation guidelines for the second evaluation. Please let me know if this would be fine (meeting the goals upto week 8 for 2nd evaluation ). I was thinking to finish the week 8 goals for the evaluation before July 26th. Would that be fine?
So week 9 would be the 3rd vision task (Place recognition), week 10/11: the second mini project of playing back MRPT datasets in ROS and last week 12 for pilling up the work and documentation,etc.
 feroze
commented
7 years ago
feroze
commented
7 years ago Hi @raghavendersahdev
The "Image Matching: Graffiti" dataset in http://kahlan.eps.surrey.ac.uk/featurespace/web/data.htm has the homography ground truths in the files inside each folder. Would that work?
Nice work with the VO!
raghavendersahdev
commented
7 years ago Hi @feroze thanks, yes the "Image Matching: Grafifiti" dataset should work! Will finish the repeatability using this dataset, fix the odometry error displaying part and move on to the tracking task.
famoreno
commented
7 years ago Hi @raghavendersahdev, I see a lot of work here, good job!
The Graffiti dataset is a classic :P and it is perfect for the evaluation, thanks @feroze for pointing it out. I'll have a look to the code during this weekend and give you some feedback about it.
For the false/positives I think having a simple spatial search of the keypoints should be enough rather than using homography for this as this is just for a stereo image pair so we might not need homography here. Currently I have a simple spatial search approach which works fine. what would be your thoughts here?
It's ok for me. All the best
raghavendersahdev
commented
7 years ago Thanks @famoreno I will try to clean up and comment the code before Friday midnight in that case :+1:
raghavendersahdev
commented
7 years ago Hi @famoreno few updates:
I have finished the homography based repeatability task and the tracking vision task is currently under construction, I am tracking key-points in successive frames based on the detector selected. The key-points are matched with the best patch based on the SSD metric currently something like this. When the user clicks on the check box Activate Tracking of Key-Points a button appears saying trackIt clicking on that button will track the key-points in subsequent frames. (currently this part is under construction, code gives incorrect tracking results (need to fix this)).
Tracking and VO currently only works for monocular datasets.
Pending things before evaluation (July 26)
Please let me know if I am missing anything else for evaluation.
raghavendersahdev
commented
7 years ago Hi @famoreno few more updates:
I have finished implementing the tracking vision task, sample output can be seen here it asks the user for some parameters for the tracker, when the user checks the Activate Tracking of Key-Points all the tracker-parameters become visible, if unchecked parameters are hidden from the view. The user can keep pressing the Track Key-Points button to track key-points in subsequent frames.
Similar thing is done for the Visual Odometry and activating homography based repeatability also (using checkboxes). A sample for Visual odometry is this. Need to display a label next to it, will do it in the next commit. Could you let me know how to compute VO error in %, I have the ground truth points (x[],y[]) and the predicted (X[],Y[]), I am currently doing something like this summation sqrt{(X[i]-x[i])^2 + (Y[i]-y[i])} / total path length *100 % . However this might be wrong. Any insights @feroze @famoreno ?
Pending work before evaluation (July 26):
I will do these before July 26. Targets upto and including week 8 should be in good shape as per the time line.
famoreno
commented
7 years ago Hi, @raghavendersahdev. I've been testing the code and here are my thoughts:
Operation issues
 which can't be moved, zoomed, rotated, etc. Besides, letters can't be read properly.
which can't be moved, zoomed, rotated, etc. Besides, letters can't be read properly.GUI issues


General comments
- Tutorial File
as its use is not quite intuitive.
Input: Single image dataset; KLT detector; SURF descriptor; Click on Evaluate Detector; Click on Evaluate Descriptor; Click on Visualize Descriptor; Click on one KeyPoint (KP) Expected result: See the descriptor of the KP Result: the program computes KLT in all frames in the dataset and computes "Repeatability" for the KP although the highlighted KP is not the one clicked but a random one.
raghavendersahdev
commented
7 years ago Hi @famoreno thanks for the suggestions:
- It seems that if the dataset is grayscale the app crashes when loading the images with opencv.
Yes currently the app only supports color images. Need to add cases everywhere for grayscale images too. Will do in the next commit.
- I can't make the visual odometry to work with the KITTI-7 dataset when no ground truth is provided (the use of a groundtruth file shouldn't be mandatory).
as its a monocular VO problem we need a scale to plot the path for which ground truth would be needed.
