 wuhao08
commented
5 years ago
wuhao08
commented
5 years ago 
Open Ming-Lian opened 5 years ago
wuhao08
commented
5 years ago
 chensole
commented
5 years ago
chensole
commented
5 years ago 
 pangkun97
commented
5 years ago
pangkun97
commented
5 years ago  After the first contact with machine learning, I have the framework of machine learning and the understanding of several classifier principles
After the first contact with machine learning, I have the framework of machine learning and the understanding of several classifier principles
 zoe106
commented
5 years ago
zoe106
commented
5 years ago 谢谢连明师兄的讲解~~笔记有点长,放在简书上了,https://www.jianshu.com/p/65807c4fdf9a
 Wentting
commented
5 years ago
Wentting
commented
5 years ago *感知机是一个线性的分类器,以二维的问题来说,如果数据线性可分,那么一定存在一些线,使得线两侧是两个不同的类 一个好的感知机模型:


个人理解: 支持向量机实在感知机基础上的一种改进,感知机只考虑正确分类,因此分界面不是唯一的。而SVM需要找到最优的超平面,学习的策略就是使间隔最大化,并最终转变为一个凸二次规划问题,因此可以将模型定义为在特征空间上间隔最大的线性分类器。




师兄讲的很好,自己推一遍再理解师兄讲的思路有很多收获,但是菜鸡如我还是有很多不太懂的,第一次打卡,以后慢慢填吧
 gsh150801
commented
5 years ago
gsh150801
commented
5 years ago 根据一些已观察到的证据(例如训练样本)来对感兴趣的未知变量(例如类别标记)进行估计 (实现路径之一,概率模型,本质是,将机器学习任务归结为计算变量的概率,其核心是基于可观测变量推断出位置变量的条件分布) (极大似然是对概率模型参数学习优化目标的一种定义,是道; EM算法是用于求解极大似然估计的一种迭代逼近的算法,是术;) (求解过程: ①定义优化目标:极大似然估计mle 只有可观测变量:贝叶斯分类器 含有隐变量:隐马尔可夫模型 ②求解优化目标: 标准方程法:一步到位获得最优解的策略 迭代法(如剃度下降法,牛顿法,拟牛顿法,em算法):先找一个随机解做为起始的当前解,然后对当前解进行迭代更新,保证每一次迭代后得到的新解朝着最优化的方向前进 ) #正经的笔记稍后再补上,好久没看数学,感觉要补的很多。背景知识要去看看😂 不懂的就查查参考书目
 SZJShuffle
commented
5 years ago
SZJShuffle
commented
5 years ago 

 yueyang0907
commented
5 years ago
yueyang0907
commented
5 years ago 第一次打卡and第一次在github上回复😂,嘿嘿,谢谢明哥的分享~很高兴能加入兴趣小组呀!
这次的笔记做的不是很好,挺乱的😂。。听了明哥的直播和结合了网上的资料。。。理解的不是很好哇
调库说是简单,但是深入理解其中的推理,实属不易。。。【高数、线代、概率】
emm好啦,放上我的笔记。。##等以后在深入理解些,再来更改



 Hua-CM
commented
5 years ago
Hua-CM
commented
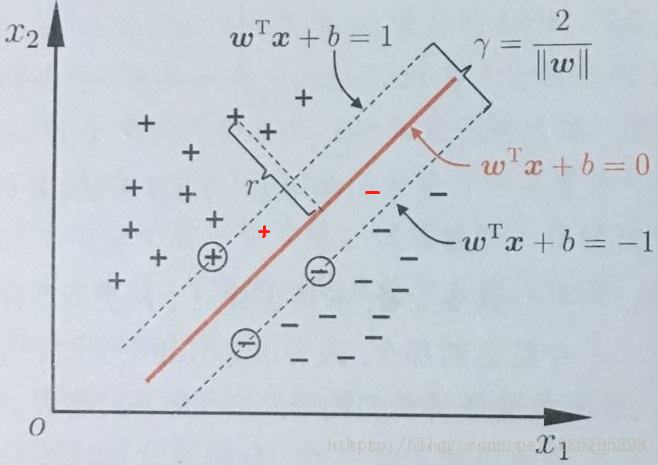
5 years ago 感知机只能做到线性分类界面

