 jaanli
commented
1 year ago
jaanli
commented
1 year ago This is amazing work @haydenbspence ! Thank you for following up on our brief discussion about this idea so thoroughly after the Vocabulary Working Group!! Happy to help @onefact as we have been building the COST/PRICE table in consultation with the common data model working group and need this linter as well :)
 TinyRickC137
TinyRickC137 haydenbspence
haydenbspence
Describe the problem in content or desired feature
This feature introduces an automated linter for community contributions, significantly enhancing the quality control and integration process within the system. Through a series of steps, it standardizes and validates contributions using predefined rules, ensuring alignment with specific templates and the common data model.
How to find it The working branch dbt-contribution is located on a fork of Vocabulary-v5.0.
A minimal working example can be found here for the lint portion.
Expected adjustments A clear and concise description of what you expect the Vocabulary Team to change. If you have collected information in a spreadsheet, please share it with us.
Screenshots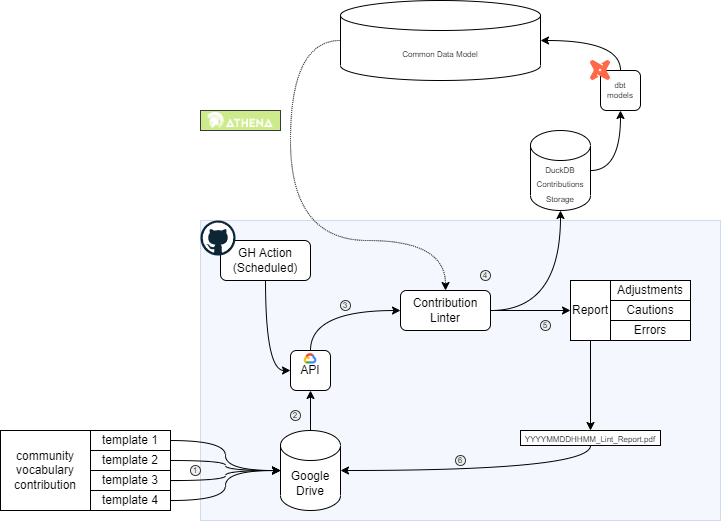
Additional context: Process
1 - The standard process is followed for submitting a community contribution as outlined by the Vocabulary WG 2 - A Github Action on a routine schedule triggers a Service Account to pull submitted Contributions through the GDrive API 3 - The contributions are passed to the Contribution Linter in individual packages (1 contribution = 1 folder = 1 package) 4 - The Contribution Linter is informed by checklists of each template, the common data model, and other prescribed rules. 5 - The Contribution is then stored in a temporary DuckDB flat file which can be later used by dbt models for integration to the CDM 6 - A report is saved to each folder (Contribution) detailing where the Contribution Linter made adjustments (e.g. removing trailing white spaces), if there are an cautions (things the submitter or Voc Team should look into), and if there are any errors (things that would prohibit the contribution from inclusion).
Additional context: Next Steps