MukhlasAdib
commented
3 years ago
MukhlasAdib
commented
3 years ago Hello! Before I can make any conclusion about your problem, did you make any change to ClientSideBoundingBoxes.get_bounding_boxes() method in test_draw_bb.py?
Closed rak7045 closed 3 years ago
MukhlasAdib
commented
3 years ago Hello! Before I can make any conclusion about your problem, did you make any change to ClientSideBoundingBoxes.get_bounding_boxes() method in test_draw_bb.py?
 rak7045
commented
3 years ago
rak7045
commented
3 years ago Hello,
Thanks for your reply. Yes, I have made some changes. Kindly see the attachment.

MukhlasAdib
commented
3 years ago I think I know what your problem is. As stated in the error message, the problem occurred when the program tried to evaluate the following line
ClientSideBoundingBoxes.draw_bounding_boxes(self.display, depth_patches)
which was originally built to visualize the areas (called depth_patches) that is used for depth-distance comparison (for occlusion filter) so that I could understand how the algorithm worked. It is returned by filter_occlusion_bbox() method as 2D bbox, (2,2) array. For simple, I think commenting that line will solve your problem.
However I do not recommend you to change the ClientSideBoundingBoxes.get_bounding_boxes() method like that because filter_occlusion_bbox() method need the 2D bbox to determine which area in the depth image to look at. It is performed in the following lines. Passing a 3D bbox might cause the occlusion filter not working correctly.
One solution that I think can solve the problem is:
draw_bounding_boxes() method.carla_vehicle_annotator.filter_occlusion_bbox(), add selector as another returned variable. This is a list of booleans with the same length as vehicles, where if selector[i] is true, then vehicles[i] is visible to the observer and occluded if otherwise. selector in ClientSideBoundingBoxes.get_bounding_boxes(), then at the end of the method you can add a line that remove occluded 3D bboxes based on the selector. This can be done by simply adding this linevisible_3d = [bounding_boxes_3d[i] for i,s in enumerate(selector) if s]
ClientSideBoundingBoxes.get_bounding_boxes()return visible_3d , depth_area, depth_capture
ClientSideBoundingBoxes.draw_bounding_boxes(self.display, depth_patches)
I haven't tried it either. If something is still wrong or if you need another form of solution, I guess I have given you enough information about the core of the problem so you can edit the source code as you need. You can also look at the semantic lidar-based occlusion filter which I think is less erroneous than the depth image-based one (check out #5).
Thanks! feel free to ask if there's anything else that confuses you.
rak7045
commented
3 years ago Hello, I have made changes as you said.

But, when I comment depth_patches I am getting error as shown. I tried to remove depth_patches too then got error like 2 arguments were missing.


I will try using semantic lidar and let you know. I think since you have written code for getting 2D boxes, I need to get 3D bbox co-ordinates as outputs. So in CVA I also need to change save_output( ) function along which converts 3D to 2D p3d_to_p2d_bb(p3d_bb) right?

MukhlasAdib
commented
3 years ago I have made changes as you said.
Looks like there are some mistakes here. You don't need to add selector as argument of ClientSideBoundingBoxes.get_bounding_boxes(). What I meant is, edit filter_occlusion_bbox() method in carla_vehicle_annotator.py file. Change the return line here to
return filtered_out, removed_out, patches, depth_capture, selector (note I added the selector variable)
Of course, you also need to change the method call in ClientSideBoundingBoxes.get_bounding_boxes() at this line to get the selector variable
filtered_out,removed_out,depth_area,depth_capture,selector = carla_vehicle_annotator.filter_occlusion_bbox(bounding_boxes_2d,vehicles,camera,depth_meter,vehicle_class,depth_capture,depth_margin, patch_ratio, resize_ratio)
Then place this line after that
visible_3d = [bounding_boxes_3d[i] for i,s in enumerate(selector) if s]
I will try using semantic lidar and let you know. I think since you have written code for getting 2D boxes, I need to get 3D bbox co-ordinates as outputs. So in CVA I also need to change save_output( ) function along which converts 3D to 2D p3d_to_p2d_bb(p3d_bb) right?
Yeah! But if you want to use carla_vehicle_annotator.auto_annotate_lidar() directly, you may also need to edit that method so that it can return the 3D bbox. I guess you only need to change get_2d_bb() here to get_3d_bb() that you have made earlier.
rak7045
commented
3 years ago Hello, I tried using test_semantic_lidar.py for getting 3d bboxes. For this purpose, I commented p3d_to_p2d_bb( ) method. And made modification in get3d_bb( ). Please see the attachment.

