 PannenetsF
commented
2 years ago
PannenetsF
commented
2 years ago Hi, thanks for the feedback!
This is probably due to the lack of input model_3_cv2 in the block. You can check the subgraph's code by print(subgraph.code).
I guess you can fix it by using the snippet to append them to the subgraph :
def append_extra_inputs(nodes, layer_node_list):
# there are some nodes in the block which are used but not in the list.
# e.g. a global dict used in UP or EOD.
extra_inputs = []
for node in layer_node_list:
for arg in _flatten_args(node.args):
if isinstance(arg, torch.fx.Node):
if arg not in layer_node_list:
extra_inputs.append(arg)
return extra_inputs
layer_node_list += extra_inputs
_layer_node_list = []
for node in layer_node_list:
if node not in _layer_node_list:
_layer_node_list.append(node)
for idx, node in enumerate(model.graph.nodes):
node2idx[node] = idx
layer_node_list = sorted(_layer_node_list, key=lambda x: node2idx[x]) luyi404
luyi404

Hi, When I use advanced_ptq of mqbench to quantify my model, I get the keyvalue error problem in this place.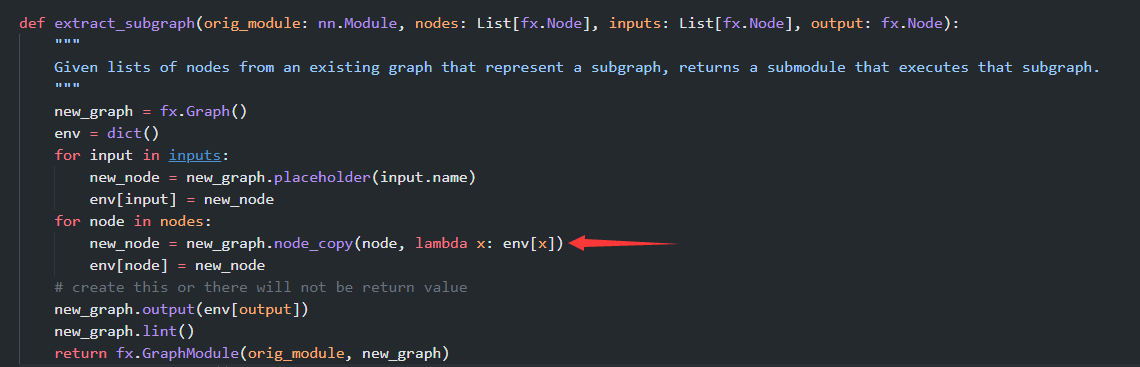 The adaround optimization operation can be completed for the first few layers, and this error will appear at one layer, like:
The adaround optimization operation can be completed for the first few layers, and this error will appear at one layer, like:
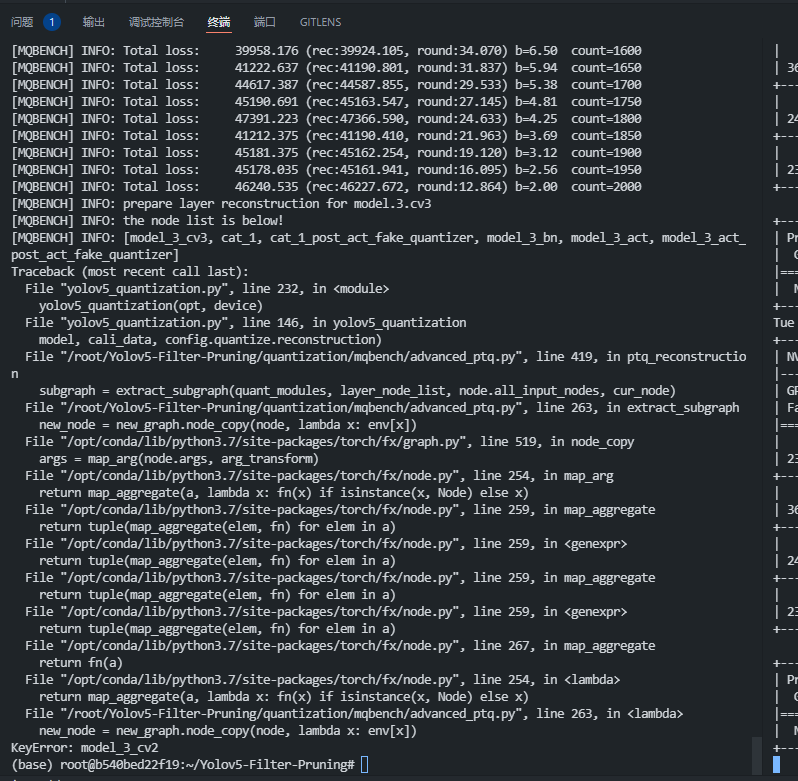 However, the same pipeline with navie_ptq works well. Looking forward to your reply
However, the same pipeline with navie_ptq works well. Looking forward to your reply