 mintar
commented
4 years ago
mintar
commented
4 years ago The camera info published by the realsense camera looks correct.
However, the dimensions are wrong. The config_pose.yaml file expects centimeters, and you chair is definitely not 2147 x 3258 x 2171 centimeters big. Maybe multiply it with the 0.03 value from the fixed_model_transform?
By the way: Don't take photos from your mobile phone if possible.
- If it's text, like in the terminal, it's better to copy-paste that text. You can surround it with triple backticks to format it nicely (google "markdown code block").
- If it's an image topic, you can run
rosrun image_view image_saver image:=<your image topic>to directly save images.
 Ademord
Ademord TontonTremblay
TontonTremblay



 The Belief maps generated:
The Belief maps generated:








 I dont know how to make the mesh that overlays smaller, nor zoom out..... I couldnt take a screenshot where the chair mesh showing on the left, but it covers the entire camera window.
I dont know how to make the mesh that overlays smaller, nor zoom out..... I couldnt take a screenshot where the chair mesh showing on the left, but it covers the entire camera window.









I am trying to train on some chairs, for which I setup 4 different photorrealistic scenes in UE4.
My dataset is made of 20k images per location in the scene, being 20k x 5 x 4 = 400k images.
A sample of what my dataset looks like:
Right now the export size is 512x512. Should I be increasing the size of the pictures the Network takes in? I have an OrbitalMovement in the camera that goes from 200 to 500, so I get some really close up photos and some distant ones, as shown here: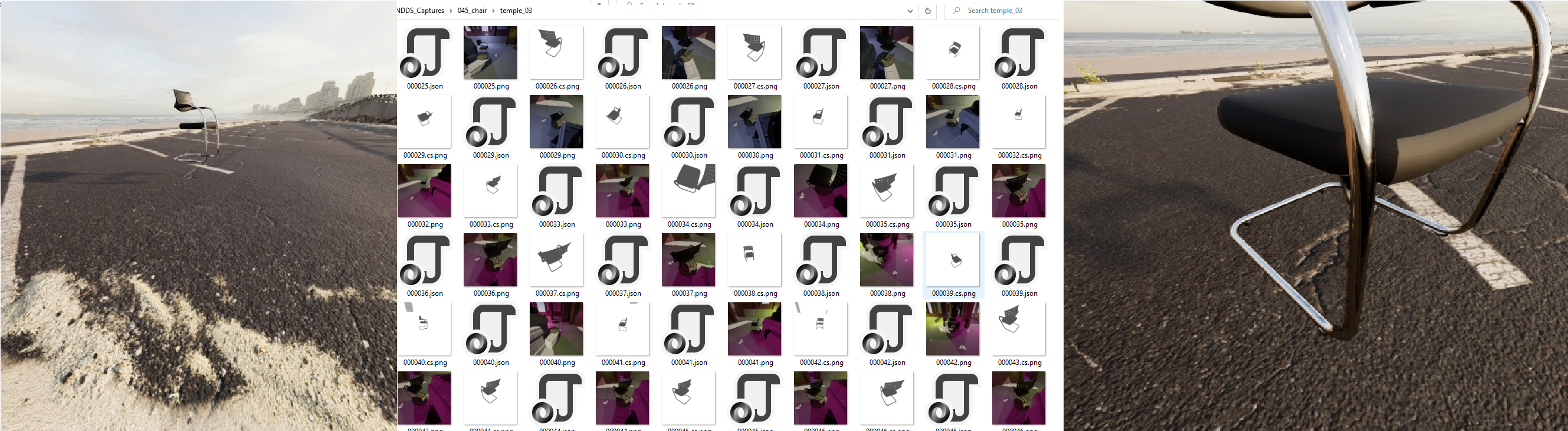
Examples of the pictures that ROS is seeing are:
Some questions that are cluttering my mind:
Am I taking too many angles from the object?
Additional Side info:
Comment any of these lines to prevent detection / pose estimation of that object
weights: {
"cracker":"package://dope/weights/cracker_60.pth",
}
Cuboid dimension in cm x,y,z
dimensions: { "cracker": [16.403600692749023,21.343700408935547,7.179999828338623], "gelatin": [8.918299674987793, 7.311500072479248, 2.9983000755310059], "meat": [10.164673805236816,8.3542995452880859,5.7600898742675781], "mustard": [9.6024150848388672,19.130100250244141,5.824894905090332], "soup": [6.7659378051757813,10.185500144958496,6.771425724029541], "sugar": [9.267730712890625,17.625339508056641,4.5134143829345703], "bleach": [10.267730712890625,26.625339508056641,7.5134143829345703], "banana": [19.717399597167969, 3.8649001121520996, 7.4065999984741211], "chair": [64.41, 97.75, 65.13], "teat": [605.098388671875, 362.48529052734375, 337.88888549804688], }
class_ids: { "cracker": 1, "gelatin": 2, "meat": 3, "mustard": 4, "soup": 5, "sugar": 6, "banana": 7, "chair": 8, "teat": 9, }
draw_colors: { "cracker": [13, 255, 128], # green "gelatin": [255, 255, 255], # while "meat": [0, 104, 255], # blue "mustard": [217,12, 232], # magenta "soup": [255, 101, 0], # orange "sugar": [232, 222, 12], # yellow "banana": [232, 222, 12], # yellow "chair": [232, 222, 12], # yellow "teat": [232, 222, 12], # yellow }
optional: provide a transform that is applied to the pose returned by DOPE
model_transforms: {
"cracker": [[ 0, 0, 1, 0],
[ 0, -1, 0, 0],
[ 1, 0, 0, 0],
[ 0, 0, 0, 1]]
}
optional: if you provide a mesh of the object here, a mesh marker will be
published for visualization in RViz
You can use the nvdu_ycb tool to download the meshes: https://github.com/NVIDIA/Dataset_Utilities#nvdu_ycb
meshes: {
"cracker": "file://path/to/Dataset_Utilities/nvdu/data/ycb/aligned_cm/003_cracker_box/google_16k/textured.obj",
"gelatin": "file://path/to/Dataset_Utilities/nvdu/data/ycb/aligned_cm/009_gelatin_box/google_16k/textured.obj",
"meat": "file://path/to/Dataset_Utilities/nvdu/data/ycb/aligned_cm/010_potted_meat_can/google_16k/textured.obj",
"mustard": "file://path/to/Dataset_Utilities/nvdu/data/ycb/aligned_cm/006_mustard_bottle/google_16k/textured.obj",
"soup": "file://path/to/Dataset_Utilities/nvdu/data/ycb/aligned_cm/005_tomato_soup_can/google_16k/textured.obj",
"sugar": "file://path/to/Dataset_Utilities/nvdu/data/ycb/aligned_cm/004_sugar_box/google_16k/textured.obj",
"bleach": "file://path/to/Dataset_Utilities/nvdu/data/ycb/aligned_cm/021_bleach_cleanser/google_16k/textured.obj",
}
optional: If the specified meshes are not in meters, provide a scale here (e.g. if the mesh is in centimeters, scale should be 0.01). default scale: 1.0.
mesh_scales: { "cracker": 0.01, "gelatin": 0.01, "meat": 0.01, "mustard": 0.01, "soup": 0.01, "sugar": 0.01, "banana": 0.01, "chair": 0.01, "teat": 0.01, }
Config params for DOPE
thresh_angle: 0.5 thresh_map: 0.01 sigma: 3 thresh_points: 0.1