Based on this I have made changes in auto_annotate_lidar( ) method. So I returned those filtered lidar data and filtered bboxes. As my knowledge, now I have 3D bounding boxes information.

Now I need to save these information in save_output( ) method. Here you crop the cuboid into a rectangle so I commented it and save the image as it with 3D bbox. Correct me if I am wrong.
 I shouldn't give outline color I'll remove it.
I shouldn't give outline color I'll remove it.
So when I commented crop bbox part, I got Attribute error: bbox.tolist( ). Anyhow tolist( ) makes a nested list I commented that line and assigned bboxes to the out_dict.

When I did so, I got the following error.

Thanks for your help in advance.
rak7045
commented
3 years ago Hello,
Since save patched is to save image with drawn bbox, I set it to false. And also uncommented the tolist( ) method. Then this error arises.

If I do not comment crop bboxes part I can run and getting images but unable to get bounding box information and vehicle class too. Just images I am getting.
MukhlasAdib
commented
3 years ago Hi!
Based on this I have made changes in auto_annotate_lidar( ) method. So I returned those filtered lidar data and filtered bboxes. As my knowledge, now I have 3D bounding boxes information.
So far I think this part is good.
Since save patched is to save image with drawn bbox, I set it to false. And also uncommented the tolist( ) method. Then this error arises.
You did not make any change to test_semantic_lidar.py? bboxes should be a list of numpy arrays while according to the error message, it turned out to be a list of list (?). Maybe you can try to print(bboxes) to see what is actually passed to the function and share the printed output to me.
If I do not comment crop bboxes part I can run and getting images but unable to get bounding box information and vehicle class too. Just images I am getting.
Well, this one is strange. I will check the program again.
MukhlasAdib
commented
3 years ago Wait, I think I got it.
The output of get_bounding_box() is an array, which contains bbox coordinates of a single vehicles. Then, the second line in get_3d_bb() that you made converts it to a list. What if you comment the second line? I mean this one
p3d_bb = [bboc for bbox in........]
rak7045
commented
3 years ago Hello,
Thanks so much. I am getting images and bounding box co-ordinates but not proper 3d bounding box.


MukhlasAdib
commented
3 years ago Great!
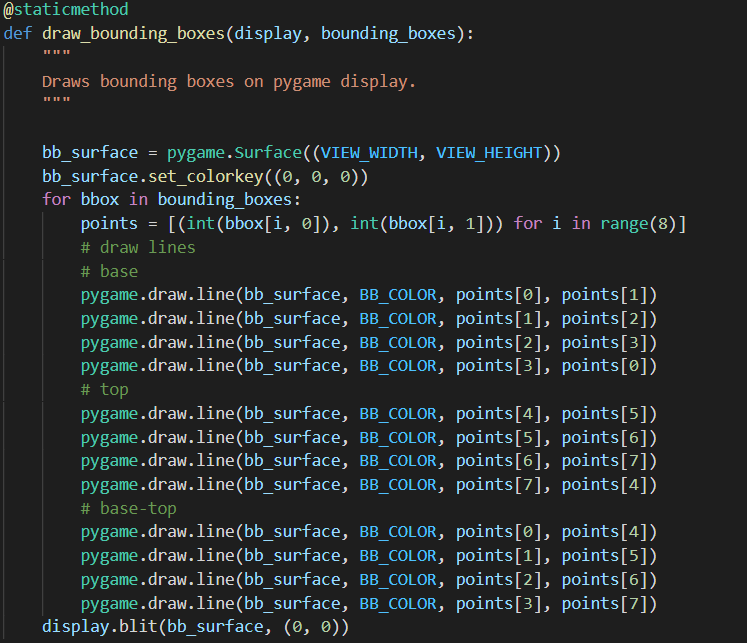
It is because the codes that is used to draw the boxes was made to draw 2D bbox, not the 3D one. Under your condition, it actually draws a rectangle that connects the front-right-lower vertex with the back-right-lower vertex of the 3D bbox. To draw the 3D bbox correctly, you need to change the crop bbox code. You can use the last pic that you attached in your first comment as a reference (which is based on pygame module, we are using PIL module to draw the bbox here).
rak7045
commented
3 years ago Hello,
I have written in this way.

