 DGuidi
commented
3 years ago
DGuidi
commented
3 years ago maybe related in someway to #39 and #52 (that were fixed in PR #53? can you add the sample data to test this issue?
Closed RenZachary closed 1 month ago
DGuidi
commented
3 years ago maybe related in someway to #39 and #52 (that were fixed in PR #53? can you add the sample data to test this issue?
 RenZachary
commented
3 years ago
RenZachary
commented
3 years ago maybe related in someway to #39 and #52 (that were fixed in PR #53? can you add the sample data to test this issue?
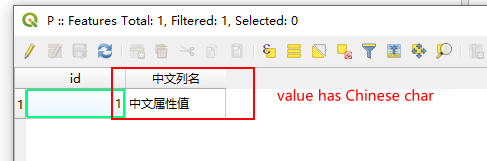
You can use QGIS to create a shapefile layer. When creating it, select the encoding format as GBK, the column header contains Chinese, and the attribute value corresponding to Feature contains Chinese, the problem can be reproduced.
fieldName:中文列名
fieldValue:中文属性值

RenZachary
commented
3 years ago I found some logic problem in DetectEncodingFromMark :
private Encoding DetectEncodingFromMark(byte lcid, string cpgFileName)
{
Encoding enc;
if (LdidToEncoding.TryGetValue(lcid, out enc))
return enc;
enc = Encoding.UTF8;
if (String.IsNullOrEmpty(cpgFileName))
return enc;
cpgFileName = Path.ChangeExtension(cpgFileName, "cpg");
//■■■■■■■■■
//when ".cpg" does not exist, The encoding is utf 8, and the encoding specified by the user in the constructor is not considered
//■■■■■■■■■
if (!File.Exists(cpgFileName))
cpgFileName = Path.ChangeExtension(cpgFileName, "cst");
if (!File.Exists(cpgFileName))
return enc;
string encodingText = File.ReadAllText(cpgFileName).Trim();
try { return Encoding.GetEncoding(encodingText); }
catch { }
return enc;
} mumianhua2008
commented
2 years ago
mumianhua2008
commented
2 years ago 字段名称是中文时乱码现在解决了没有?
DGuidi
commented
2 years ago 字段名称是中文时乱码现在解决了没有?
?
DGuidi
commented
2 years ago You can use QGIS to create a shapefile layer.
please add the test data, and specify the version of the library that you use
RenZachary
commented
2 years ago 修改部分代码,不再依赖.net core,依赖framework 4.6.1 后重新打包解决了
DGuidi
commented
2 years ago Can you post in English?thanks
RenZachary
commented
2 years ago 修改部分代码,不再依赖.net core,依赖framework 4.6.1 后重新打包解决了
Be based on DoNet Framework 4.6.1,then rebuild this project. Modify some codes.
Can you post in English?thanks
DGuidi
commented
2 years ago as you may notice (see the homepage) the development of this project has been discontinued: howewer I will do a check IF you will publish some test data (and not the procedure to generate the wrong data) AND the sample code to reproduce the error (and not the description of the code that should be wrote). thanks.
 KubaSzostak
commented
1 month ago
KubaSzostak
commented
1 month ago We have requested more information regarding this issue, but have not received a response or additional information regarding this issue. Therefore, we are closing this issue.
The attribute column header and value of a shp file I read contain Chinese characters. It is correct using qgis. When using the following two methods to read the column header, the column header is garbled, but the value is read correctly:
or
even
so i rewrite the class
DbaseFileHeader,change the functionpublic void ReadHeader(BinaryReader reader, string filename)to:Actually I just rewrite the code
_encoding = DetectEncodingFromMark(lcid, filename);to :_encoding = this.Encoding;Then I can get the header correctly by using Encoding with PageCode=936.