 darylrobbins
commented
9 years ago
darylrobbins
commented
9 years ago I have started a Deployment page on the wiki, so we can build up the documentation in this area. I will start to state some of my assumptions/questions and then @GUI can validate them.
 dmolina-ot
dmolina-ot GUI
GUI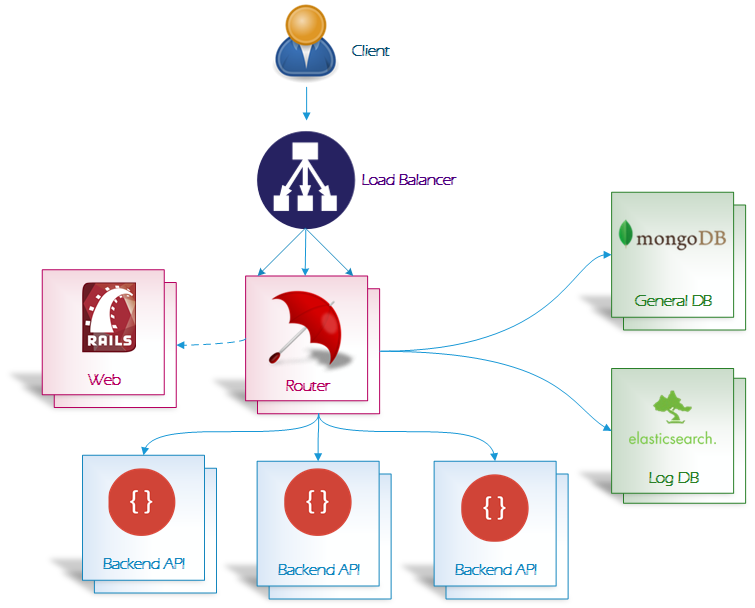{kind=link}
As a server administrator I would like brief installation instructions So that I can prepare a server and install API Umbrella
Details
While we have great packaging and a Deploying from Git page, we do not have a specific page for Installing. An Installing page is somewhat conventional for project documentation, and is often included, for example, as INSTALL.txt.
Task
Lets put together a brief installation document for the Documentation section.