 innovation64
commented
11 months ago
innovation64
commented
11 months ago 29th Dec
Waiting for completion
Aiming group
- developers who used the repo(senior engineer)
- novice with code(only want to know how to use it )
- troublemaker (other filed people,maybe will list some fool questions which don't allow basic rules)
Searching and summary
Some tools and bags
- vector db: Weaviate:
- base LLM inference: GPT4 API
- acquire the whole repo: AST tool
Technical route
.png)
Explaination
so this is a basic RAG sys with chat repo
First we need to deal with the user's query
when the user sends a query to the chatbot, we need base history and the query, to judge if it fits the rules. if it fits the rules, we will compress the history find the relevant info about this query, and plus it. chunk and vectorize them, send them to vector db retrieval relevant repo and md vector. ---we call it setp1 if not fit the rules, send it to LLM to rebuild the query too short enlarge it too long summary it not logic, smooth it, change it in a better way. then repeat step 1.
Second chunk the repo files
there are lots of files, we need to summarize, plus the MD(repoAgent generated) file as a summary index Then put the whole project chunk into detail as a whole vector store
Matching
Step1's outputs retrieval with a summarized index vector(filter function), then matching the detail vector.
Reranking
find the top relevant infor
Result
send the relevant infor and query to the LLM ,sign it the source id/hook. generated an answer with the reference.
Details with code
-
Users query
-
define a prompt: what is a good question ?
LLM functioncall outputs a good question
-
then compress history diolouge
LLM functioncall depresses it (tokens based on the LLM model capability)
-
vectorize llamaindex chunk the content
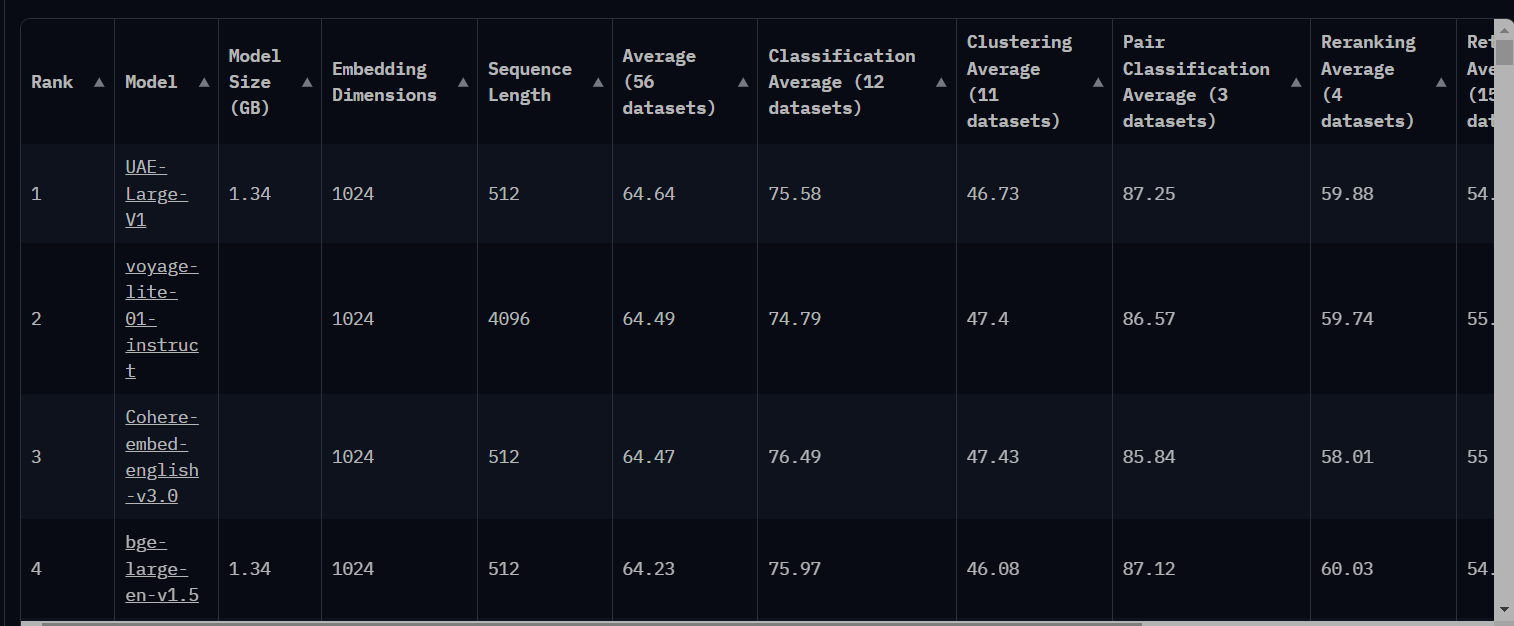 voyager SEO for vectorizing
send it to the vector db
voyager SEO for vectorizing
send it to the vector db -
searching index current algorithms:
- flat index
- faiss,nmslib,knn,fixed tree and HNSW selected db solution:
-
Chroma:
- Focus: May specialize in specific types of data handling or querying capabilities.
- Use Cases: Ideal for scenarios where its specialized focus aligns with your project needs.
- Performance: Depending on its specialization, it might offer enhanced performance in certain tasks.
- Integration and Scalability: How well it integrates with existing systems and scales with data growth.
-
Pinecone:
- Focus: Known for its efficient similarity search in high-dimensional spaces.
- Use Cases: Excellent for recommendation systems, image and text similarity searches.
- Performance: Offers high-performance similarity search with low latency.
- Integration and Scalability: Easily integrates with various data pipelines and scales well.
-
Weaviate:
- Focus: Emphasizes semantic search and automatic classification using machine learning models.
- Use Cases: Suitable for projects requiring semantic understanding, like natural language processing tasks.
- Performance: Good at handling complex queries with a semantic component.
- Integration and Scalability: Supports GraphQL, RESTful APIs, and has good scalability.
-
-
repo part separate it into two parts
- MD
- .py
- Hierarchical indices(just for .py)
-
Reranking & filtering llamaindex
-
topk
-
fed to LLM put the query and relevant info with retrieval outputs to LLM, remember to sign .py vector source
-
result
generated a format result with reference
ps: answer by GPT4 对于代码生成和匹配的场景,选择合适的向量数据库需要考虑几个关键因素,如数据类型、查询性能、以及对特定代码语言结构的支持。根据您的描述,这里是对 Chroma、Pinecone 和 Weaviate 在这方面的潜在适用性的分析:
Chroma:
- 如果 Chroma 对代码数据类型有特殊处理或优化,它可能适合处理代码库。
- 评估它在处理和索引代码相关数据方面的效能。
Pinecone:
- Pinecone 在处理高维空间数据时的性能优势可能对于代码片段的相似性搜索很有帮助。
- 考虑其在快速检索大量代码数据时的能力。
Weaviate:
- Weaviate 的语义搜索能力可能对理解和匹配代码的语义结构特别有用。
- 如果您的应用涉及到理解代码的意图或功能,Weaviate 可能更合适。
针对代码生成和匹配选择数据库:
- 语义理解:如果您的应用需要深入理解代码的意图或功能,具有强大语义处理能力的数据库(如 Weaviate)可能更适合。
- 相似性搜索:如果您关注于代码片段之间的相似性匹配,那么专注于相似性搜索的数据库(如 Pinecone)可能是更好的选择。
- 数据处理和索引:考虑数据库处理和索引大量代码数据的能力,以及对特定编程语言的支持。
在做出决定之前,您可能还需要考虑其他因素,如易用性、集成性、以及社区和技术支持。建议对有潜力的数据库进行小规模的试验,以评估它们在实际代码生成和匹配场景中的表现。
developer: Yang Lee OctoberFox11
OctoberFox11 LOGIC-10
LOGIC-10 Guo-Zhang
Guo-Zhang Umpire2018
Umpire2018
Chat with Repo 项目要求
核心概念
具体要求
动态更新文档chunks对应的向量
组织文档和代码块
代码整合
处理引用关系
大模型的总结与回答