分类界面(超平面):
$$ w^Tx+b=0 $$
分类函数:1 if sign(*wx+b=0**) >1 else -1
点到界面的距离:
$$ r=\frac{w^Tx+b}{||w||} $$
推导过程:
假定有如下超平面 ,及超平面外一点x0,且记x0在该超平面上的投影为x1
$$ w^Tx+b=0 $$
则有:
$$ \vec{w}\vec{x_1x_0}=|\vec{w}||\vec{x_1x_0}|cos\Theta $$
式中w为法向量,显然这里的cosΘ=1,所以有
$$ \vec{w}\vec{x_1x_0}=|\vec{w}||\vec{x_1x_0}| $$
先算等式右边,记向量x0x1的长度为d,则右边等于:
$$ ||\vec{w}||d $$
再计算等式左边,根据坐标计算有
$$ \vec{w}\vec{x_1x_0}=w^1(x_0^1-x_1^1)+\cdots+w^N(x_0^N-x_1^N)\\ \quad\quad\quad\quad\quad\quad\quad=w^1x_0^1+\cdots+w^Nx_0^N-(w^1x_1^1+\cdots+w^Nx_1^N)\\ =w^Tx_0-(-b) $$
因为左右相等,所以不难计算出距离公式。
批量梯度下降(Batch Gradient Descent):需要对当前的训练集全部遍历一遍
跳出局部最优:随机梯度下降与加大学习率
基本假设:离两类间隔尽量远的分界面是一个“好”的分界面
间隔的计算:由每一类最靠近分界面的点决定
点距离的计算:见感知机
其中一类样本必然存在最小距离:r(i)≥min(r),这是几何间隔,记为r
因此SVM实质上是在找使两侧最小距离最大化的超平面:max(min(r1)+min(r2))
将上述提到的几何间隔乘以|w|就得到SVM超平面的函数间隔,即
$$ r=||\vec{w}||r $$
先假设一个超平面为分类平面,对于任意一个给定的超平面:
$$ w^Tx+b=0 $$
其必然有上述提到的函数间隔(如下图)^1
不妨设两类距分类超平面的最小距离分别为{-1,1},则根据以下点的距离公式,我们可以算出在给定超平面的情况下两侧最小距离为下面的二式。
$$ r=\frac{w^Tx+b}{||w||}\quad\quad(1)\\ r=\frac{2}{||w||}\quad\quad\quad\quad(2) $$
因此SVM实际上是在找使(2)式最大化的超平面
且具有约束条件(即没有比最小距离点离分类超平面更近的点)
$$ y_i(w^Tx_i+b)≥1 $$
我的理解:从这个角度看,几何间隔的支持向量机与感知机相比,一个只考虑最小距离,一个考虑所有样本
基本的拉格朗日乘子法是求函数f(x1,x2,...)在约束条件g(x1,x2,...)=0下的极值的方法。
用在SVM中就是求下列(1)式在(2)式约束条件下的极致
$$ r=\frac{2}{||w||}\quad\quad\quad\quad(1)\\ y_i(w^Tx_i+b)≥1\quad(2) $$
具体怎么推的略了(看到数学头就大)
剩下的内容:
对偶问题
KKT问题
感知机和SVM的判别函数:sign()不可导,因此提出逻辑回归的判别函数
总的来说就是吧判别函数换成了一个smooth过的函数,然后继续套上面的拉格朗日乘子法
明哥总结:必须先可视化看下,再决定怎么干。不能上来就当调包侠,调啥用啥。
 jsonProgram
commented
5 years ago
jsonProgram
commented
5 years ago Marked!
 Peerpoll
commented
5 years ago
Peerpoll
commented
5 years ago 常用的3种方法:
批量梯度下降,优点:容易得到最优解,缺点:需要考虑所有的样本,处理速度慢 随机梯度下降,优点:迭代速度快,缺点:每次样本随机,不一定是沿着收敛方向 小批量梯度下降,每次选着一部分数据进行优化,较为方便。

可以将任意输入,映射到[0,1]区间,将在回归模型中得到的值,映射到sigmoid函数中,将回归的到的值转化成概率值,从而进行分类。
 xuyinsheng
commented
5 years ago
xuyinsheng
commented
5 years ago 



 2333jing
commented
5 years ago
2333jing
commented
5 years ago 

 saberlike
commented
5 years ago
saberlike
commented
5 years ago 




https://ming-lian.github.io/2019/07/22/Bioinfo-ML-Club-4th/