 MaartenGr
commented
2 years ago
MaartenGr
commented
2 years ago Thank you for the great work, I currently using BERTopic for one of my problem. I am facing issues while updating the topics with the above code.
This might be related to the number of unique topics that you have in new_topics. It is important that the number of topics in topics are the same as those in new_topics. For example, if topics 1 through 5 are in topics those should also be in new_topics.
Other than that, it would help if you could share your code for doing this. Also, which version of BERTopic are you using?
I am also curious to know, could you please suggest me to calculate the percentage of outlier BERTopic produces (any method, standard or any suggestions from you).
That depends on the clustering model that you use. As a default, BERTopic uses HDBSCAN which indeed generates outliers. If you want to reduce those outliers, it might be worthwhile to read through the documentation here or use a model that does not create outliers, like k-Means.
 rubypnchl
rubypnchl
Hi MaartenGr,
Thank you for the great work, I currently using BERTopic for one of my problem. I am facing issues while updating the topics with the above code. My main aim is to reduce outliers but with quality of topics. I am also curious to know, could you please suggest me to calculate the percentage of outlier BERTopic produces (any method, standard or any suggestions from you).
I am getting the following error: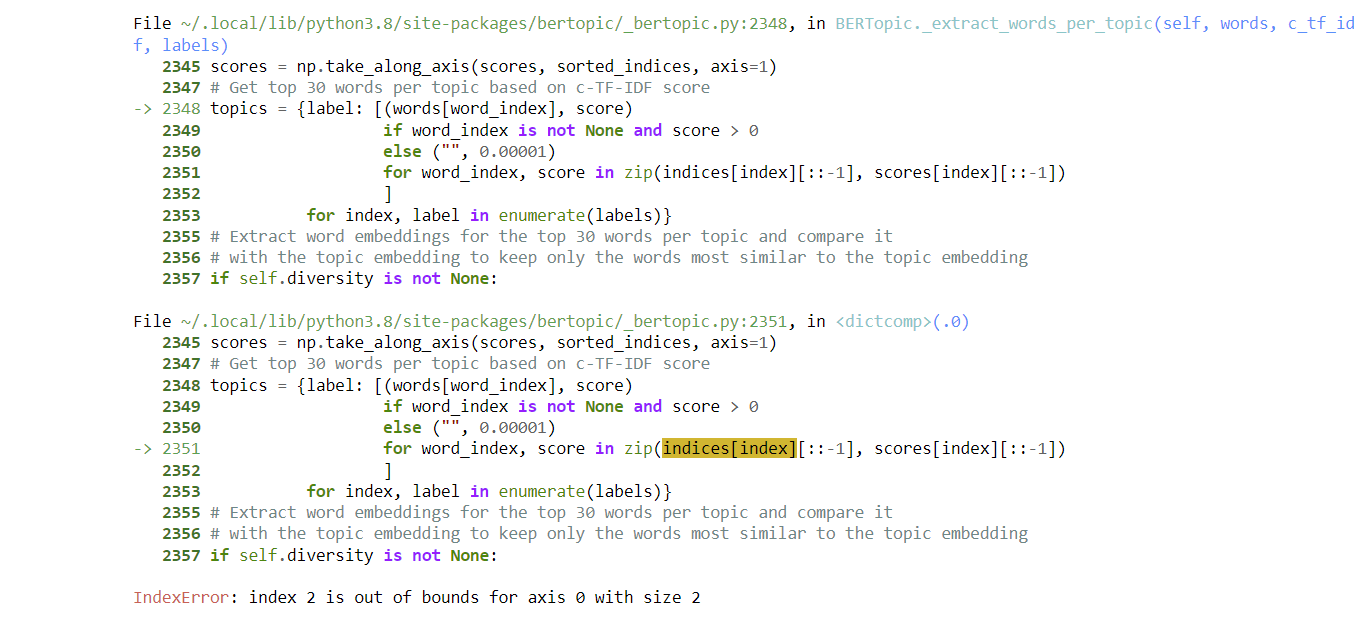
PS: Thank you for the time saving library!
Best Regards,
Originally posted by @rubypnchl in https://github.com/MaartenGr/BERTopic/issues/529#issuecomment-1225986102