 davaya
commented
2 years ago
davaya
commented
2 years ago RDF is used by the knowledge graph community, and in my (limited) experience some practitioners have an almost religious opposition to UML datatypes, despite the fact that the explicit purpose of RDF collections and JSON-LD value objects is to define datatypes (structures that are NOT graph nodes).
Protege is also a graph explorer.
Since XSD and JSON Schema and CDDL and SQL are all schema languages, can you provide pointers to projects or tools that use RDF to define datatypes (which are inherently DAGs that can optionally define directed but cyclic references), not undirected knowledge graphs?
 AtesComp
AtesComp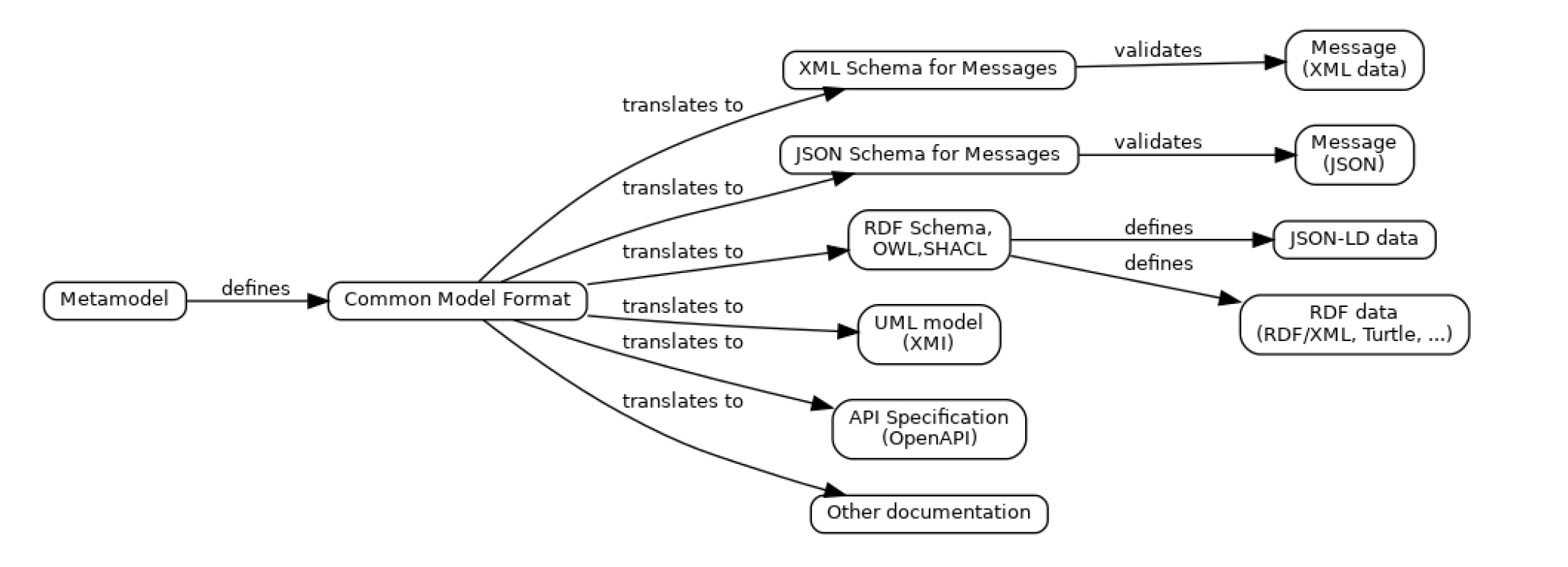{kind=link}
OWL based RDF. Use a tool like Protege (from Stanford University) to prove it. All other (meta)model formats can generate from it.
Isn't it about time that NIEM lives up to it's by-line "...a community-driven, standards-based approach to exchanging information" by joining a community that actually does...linked open data?