Line method got multiple arguments. Do you have any idea how can I write it?
Or can I write in this way? for bbox in bboxes: points = [(int(bbox[i, 0]), int(bbox[i, 1])) for i in range(8)] base = [ point[0],point[1],point[2],point[3]] img_draw.rectangle( base, outline = 'red')
Similarly for other too (top and base top)?
MukhlasAdib
commented
3 years ago You're almost right. Take a look at this link for more information about how to draw line with PIL.
Based on that, maybe this is the syntax that you need for each line
img_draw.line([points[0],points[1]], fill ="red", width = 0)
Note that the two points are combined as a single list.
I don't think using rectangle will make it right since the cube surfaces is not always be rectangles from all points of view. But you can try it anyway.
rak7045
commented
3 years ago Hello,
Thanks so much for your help. Now I can generate images with 3D bounding boxes.

Now I would set some weather parameters. So I created a class with defined parameters. For reference I am attaching it.

Then I imported this into carla_vehicle_annotator.py file. In this file I defined a method as set_weather(weather_option). Then carla.weatherparameters(*weather_option). Kindly see the attachment.

Then in test_semantic_lidar.py file I have written in this way.

Then error arises.

So my question is am I complicating it? I just need to make rain in the map. So after setting blueprints in test_semantic_lidar.py, shall I write this part of code.
weather = carla.WeatherParameters( cloudyness=80.0, precipitation=30.0, sun_altitude_angle=70.0)
world.set_weather(weather)
Sorry for the long post. Thanks so much for your help again. It means a lot.
MukhlasAdib
commented
3 years ago weather = carla.WeatherParameters( cloudyness=80.0, precipitation=30.0, sun_altitude_angle=70.0)
world.set_weather(weather)
Obviously this one is more straightforward.
But if you want to make it like the one you wanted first, here are some points that I got from your code.
set_weather() method, you call the method itself, which makes the program to loop endlessly inside it. I guess it should be world.set_weather()? If that so, then you also need to pass the world object into your set_weather() method as an argument. I think this is the main source of your error. WeatherSelector.morning(), midday(), etc. are in the same order as the order of arguments of carla.WeatherParameters(). Why don't you just make the morning(), midday(), and similar methods return carla.WeatherParameters objects rather than list of weather parameter values? I think it is more efficient and you also don't need to make the set_weather() method. Just call world.set_weather() directly in the main code.That's what I could say so far. Sorry if I misunderstood some parts of it.
rak7045
commented
3 years ago Hello, Thanks I got it done with the weather parameters. Now I need to save outputs of camera calibration parameters as well. So how can we get that? I think we are returning the calibration from get_camera_intrinsic( ) method. Then in get_bounding_box()method can I return camera_k_matrix ? And in save_output( ) method define about these k matrix?
Could you please clarify me? And also how could I spawn only cars in the map?
MukhlasAdib
commented
3 years ago Hello!
About the camera intrinsic, the required data are already embedded in the carla camera object. The get_camera_intinsic() method just takes these embedded data from the object to construct the matrix. So, you can use it independently from the get_bounding_box() method. Just call the method in your program:
cva.get_camera_intrinsic(camera)
where camera is your carla camera sensor object.
And also how could I spawn only cars in the map?
If you look at the vehicles' attributes list here, the vehicles have an attribute called number_of_wheels. So you need to select actor blueprints that have number_of_wheels=4 before spawning the actors. I haven't tried this one either. But I think I ever saw an example of actor blueprints filtering in one of example codes provided by Carla.
rak7045
commented
3 years ago Hello,
I have a query related to max_dist. I have changed the camera orientation to the drone view. So the camera could see more distance objects. I am getting false negatives (there is a car but no bounding box to it). What would you suggest?
Should I increase the distance to 150 or so and also the min_detect. I am placing 150 cars in Town 06.
 In this picture there was a car in front(near other junction) but no bounding box to it. Could you help with this?
In this picture there was a car in front(near other junction) but no bounding box to it. Could you help with this?
Thank you
rak7045
commented
3 years ago Hello, The previous comment I could achieve it by changing the max_dist. And also I could spawn only cars in the map.
For saving these camera parameters I tried calling the method get_camera_intrinsic( ). I got the following Attribute error:

I have call that method in the following way: cva.get_camera_intrinsic(cam_bp)