- While the app is computing VO there is no feedback to the user about that something is happening (e.g. processing X out Y frames, ...). Instead, the app freezes for a minute until it finishes. BTW, when computed with KITTI7 and ground truth, the final map is:
I will fix this by trying to update the output VO image in real-time on the fly and/or add a label (X out of N files processed) which is updated in real time. there are camera parameters which need to be changed for each KITTI sequence, I will here do this in my next commit. Also I will start the trajectory (predicted / ground truth) from a point a little lower in the image, I only tested on one of the KITTI sequence so didn't know how it would look in others. I will test on all 11 sequences and make the most appropriate starting point for the trajectory.
- I can't select a rawlog file to be processed. It looks for a directory instead of a .rawlog file.
.rawlog format is not currently supported, I wanted to ask do we actually need this? . can I address this before the start (week 10) of second mini project in week 9 end.
- If MRPT has been compiled without SIFT support, the app shouldn't let the user to select that option as the app crashes if it selected.
SIFT was actually working perfectly for a long time till week 4/5 but then suddenly when I re-compiled mrpt at one point, it stopped functioning. I thought if another user installed on a different machine, by default mrpt should have been compiled with SIFT support. I will add a QMessage box saying "SIFT option cannot be selected : mrpt compiled without SIFT support"
- After clicking Evaluate Detector, every click on Next of Previous should already detect KeyPoints (KPs) without having to click again on Evaluate Detector.
I will do this in the next commit.
- Remove the BCD option as it is not actually implemented in the MRPT library. The app randomly crashes after clicking.
sure will remove BCD, I was expecting to do this at some point, thanks.
- In general when I click on the image to select a KP, the highlighted one is completely different to the one I selected (or at least intended to).
I will fix this issue, I think its because I resize the QImage before putting onto the QLabel, but am checking clicks before that. will figure this out and fix.
- Put the Detector info in a different place so that images can be enlarged. It makes no sense that, in a app for evaluating image features, the images actually fill only 1/4 of the screen. As a side effect of the images appearing quite small, the keypoints are not noticeable enough. E.g.
I agree, I will enlarge the images to make the key-points more noticeable.
- When one keypoint in image 1 is clicked, the rest dissapear and I can't find the way to show them again to select a different one.
I will always display all key-points and color the one selected with a different color
- When a new input is selected, clear the previous graphs.
will fix this whenever the user selects a new detector/descriptor or changes dataset file_path, the previous descriptor graphs would be cleared.
- If KLT is the default detector (for instance) when the app starts, its parameters should already appears in the Detector Parameters area.
I agree my mistake, I will fix this, should be straight forward
- Maybe a status bar that guides the user through the steps to achieve what he wants would be really useful.
this sounds a bit tricky, how about I have a text Area which shows what all the user has done till now? like
- In Tracking Points -> Activate/Deactivate options should be checkboxes and not textedits.
I agree, again my mistake, will fix this.
- Sometimes the distance graph is empty and "Distances sigma" is -nan:
I will find why this is happening and fix it.
- I don't really know how to use the program to replicate your results. Could you upload a video recording your screen while using the program? I'm really looking forward to the
I will upload a video file tonight to show how I used the app to replicate the results I got, I will upload a tutorial file also in the next commit.
raghavendersahdev
commented
7 years ago Hi @famoreno actually with regards to ground truth for KITTI, since its a monocular dataset, it is impossible to estimate the actual scale of translation from monocular VO alone, since it cannot distinguish between solutions like (x,y,z) and (cx,cy,cz). What this line does is that it obtains the absolute scale from an external source: the ground truth in this case. In practice, this could come from another sensor like a speedometer (KITTI doesn't have this). The files 00,01,02,03,....txt files are essentially the ground truth data for trajectory # 0,# 1,# 2,# 3, etc... in the KITTI dataset. Maybe I can upload these text files if required in the project.
famoreno
commented
7 years ago Hi again! Some more comments about this:
Yes currently the app only supports color images. Need to add cases everywhere for grayscale images too. Will do in the next commit.
I think that you only need to check that the image is not already in grayscale before converting it.
.rawlog format is not currently supported, I wanted to ask do we actually need this?
I think that opening .rawlog files should be an option of the input (single image, stereo image, single image folder, stereo image folders and rawlog files -- which indeed may contain images or stereo images), unless the orgs says otherwise.
this sounds a bit tricky, how about I have a text Area which shows what all the user has done till now? like
evaluated image so and so with detector and descriptor performed visual odometry on the dataset performed tracking on the dataset...... ..... A status bar would imply I need to know the users initial intent, which could be anything.
