 jjy0918
commented
2 years ago
jjy0918
commented
2 years ago 카프카의 특징
- 높은 처리량
- 하나의 커넥션에 하나의 데이터만 전달하는 것이 아니라 데이터를 묶어 전달하기 때문에 효율적이다!
- 확장성
- 카프카는 환겨에 따라 안정적으로 Scale-in, Sacle-out이 가능하다!
- 영속성
- 카프카는 메모리가 아닌 디스크를 이용하기 때문에 안정적으로 데이터를 처리할 수 있다.
- 혹시 시스템에 장애가 발생하더라도 안정적으로 데이터를 처리할 수 있다.
- 고가용성
- 여러대의 브로커를 통해 데이터를 복제하여 안정적이다.
- 일반적으로 3대 이상의 브로커를 세팅하는 것을 추천한다.
카프카는 어떻게 디스크를 사용해도 빠를까?
- 일반적으로 디스크 보다 메모리가 빠르다.
-
Zero - Copy
-
카프카는
zero-copy라는 전략을 이용한다. -
일반적으로 애플리케이션을 통해 데이터를 전송하게 되면 불필요한 copy가 많이 일어난다.
-
Dist -> buffer -> application -> buffer -> network

-
zero-copy는 이러한 불필요한 copy 작업을 제거하여 I/O 속도를 향상시킨다.
-

- LZ4, SNAPPY, GZIP 등을 통한 압축
- 순자 접근
- 일반적으로 메모리가 디스크보다 매우 빠른 것은
Random Access이다. Sequential Access에서는 메모리와 디스크 속도 차이가 크지 않다!?- kafka는 Disk를
Sequential Access하기 때문에 큰 속도 차이를 보이지 않을 수 있다. - GC 최소화
- kafka는 JVM 위에서 실행되기 때문에 GC가 실행되면 비효율적이다.
- 일반적으로 메모리가 디스크보다 매우 빠른 것은
참고: https://cloudnweb.dev/2019/05/heres-what-makes-apache-kafka-so-fast-kafka-series-part-3/ https://preparingforcodinginterview.wordpress.com/2019/10/04/kafka-3-why-is-kafka-so-fast/
느낌
바이트 코드? 바이너리 코드?
4p) 카프카 클라이언트에서는 기본적으로 ByteArray, ByteBuffer, Double, Long, String 타입에 대응한 직렬화, 역직렬화 클래스가 제공된다. 어떤 데이터 포맷이든 직렬화, 역직렬화해서 통신할 수 있다.
(질문) 배치 전송 -> 낮은 지연?
4p) 데이터를 묶음 단위로 처리하는 배치 전송을 통해 낮은 지연과 높은 데이터 처리량을 가진다. -> 총 통신 횟수가 줄어드니까 결국 지연 시간도 줄어든다는 의미?
데이터 웨어하우스(Data Warehouse, DW)
개념
데이터 웨어하우스란 무엇입니까? | 주요 개념 | Amazon Web Services 데이터 웨어하우스 - 위키백과, 우리 모두의 백과사전 사용자의 의사 결정에 도움을 주기 위해, DB에 축적된 데이터를
공통의 형식으로 변환해서 관리하는 데이터베이스통합하는 역할일정 기간의데이터가 존재하게 된다 (특정 시점의 snap shot과 유사하다)다른 키워드와의 비교
데이터 레이크
데이터 마트
카프카 브로커?
카프카 클러스터는 다수의 브로커(서버)로 구성된다고 하는데, 가끔 역할이 헷갈릴 때가 있다. 쉽게 이해할 수 있는 그림! kafka 시스템 구조 알아보기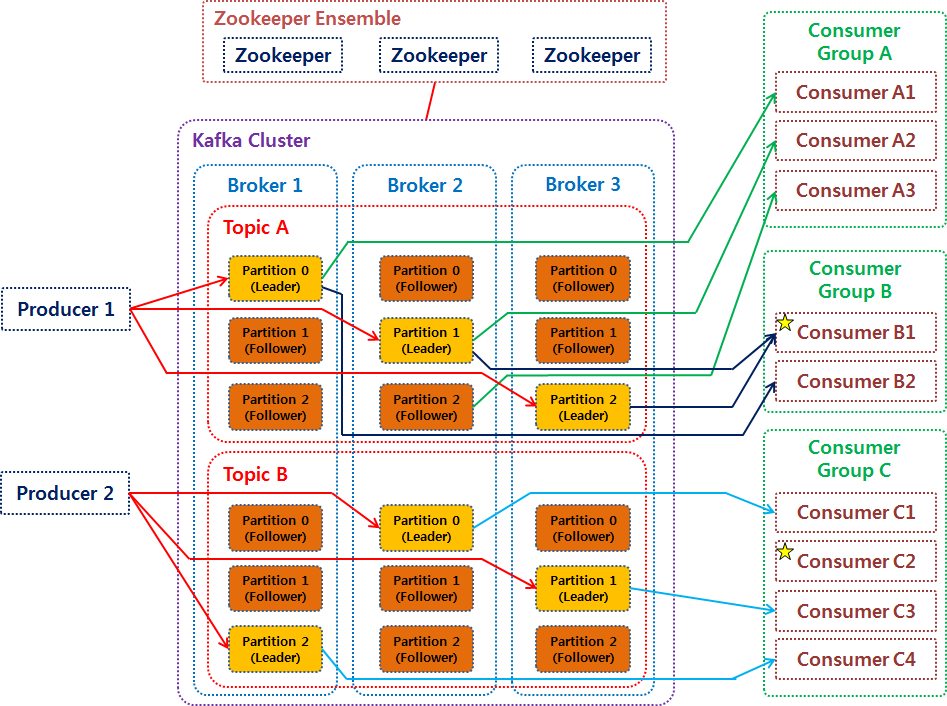
배치 데이터와 스트림 데이터
(12p) 카파 아키텍쳐는 스피드 레이어에서 모든 데이터를 처리하므로 서비스에서 생성되는 모든 종류의 데이터를 스트림 처리해야한다.
특정 기간의 한정된 데이터가 만들어진다. 그래서 시작과 끝이 명확하다. (bounded data)기간이 한정되어 있지 않다(unbounded data, 입력 데이터가 무한하다)