Could you please help me with this?
MukhlasAdib
commented
3 years ago Hi!
Sorry I forgot to reply to your last message. Glad that it's solved by only changing the max_dist. I think there is also a limit to that due to the sparsity of the LiDAR sensor. If later you find that there are still some objects that are not detected by the algorithm, you can try using more channel in your LiDAR.
About the get_camera_intrinsic method, the argument should not be the camera blueprint, but the camera object. It is the object that is returned by spawn_actor() method when you spawn the camera. Just like this cam variable here.
I hope this helps
rak7045
commented
3 years ago Hello, I have called that method but there is no change. I could print the calibration matrices. I need to save this for the respective image. I will go through this if I miss something I will contact you.
Now there is one stupid question. Sorry!
In CVA and test_semantic_lidar we didn't declare the FOV and Image size. In test_semantic_lidar shall I set attributes for the RGB camera of image size x , image size y, FOV. Because now I need to play a bit with resolution of the image and FOV.
But since we didn't declare those attributes how the images are generated 600 x 800 and with fov 90. I don't think this attributes set by default if we do not mention.
Could you please help me?
MukhlasAdib
commented
3 years ago Yes you should change the attributes, and these attributes have default values like you mentioned. You can set the camera parameters by setting the attributes of the blueprint before spawning the camera. For example the line here set the sensor tick (frequency) into 1 s. The list of attributes can be found in the documentation here. For example, you can change the camera fov by calling
cam_bp.set_attribute('fov', '120')
Note that the values are passed as string.
rak7045
commented
3 years ago Hello! I have few queries regarding the false negatives. My orientation of camera is drome kind of view with FOV 69° with full resolution 1920*1080. My orientation is as follows: "carla.Transform(carla.Location(x=-3, z=50), carla.Rotation(pitch = -20))"
I am trying to generate data with these parameters. I have changed the max_dist while using depth camera information. I have false negatives there too but less compared to sematic lidar. Here I see the lidar points are not generated so far.


How can we resolve this? Increasing no. of channels only will work? I don't think so. Since this lidar points are not pointed farther distance there are too many false negatives? Correct me if I am wrong.
Note: The distance ( means the view sight)might increase more later in the map. Taking this also into consideration how can we generate data without false negatives.
Could you please help me with this? If I could solve these false negatives? I will generate more data with fov 120 degrees and so. Your help is really appreciated. Thanks you so much.
MukhlasAdib
commented
3 years ago Hello!
First, here are several things that you need to make sure:
range attribute of the LiDAR, it is 10 m by default but I usually set it to 100 m. Perhaps you need it to be as far as possible (this is probably the main cause of your problem)lower fov and upper fov attributes of the LiDAR so that it matches the vertical FoV of the camera. Note that the camera's fov attribute that we set during deployment is the horizontal FoV. The vertical FoV can be calculated based on the image size and the horizontal FoV. In case you don't want to do the math, you can calculate it through this link. If you get the vertical FoV = 40 (for example), then set the LiDAR lower fov to -20 and the upper fov to +20. channel while keeping the points_per_second constant will make the points to appear sparser horizontally. So please also consider increasing the points_per_second parameter. But be prepared because it will make the data acquisition process runs slowerPlease inform me again if it still doesn't work.
rak7045
commented
3 years ago Hello again, I am collecting data for a CNN network to learn. As already mentioned in #5 about missing Bboxes in the field of view has been solved. I see the problem still persists.
I attached a sensor to a car. The Altitude (z-axis) and the Picth angle of the camera changes according to the requirements. While collecting the data the missing bboxes occurs. I am attaching the picture for reference

The sensor which is attached to the object is stationary due to traffic signal. Then, a car has appeared in the frame as shown above.
The above image is the frame where the car entered and after for some frames the object has bounding box to it.

While the object is at the end i.e while leaving it has no bounding box to it. This problem has appeared for each requirement we collected.

Do you have an idea on this how to solve the problem?
TIA
Regards Ravi
Hello, First I have used your code to generate 2D bounding boxes. I have been successful with that. Now I would like to generate 3D bounding box co-ordinates. So I commented which converts the information from 3D to 2D. While I was testing using test_draw_bb.py I am getting an error stating " index error: out of bounds ". I am attaching the picture for reference. Could you please clarify me how could I resolve the error? BTW, I am new to Carla learning and working on it to generate datasets for training the deep learning architecture.