Not only a bit tricky but a lot! Ironically I was completely misleading here :P, sorry about that! What I wanted to say is that many of the options are always available even though they can't be used (which may lead to crashes). For example, if the input format is Single (or Stereo) Image, options for Visual Odometry, Repeatability and Tracking should not be elegible. The same with Decimation. It is just a way to avoid undesired/undefined behaviour of the app.
Also I will start the trajectory (predicted / ground truth) from a point a little lower in the image, I only tested on one of the KITTI sequence so didn't know how it would look in others. I will test on all 11 sequences and make the most appropriate starting point for the trajectory.
Maybe it's a good idea to compute the complete camera trajectory, then determine its "bounding box" and, after that, show the trajectory accordingly fitting it to the image.
actually with regards to ground truth for KITTI, since its a monocular dataset, it is impossible to estimate the actual scale of translation from monocular VO alone, since it cannot distinguish between solutions like (x,y,z) and (cx,cy,cz). What this line does is that it obtains the absolute scale from an external source: the ground truth in this case. In practice, this could come from another sensor like a speedometer (KITTI doesn't have this). The files 00,01,02,03,....txt files are essentially the ground truth data for trajectory # 0,# 1,# 2,# 3, etc... in the KITTI dataset. Maybe I can upload these text files if required in the project.
You're right, the user will have to upload the groundtruth file to get the scale, and also the camera calib file, I think, because (correct me if I'm wrong) the VO estimation is applied to the dataset selected as the input, right? So, in theory it could be applied to any monocular dataset. If that's the case, the user should need to upload both the groundtruth and the calib files.
All the best!
raghavendersahdev
commented
7 years ago Hi @famoreno Thanks for the advice I have fixed most of the bugs that you suggested earlier, I will soon upload within 2 hours or so, the sample video, tutorial and commit new code. And fix the leftover bugs (KITTI app freezing, grayscale not working and maybe one more bug) in the next commit later today by July 26
Not only a bit tricky but a lot! Ironically I was completely misleading here :P, sorry about that! What I wanted to say is that many of the options are always available even though they can't be used (which may lead to crashes). For example, if the input format is Single (or Stereo) Image, options for Visual Odometry, Repeatability and Tracking should not be elegible. The same with Decimation. It is just a way to avoid undesired/undefined behaviour of the app.
Thanks :) .will make the repeatability, tracking, VO hidden when user selects single/stereo image and similar other cases.
You're right, the user will have to upload the groundtruth file to get the scale, and also the camera calib file, I think, because (correct me if I'm wrong) the VO estimation is applied to the dataset selected as the input, right? So, in theory it could be applied to any monocular dataset. If that's the case, the user should need to upload both the groundtruth and the calib files.
Yes you are right, the user should ideally upload calibration files for this part too in addition to groundtruth, I was thinking of hard coding this for the 11 sequences in KITTI, but maybe that might not be a good idea. It can be applied to any dataset as long as ground truth files/calibration (which I need to do) are similar to those available for KITTI.
raghavendersahdev
commented
7 years ago Hi @famoreno , a sample video of the app can be found here. its not public I have committed the code with your suggestions: pending stuff:
Will do these pending points in my next commit before evaluation (July 26).
Also I had a question can I do the rawlog files part after the evaluation (July 26)?
For the third term (week 9-12) also, there is buffer week in week 12 that I kept for finishing up pending work. I have not scheduled anything (except wrapping up and finish pending work) during this time as per the project time line.
 jlblancoc
commented
7 years ago
jlblancoc
commented
7 years ago Hi @raghavendersahdev ! Great video 👍 I'm sure @famoreno will find more comments about changes to do, but just wanted to congratulate you and your mentor for the huge progress done in these weeks.
raghavendersahdev
commented
7 years ago Hi @jlblancoc , Thanks :-) Hi @famoreno I will make a commit within 2 hours or so which fixes pending bugs and has comments for Doxygen documentation. I have been stuck to fix the bug for progress bar for KITTI VO for quite some time. I am using somehting like this. Something is breaking, I will commit soon.
raghavendersahdev
commented
7 years ago Hi @famoreno few updates: I have fixed the following bugs:
Some bugs (2 bugs) that I still need to address:
Other than these bugs goals upto week 8 look in good shape, I will try to fix these bugs by tomorrow. I will upload another video showing the fixed bugs today.
famoreno
commented
7 years ago I also like the video! It's much more clear to me how to use the app now. I see that you've done a lot of updates in the last few days, great job :). I will try the complete app so far tomorrow and let you know my thoughts/suggestions.
