 jdtournier
commented
9 years ago
jdtournier
commented
9 years ago Man, you guys are going to kill me... This chart springs to mind...
OK, here goes:
Maybe Image::Buffer should in fact be Image::BufferDisk
Possibly, although Image::BufferPreload is also used to access images on disk... A better name would be Image::BufferRaw, which at least hints at the fact that this buffer gives you access to the data as-is, in contrast to Image::BufferPreload.
So maybe these should instead be called Image::Image*?
:) This is a joke, right? I can't see how that's any less confusing...
In a previous version, this used to be called Image::Object, which was probably not a great deal more informative - but at least it avoided all the confusion that would ensue for developers and compiler alike if classes have the same name as their enclosing namespace... Not against a different name, but you'd have to come up with a more convincing one.
The other option is to keep the buffer and header separate, with the buffer only keeping a reference to its parent header. Personally, I think this would be a recipe for disaster: you really don't want to allow the possibility of the header being modified after the buffer is instantiated - this is why the Buffer classes inherit from ConstHeader rather than Header. Besides, I don't think it would change actual use of the API in any way, this would be purely a conceptual difference, with very little practical consequences for the way the code would be written. If you were to keep the Header and Buffers entirely separate, you'd need to provide the relevant information to the Voxel class too (so it would need to be constructed with both the Header and the Buffer), and would hence behave differently with the BufferScratch class, which does not require a full header, it only needs an InfoType interface. This would make a lot of the generic algorithms that we have very awkward... Otherwise, you could make all the Buffer class only provide a limited InfoType interface, constructed from the Header where relevant, so that there is enough information in there for the Voxel class to operate, but by that stage you might as well include the full header...
We actually thought about this name quite a bit, and I really do think Buffer is the best term here. This class provides a view into the image data as a linear array - that's its primary purpose. To be able to access this information meaningfully though, you need to have all the information related to the image dimensions and strides, which is what InfoType provides. And since InfoType is essentially a minimal header anyway, I don't really see a good argument for not including the full header while you're at it...
Having a single class that is not templated, but will operate on any type of underlying Image::Buffer* and any data type. I still don't see any way to make it possible (at least not without an absurd amount of code branching)
Precisely. You can't do this without virtual methods or code branching, and if you do that you can't avoid a significant loss of performance. For instance, when I modified tckgen to use an Image::BufferPreload rather than an Image::Buffer, this improved performance by a factor of ~3 (at least on my laptop, when I was developing this class). This is because you don't get the cost of a full-blown function call per image intensity read/write (and there's a lot of them in there with all the interpolation that goes on, particularly for iFOD2), and the read/writes themselves don't involve any type conversion or scaling.
What I would much rather do is figure out a cleaner API to avoid the need to write template type specifications everywhere, which can be done using a variety of techniques - especially in C++11 with the auto and decltype keywords. What also helps is writing helper functions that return the fully-formed type, so you can declare it with auto - much like the Buffer classes' new .voxel() call.
Anyway, open to ideas here, but only within reason...
 draffelt
draffelt Lestropie
Lestropie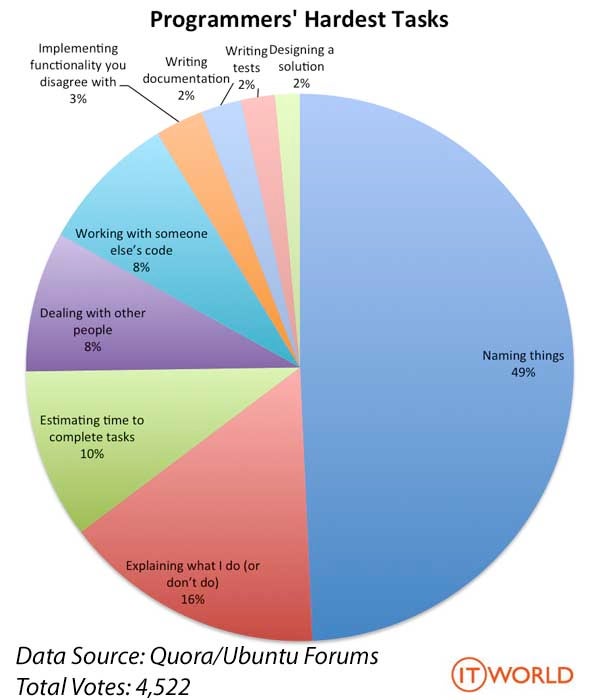{kind=link}
Thijs is yelling in my ear and won't let me go home until I write this up...
So he ran into a few understanding hiccups on figuring out MRtrix3's image access classes, and got me wondering about whether things could be improved a little bit. Let's enumerate these for the sake of responses: