 sejmoonwei
commented
2 years ago
sejmoonwei
commented
2 years ago I got same problems ,maybe we can talk about the following things.
-
Do you use your camera's intrinsics instead of the intrinsics in camera_setting.json in ndds dataset ? I got it from my D435i camera and used for inference.It looks better but still not good.
-
What do you do when generate different poses of your object? I use random rotation/movement , also the background and light in UE4 scene.
-
I found that training on a symmetrical object will cause the loss to stop at a high value ,but DOPE will still give a feasible result when inferencing which may looks right.
-
As the former issue said, nvisii works better than NDDS. Now I'm working on nvisii to see if it works.
 andrei91ro
andrei91ro
Hello,
First of all congratulations for your hard work on DOPE and NDDS!
I used NDDS to generate a dataset of 20K images by following the instructions from the wiki. The dataset looks good even when loaded using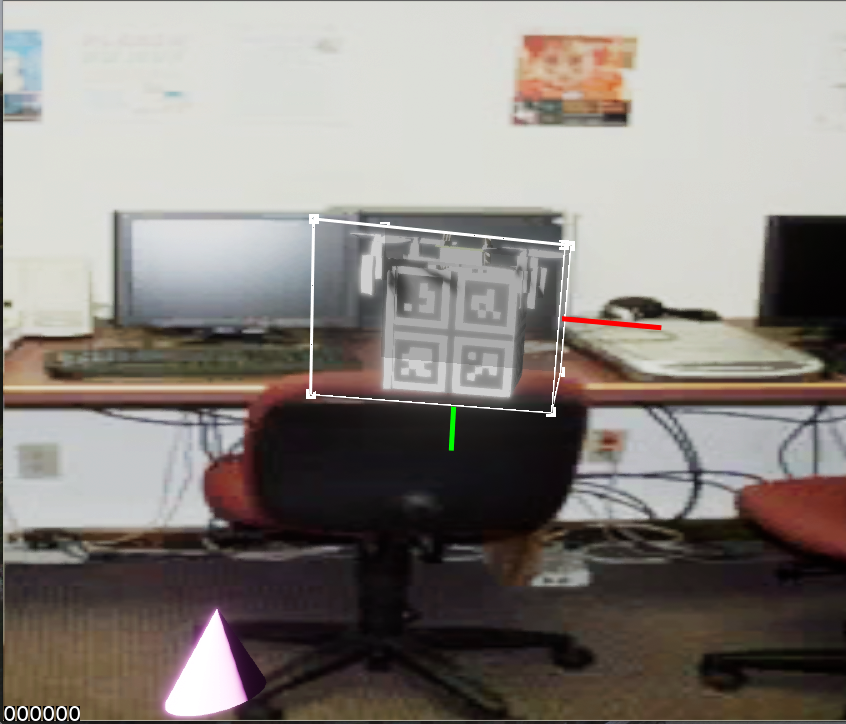
nvdu_vizSince I don't yet have the real object assembled (a Crazyflie drone with a QR code beneath), I tried to point the webcam towads my monitor where one of the training images was displayed. Nothing happend unfortunately.
Afterwards, I tried using the ROS
image_publishernode to stream a single image as a webcam stream and thus avoid the occasional noise that was caused by the monitor refresh rate. I also published thecamera_infotopic along with theimage_raw.However, even when provided with a clear static image, the model does not detect the custom object:
At this point, I don't know the cause of my problems so any expert advice on this matter is highly appreciated :)
My possible theories are that:
image_publisherIf anyone wants to try out the dataset I can provide it. Since this work is part of a research project, I intend to write a white paper on the exact training steps and hiccups along the way and publish it on Github along with all of the required training data.