But again, you've been doing a hard work these days. Congrats!
raghavendersahdev
commented
7 years ago Thanks @famoreno :+1: I will also fill in the evaluation tonight.
raghavendersahdev
commented
7 years ago new video with few bugs fixed is available here I just filled the second evaluation too.
raghavendersahdev
commented
7 years ago Hi @famoreno I was able to fix the app freezing issue during VO computation by popping up a dialog which shows the message, "Please wait, Visual Odometry Running" output is shown below, got the QFutureWatcher and QtConcurrent stuff working. The Dialogbox tells the user that the app is still running and not frozen

raghavendersahdev
commented
7 years ago Hi @famoreno I am in the process of writing code for Place Recognition task, will try to finish by Tuesday night (August 1). Currently I am planning of doing the following:
raghavendersahdev
commented
7 years ago Hi @famoreno small update: I am still working on Place Recognition (its taking a little longer than I had expected), I am currently storing the features from the training dataset. Each key-point has a descriptor associated with it and each descriptor is associated with an image, these descriptors are called words. So I compute all words in the training dataset with labels of the respective classes/places associated with them. Then for a testing image, I compute the descriptors and see which words it matches to that in the training dataset in a Nearest neighbour fashion (SSD). The class with the maximum number of labels for each descriptor is the output class. The implementation is near completion but am getting some errors that I need to fix. I am currently testing this on the KTH IDOL place recognition dataset.
I will fix place recognition errors soon and after that move on to the second mini project of "playing back mrpt raw log datasets in ROS"
raghavendersahdev
commented
7 years ago Hi @famoreno I have finished the place recognition task, it currently works with SIFT, SURF, ORB, BLD and LATCH descriptors and most detectors (except Harris-will add exception(pop up message box for cant be selected) for it)...! here are some sample outputs sample1, sample2 and sample3. A sample video for the same can be found here.. I had a few questions, are the following sufficient for the final evaluation or is there anything else I need to prepare?
I will start working on the second mini project and address your suggestions/feedback on the GUI app... Place recognition has a few minor bugs currently I will fix them.
Second Mini Project (Extend existing ROS packages for grabbing and playing back MRPT datasets)
Please let me know your suggestions.
jlblancoc
commented
7 years ago Great work so far! Let's wait for your main mentors to give you detailed feedback, but for now:
Is there a starting point on top of which I should be building the code somewhere perhaps here . Should I be creating a new fork of this? I guess I should be exending this ROS package right?
Yes, that's correct, go ahead and create the fork. Use the branch "master" as base for your work.
raghavendersahdev
commented
7 years ago Thanks @jlblancoc I will create a fork and start to extend this ROS package after getting used to and reading about the mrpt rawlog format.
famoreno
commented
7 years ago Hi @raghavendersahdev, sorry for the long silence! I see you've advanced quite a lot, congrats! Thanks for the new video, it makes things more clear for me.
I've been revising the code and here there are some tips/suggestions/comments about that:
99 in here? It would crash if the number of images is below 100. In any case I think it's for tracing purpose so I guess it will be removed in the last version.std::numeric_limits<double>::max() as initial value when looking for a minimum value instead of using an arbitrary large value (e.g. here).std::abs() is enough for computing the distance between words instead of using std::pow() and would save time (e.g. here).Regarding this:
I had a few questions, are the following sufficient for the final evaluation or is there anything else I need to prepare?
- code for the project with appropriate comments
- doxygen based comments for each function and instance variables
- tutorial file like this.
- will update this readMe file
- complete video demonstrating this project similar to and extending the previous one.
I think it's OK. Please, be specially focused in the code clean up and documentation, as it will be of extreme help in the future.
Regarding the ROS package, it would be useful to extend mrpt_bridge by implementing new conversions between other types of observations like the following (@jlblancoc & @feroze add more if you think it's interesting):
Also, take into account that the .rawlog file type should be supported by the benchmarking application. Have a look to this line and this tutorial to learn how to go through rawlog files.
All the best.
raghavendersahdev
commented
7 years ago Thanks @famoreno for the suggestions
- I see that the Place Recognition part is heavily oriented to be used with the KTH IDOL place recognition dataset. Maybe it would be better if it is more versatile by allowing the user to define his own labels and number of classes (currently the number of classes is hardcoded to the number of classes of the KTH dataset), but I know it would make it more difficult to implement, so I think it's OK to keep it simple as it is.
thanks, I will keep it as is for now.
