 bwanglzu
commented
5 years ago
bwanglzu
commented
5 years ago @denisb411 take a look at this image, you'll get the point:
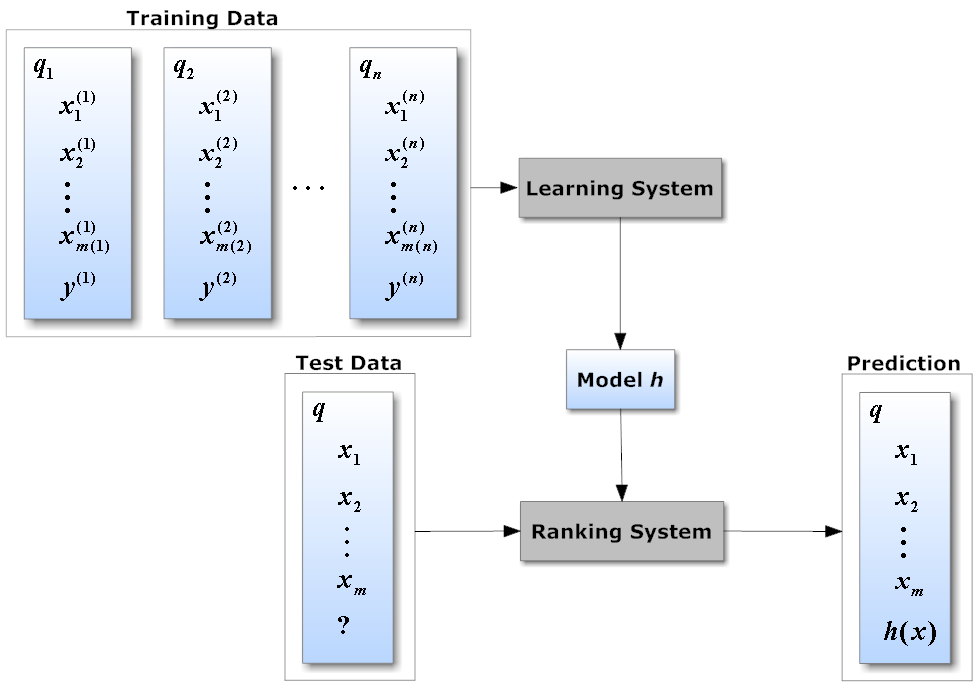
Basically:
- Train your model using training data (the training data consist of query-document-label triple).
- Load the trained model.
- For each new query, do pre-processing.
- Use the trained model to predict the similarity score between pre-processed query and each document, result in a score list.
- Sort the score list.
 denisb411
denisb411 datistiquo
datistiquo yangliuy
yangliuy
I see that the models usually needs a text1 and text2 to perform the training and predictions. Usually on search engines I just need the text2 (document) to perform the indexing step (training).
How can I train the model like a search engine? i.e. I don't have the text1 information (query/question) and I want to index my documents.
Does using the same text for text1 and text2 works for training?