 MaartenGr
commented
1 year ago
MaartenGr
commented
1 year ago In BERTopic, any embedding model that you pass as a parameter is converted to a bertopic.backend.BaseEmbedder class. So using topic_model.embedding_model.encode will not work as the encode function is specific to sentence-transformers. Instead, using topic_model.embedding_model.embed should work.
 Bougeant
Bougeant
I tried to load the fitted topic model with the following command:
and I can guarantee that I have set up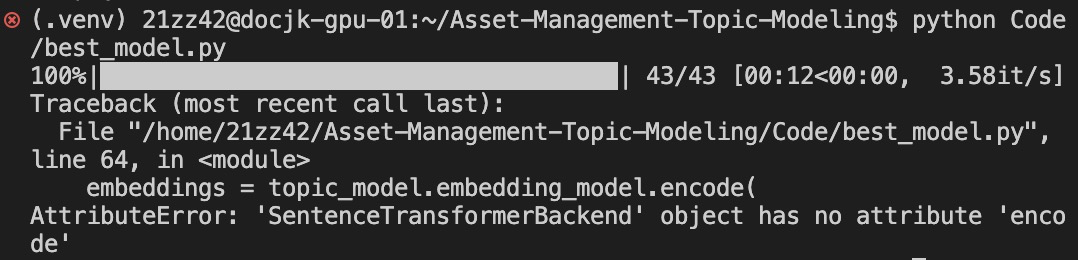
calculate_probabilitiesandprediction_datatoTrue, but it still give the following error when I attempted to visualize the embedding, what should I do? @MaartenGr I appreciate it a lot in advance!