 Tom94
commented
2 years ago
Tom94
commented
2 years ago Hi there, thanks for calling this out!
"Fully fused" means that all operations of the MLP have been fused into a single GPU kernel, with the implication that (almost) all of the memory traffic happens close to the chip -- so in memory like registers, shared mem, and caches rather than RAM.
Most frameworks perform some degree of operator fusion automatically (e.g. matmul+activation), but usually not full fusion.
Quick summary of why this is important: in MLPs with width W, memory bandwidth is O(W) and compute is O(W^2). For small MLPs like those used in neural graphics primitives, the quadratic term (compute) isn't so much bigger than the linear term (bandwidth), and our GPUs tend to be much better at compute than bandwidth, so the constant factors turn the tides. Ergo: fully fused MLPs attack the memory bottleneck than otherwise plagues really small neural networks.
Here's a figure that explains more details
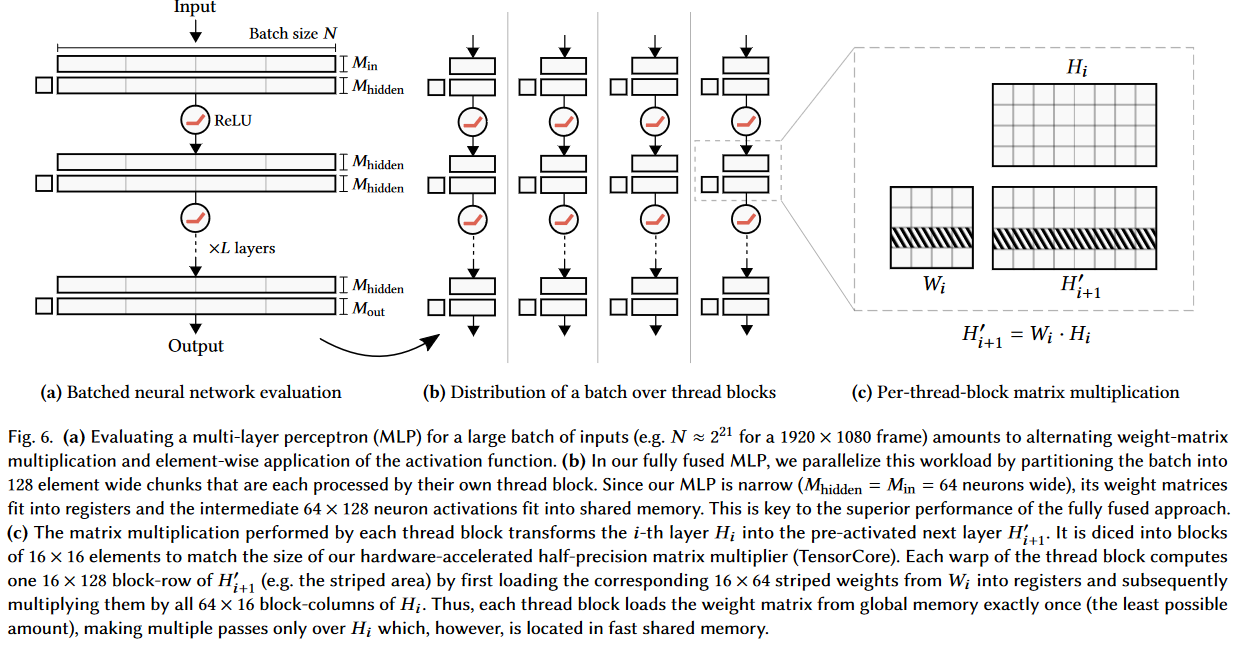
And for yet more details, see this paper
Gonna leave the issue open as a reminder to myself for making this clearer in the README. :)
What does "fully fused" actually mean?
I can't find a technical definition of this anywhere.
Why is this faster/ideal?
How is this different to pytorch/jax/TF2?