 sjeaugey
commented
4 years ago
sjeaugey
commented
4 years ago Could it be that you are running Xorg on one of the GPUs, so that when TF/NCCL runs, Xorg struggles to get access to the GPU ? If so (and if it easy to try), could you try running Xorg on the CPU integrated GPU and see if the problem is still there ?
I don't think NCCL or TF have much control over how the GPU is shared between CUDA compute and Xorg, so you might want to look for driver configuration. Note however that sharing the GPU between Xorg and TF might affect performance negatively as every time Xorg would get a time slice of one GPU, it would stop TF completely on that GPU, and eventually slow down the other GPU as well as the two GPUs are synchronized. I don't see why NVLink would make a difference in behavior, aside from the fact that it might run much faster, hence make it harder for Xorg to get GPU resources.
 AlexWang1900
AlexWang1900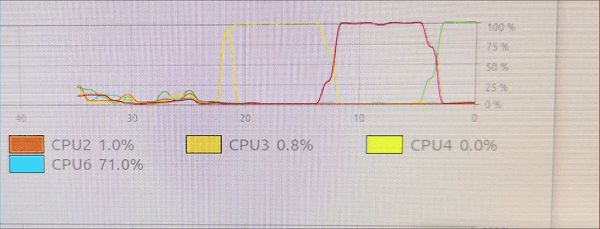
Linux: Ubuntu 20.04 LTS GPU driver: newest NVidia driver for linux. CUDA 10.1, CUDNN ,7.6.5 NCCL 2.6.4 Hardware : CPU: Intel 9400f, MB: Z370,Ram : 64GB 2-channel, GPU: 2 2080ti on 2 PCIE 3.0 *8, with a NVlink bridge between them
I ran all nccl_tests, it seems NCCL is working. But when each test running(about 30 min for each test), the system freezes, I can't switch to browser or doing anything, I can only move the mouse, but the system doesn't respond to mouse-clicking or keyboard input. when the test finishes running, system goes back to normal ,and LOG prints in console.
log is here:
originally I found this issue with training with Tensorflow, I first submit bug to TENSORFLOW , here is the link:https://github.com/tensorflow/tensorflow/issues/40027
it shows when I remove NVLINK BRIDGE, the TF code runs well , and when I using NVLINK BRIDGE, but not using NCCL, the TF code runs well too. but when I using NCCL and NVLINK BRIDGE, the system halt, make me have to reboot.