- Why using the index 99 in here? It would crash if the number of images is below 100. In any case I think it's for tracing purpose so I guess it will be removed in the last version.
Yes I will remove it later, just for tracing purpose.
- Consider using something like std::numeric_limits
::max() as initial value when looking for a minimum value instead of using an arbitrary large value (e.g. here).
Will do it.
- I think this line is unnecessary. The same for lines from 472 to 479.
This line would be unnecessary as I am explicitly assigning the labels by iterating over the for loop. Will remove it, I was getting segmentation fault while debugging so I forgot to remove it, will remove..
- Maybe using std::abs() is enough for computing the distance between words instead of using std::pow() and would save time (e.g. here).
I will see if using std::abs gives better accuracies and change it to that if performance improves.
I think it's OK. Please, be specially focused in the code clean up and documentation, as it will be of extreme help in the future.
Will do it.
Regarding the ROS package, it would be useful to extend mrpt_bridge by implementing new conversions between other types of observations like the following
I will extend the mrpt_bridge ROS package, extending it makes it more clear to me than this. Maybe I can only write a driver/tester function to playback the mrpt datasets in the mrpt_rawlog package. Once a bridge is there between mrpt messaages format and ros messages, it should be able to view all the messages in Rviz.
raghavendersahdev
commented
7 years ago Hi @famoreno a small update
raghavendersahdev
commented
7 years ago jlblancoc
commented
7 years ago Hi @raghavendersahdev !
I've checked your contributions to the ROS node... thanks, they are great! :+1:
Some doubts:
Why have you duplicated the enum declarations for IMU indices with TIMUDataIndex? Duplication is doomed to eventually become obsolete, out-of-synch, with the original MRPT object and increase the maintainance work. Why not simply using the MRPT's TIMUDataIndex?? You already have an #include for it in the same header, so I can't see any reason to duplicate all the numerical codes here...
I like the idea of adding tests as the one you added in test_Bridge.cpp but... the important part in the main() is still commented out!! :-) Perhaps you just forgot about finishing it?
Let me know when you add the calls (and the ROS publishers,etc.) for all these new data types (or, at least, images, GPS, and IMU) to mrpt_rawlog so I can review it.
Good work, so far!
raghavendersahdev
commented
7 years ago Thanks @jlblancoc for the suggestions.
- Why have you duplicated the enum declarations for IMU indices with TIMUDataIndex? Duplication is doomed to eventually become obsolete, out-of-synch, with the original MRPT object and increase the maintainance work. Why not simply using the MRPT's TIMUDataIndex?? You already have an #include for it in the same header, so I can't see any reason to duplicate all the numerical codes here...
You are absolutely right, my bad, I will use directly the ones from the include of CObservationIMU.h
- I like the idea of adding tests as the one you added in test_Bridge.cpp but... the important part in the main() is still commented out!! :-) Perhaps you just forgot about finishing it?
Yes I am currently working on the tester function, writing the publishers and viewing in RViz, I should finish them by today. Will post a video, showing the results in RViz too. Earlier, It (the important part mrpt2ros) was giving an error which I have fixed, will commit the finished code soon.
- Let me know when you add the calls (and the ROS publishers,etc.) for all these new data types (or, at least, images, GPS, and IMU) to mrpt_rawlog so I can review it.
I will let you know as soon as I finish this probably by today. :-)
raghavendersahdev
commented
7 years ago Hi @jlblancoc @famoreno I have updated the tester function for the mrpt_bridge, I have a few questions with regards to the MRPT messages
orientation_covariance, angular_velocity_covarianceand linear_acceleration_covariance , so I am not setting them, does that sound right? shows correct output in Rvizposition_covariance, position_covariance_type, so I am not setting them, is this okay?ROS messages are successfully published after conversions, doing a rostopic echo topic_name shows the appropriate results as per the mrpt_bridge.
I have finished a sample tester function for the ros_bridge to be tested intest_Bridge.cpp file for you review. sample video here (sorry for the loud sound).
Looking forward to your feedback.
All other tasks have been finished as per the project time-line. In the next few days I will
jlblancoc
commented
7 years ago :+1: great! Thanks for the video, it helps a lot :-)
yes, it's fine to leave covariances not filled in in those ROS msgs.
