 Taekyoon
commented
3 years ago
Taekyoon
commented
3 years ago @changwookjun 님 이 이슈 혹시 봐주실 수 있을까요?
Closed KwonMinho closed 3 years ago
Taekyoon
commented
3 years ago @changwookjun 님 이 이슈 혹시 봐주실 수 있을까요?
 changwookjun
commented
3 years ago
changwookjun
commented
3 years ago 혹시 저장된 경로에 h5 모델이 있는지 그리고 상대 경로와 절대 경로로 인한 이슈는 없는지 확인이 필요 하며 현재 ipynb -> py로 변경하고 있으신데요. 소스 공유 가능하실려나요. 이유는 주피터 노트북에서는 정상적으로 동작하였으나 작성하신 소스에서 문제가 발생하여 검토하기 위함입니다. 좋은 하루되세요.
 KwonMinho
commented
3 years ago
KwonMinho
commented
3 years ago 코드에는 문제가 없는 거 같은데, 주피터 노트북하고 파이썬에서 직접 쓰는 환경의 차이가 있는 거 같아요. 일단은 학습하는데 무리는 없는 거 같아서, 넘어가기로 했습니다. 답변해주셔서 감사합니다 !
에폭 30로 트레이닝 후에, 저장된 weights hdf5로 다시 불러와서 테스트해볼려고하는데 아래 그림과 같은 에러가 발생합니다.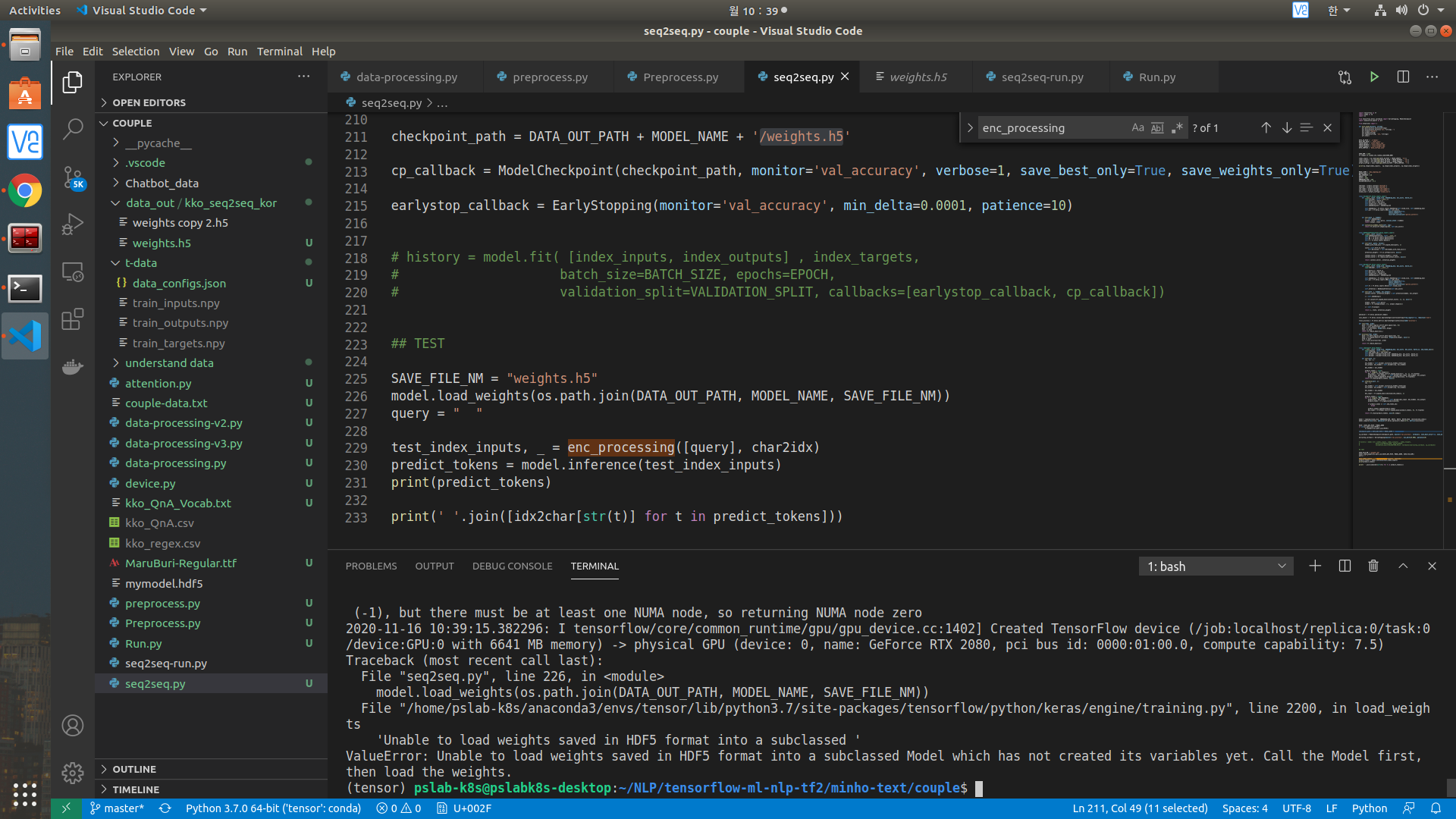
아래는 실행한 소스코드입니다. 계속 질문해서 죄송합니다 ㅠㅠ.