 JohnTigue
commented
1 year ago
JohnTigue
commented
1 year ago Since the backend of this hyponwerk service is ECS Docker cluster – i.e. Docker images deployed from ECR – then fer sure the API request handler (Lambda) should be Docker images, not the old school ZIP file format from pre-2021 reInvent. This way the whole thing is Dockerized – and will definitely NOT work anywhere except AWS. But there's still tons of Docker goodness even within that AWS-only world.
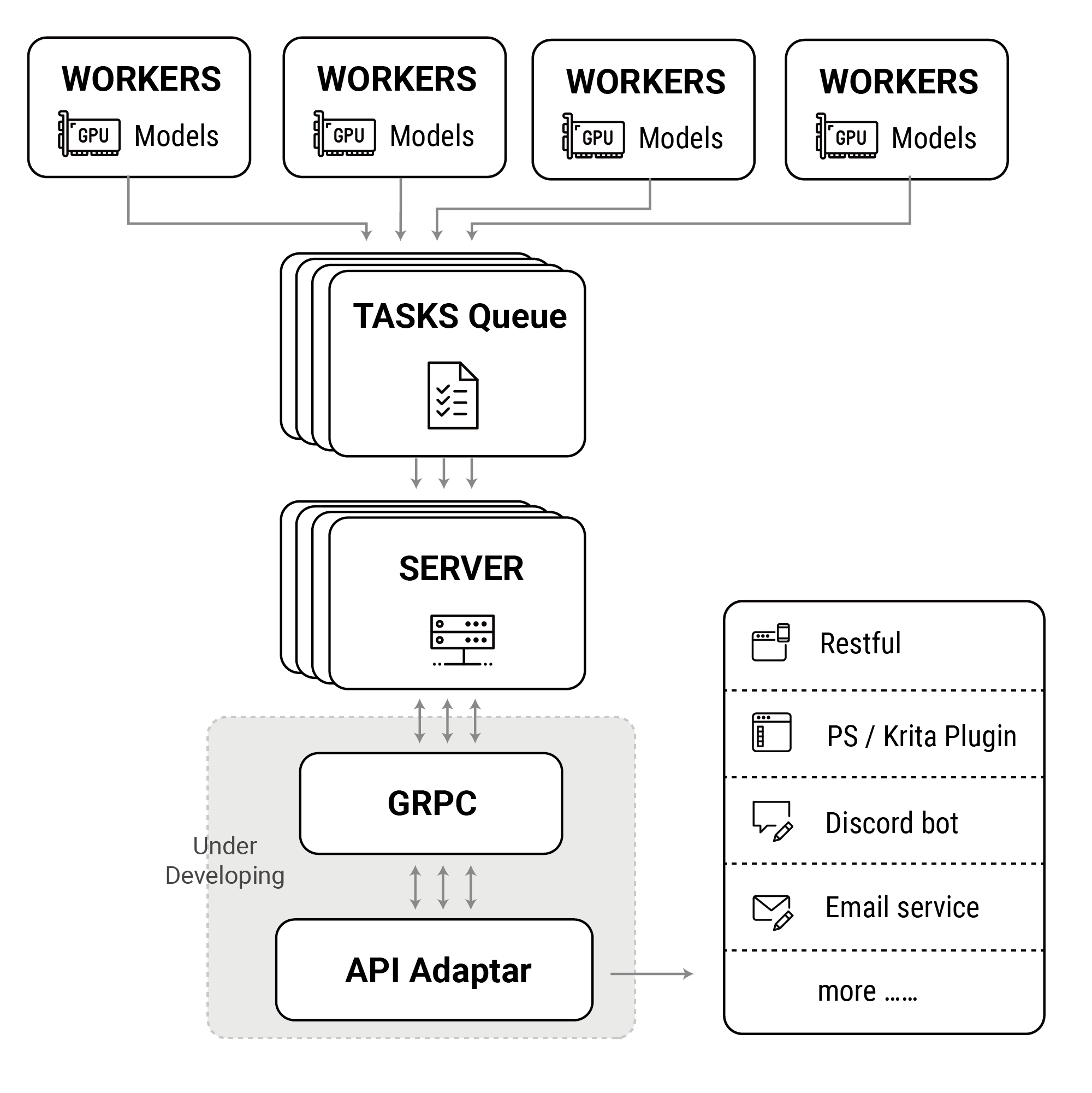

Components:
We are going to want to have a full-on web service which implements the Stable Diffusion API as found in Automatic1111 (behind the
--apiCLI flag). This will be the interface into our SD Docker render cluster from various client programs (Photoshop, Blender, etc.)I'm guessing this will have the same internal architecture as the Discord bot codebase from AWS that I'm starting with. Here's that architecture:
So, the service gets an HTTP request at API Gateway which forwards it into Lambda for processing, which queues it up for handling by the render cluster on ECS. I'm not sure what the request looks like when it comes from their Discord bot. The A1111
--apimay be different, but we can just hack on A11111's (Python?) code that parses the HTTP request.