I only miss one more type for ROS<->MRPT conversion (and its inclusion into rawlog_play): CObservationStereoImages.
It would allow playing back more recent datasets such that this one: http://www.mrpt.org/MalagaUrbanDataset
Please, download any of the shortest .rawlog to have an example dataset with stereo images for testing...
raghavendersahdev
commented
7 years ago Thanks @jlblancoc sure will do this by today. I will create a bridge between CObservationStereoImage to 2 * sensor_msgs::Image messages for left and right image and a stereo_msgs::Disparity message if the disparity image is stored in the CObservationStereoImages here.
raghavendersahdev
commented
7 years ago Hi @jlblancoc @famoreno I am almost done with the coding part from my side. Pending stuff:
I will try to finish all this by tonight and after this I look forward to your instructions to address your feedback/suggestions and the process of submission of the final code (merging, PR, link which has code to submit to google, etc.) :-)
famoreno
commented
7 years ago Hi @raghavendersahdev. Great work with the rawlog support for the GUI app and with the ROS bridge. Congrats again! And thanks @jlblancoc for taking care of this thread these days ;-)!
Regarding this:
mrpt::obs::CObservationRange <--> sensor_msgs/Range : the variable radiation_type is not available in CObservationRange, so I am not setting it too..the ROS range message has the range field taking single float number whereas the CObservationRange has a list of ranges as a TMeasurementList. that takes a list of ranges; there seems to be an incompatibility here. What should be done here?
I'm not sure why CObservationRange includes a deque of measurements (maybe @jlblancoc can explain why sensedData is a deque instead of a single number) but I think that the ROS->MRPT conversion should be just copying the value to the position zero (as you already do). BTW, I think that the best way to do this in here is by clearing the sensedData deque and then using push_back(). The way it is currently implemented would crash if sensedData is empty.
For the MRPT->ROS conversion, I also think that copying the value at position zero is OK instead of computing the mean value as you do here. But, in any case, I think that the deque will most probably contain only one value so in the end it will not affect the result.
All the best
raghavendersahdev
commented
7 years ago Hi @famoreno , I am running a little late, will upload the remaining tasks (videos, comments,bug fixes) by tonight. Aug 23 for your review.
raghavendersahdev
commented
7 years ago Hi @jlblancoc @famoreno I have made a video for each of my 2 projects:
I added license part in the beginning of each file in the benchmarking app, is that fine? I still need to add some more comments, do some little code cleaning and fix the CObservationRange thing. Will finish these by tonight (should take just 1-2 more hours).
After doing this should I be making a pull request? I wanted to make a pull request early on to avoid last minute glitches with:
git pull origin HEAD
Looking forward to your suggestions.
jlblancoc
commented
7 years ago @famoreno & @raghavendersahdev :
I'm not sure why CObservationRange includes a deque of measurements (maybe @jlblancoc can explain why sensedData is a deque instead of a single number) but I think that the ROS->MRPT conversion should be just copying the value to the position zero
Actually, despite its misleading name, CObservationRange can hold one or more ranges from any device that normally measures one range only. This class is mainly used for ultrasonic or IR sensors (just like the equivalent ROS msg says).
So, I think that the best mapping between MRPT and ROS here would be: one MRPT object to many ROS msgs. At the mrpt_bridge level, the conversion function could take a 0-based index for the user to reflect which CObservationRange observation to convert to ROS. The user then could publish the msg to a series of topics named like format(sensor_label_%d, index) or alike.
Converting from ROS => MRPT is OK to resize CObservationRange to only hold 1 element.
jlblancoc
commented
7 years ago Hi @raghavendersahdev ! Great videos 👍 @famoreno will carefully review (probably next week) your contributions and give you some more feedback. Regarding the mrpt_bridge and rawlog changes, I see them good enough, go ahead and open the pull-requests for the ROS part when you want, and I'll take a more careful look at the code afterwards.
Just one comment on the benchmarking API GUI: I can see it works nice with large screen resolutions but I'm concerned about what would happen with not-so-large screens. I mean, for example, if you de-maximize the window and shrink it a bit, what happens to all the controls? I would recommend you testing it and adding some scrolling panels that could gracefully handle this situation... don't you agree?
Apart of this very minor comment... good work! :-)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Initial description:
In this proposal we aim to build a GUI application which has the ability to benchmark various combinations of detectors/descriptors.
See attached PDF: 6307731490209792_1491218516_Raghavender_GSoC2017_proposal.pdf
Final results:
Videos: