Open PI-KA-CHU opened 5 years ago
为什么要进行数据切分:
随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题。对于一个大型的互联网应用,每天几十亿的PV无疑对数据库造成了相当高的负载。对于系统的稳定性和扩展性造成了极大的问题。通过数据切分来提高网站性能,横向扩展数据层已经成为架构研发人员首选的方式。
数据库优化的策略
水平切分数据库,可以降低单台机器的负载,同时最大限度的降低了了宕机造成的损失。通过负载均衡策略,有效的降低了单台机器的访问负载,降低了宕机的可能性;通过集群方案,解决了数据库宕机带来的单点数据库不能访问的问题;通过读写分离策略更是最大限度了提高了应用中读取(Read)数据的速度和并发量。
利用merge存储引擎来实现分表(水平分表)
merge引擎实现MySQL分表,这种方法比较适用于没有事先考虑分表,而随着数据量增大,查询速度减慢的情况
merge的要求:
示例
简单的MySQL主从复制:
MySQL垂直分区
MySQL水平分片(sharding)
基于水平分片的三种分库方式和规则
按号段分:如user_id的1~1000对应DB1,1001~200对应DB2...
hash取摸分:对user_id的哈希进行取模(如hash(user_id) % n),n为要分的数据库数量
在认证库中保存数据库配置:建立一个DB,这个DB单独保存user_id到数据库的映射关系,每次访问的时候都先查询下认证库,从而得到user_id存储的DB信息。
分布式数据方案提供功能如下:
哈希取模分片简介:
将用户按照一定的规则(按ID哈希)分组,并把该用户的数据存储到一个数据库分片中,即一个sharding,随着用户的增加,只需要简单的配置一台服务器即可。原理如下图:
获取分片存储的信息如下(先创建一张用户和shard对应的数据表,用于查找用户的shard id,再从对应shard id查找相关数据):
对冷热数据的处理
举例:在一个博客系统中,文章标题,作者,分类,创建时间等,是变化频率慢,查询次数多,而且最好有很好的实时性的数据,我们把它叫做冷数据。而博客的浏览量,回复数等,类似的统计信息,或者别的变化频率比较高的数据,我们把它叫做活跃数据。
处理方法:
MySQL分表分库学习
随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题。对于一个大型的互联网应用,每天几十亿的PV无疑对数据库造成了相当高的负载。对于系统的稳定性和扩展性造成了极大的问题。通过数据切分来提高网站性能,横向扩展数据层已经成为架构研发人员首选的方式。
水平切分数据库,可以降低单台机器的负载,同时最大限度的降低了了宕机造成的损失。通过负载均衡策略,有效的降低了单台机器的访问负载,降低了宕机的可能性;通过集群方案,解决了数据库宕机带来的单点数据库不能访问的问题;通过读写分离策略更是最大限度了提高了应用中读取(Read)数据的速度和并发量。
MySQL分库分表方案
merge引擎实现MySQL分表,这种方法比较适用于没有事先考虑分表,而随着数据量增大,查询速度减慢的情况
merge的要求:
示例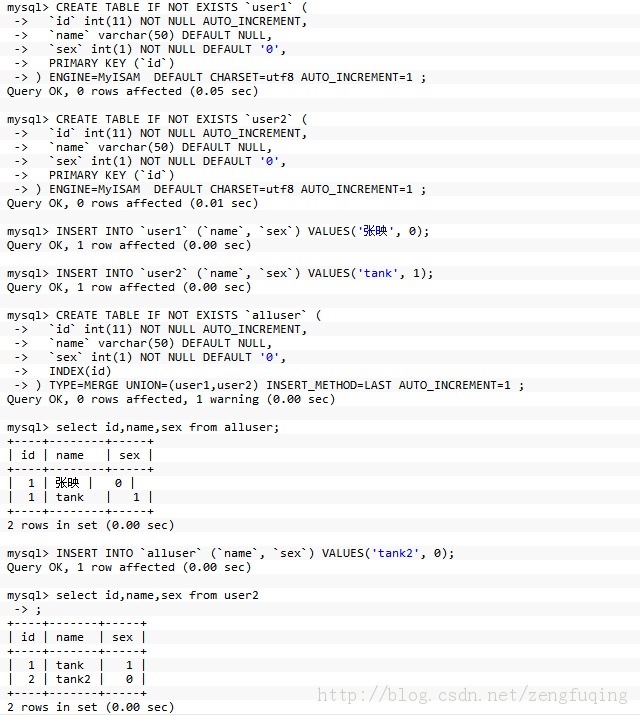
基于水平分片的三种分库方式和规则
按号段分:如user_id的1~1000对应DB1,1001~200对应DB2...
hash取摸分:对user_id的哈希进行取模(如hash(user_id) % n),n为要分的数据库数量
在认证库中保存数据库配置:建立一个DB,这个DB单独保存user_id到数据库的映射关系,每次访问的时候都先查询下认证库,从而得到user_id存储的DB信息。
分布式数据方案提供功能如下:
哈希取模分片简介:
将用户按照一定的规则(按ID哈希)分组,并把该用户的数据存储到一个数据库分片中,即一个sharding,随着用户的增加,只需要简单的配置一台服务器即可。原理如下图: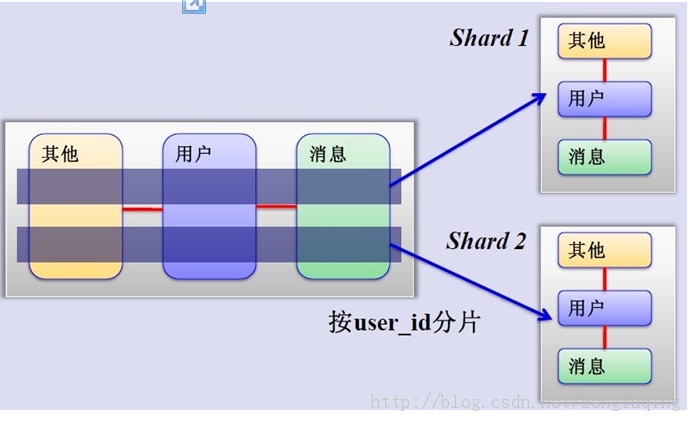
获取分片存储的信息如下(先创建一张用户和shard对应的数据表,用于查找用户的shard id,再从对应shard id查找相关数据):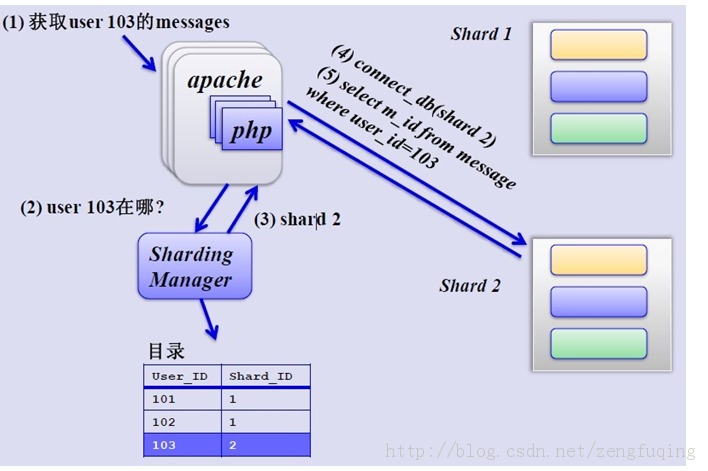
举例:在一个博客系统中,文章标题,作者,分类,创建时间等,是变化频率慢,查询次数多,而且最好有很好的实时性的数据,我们把它叫做冷数据。而博客的浏览量,回复数等,类似的统计信息,或者别的变化频率比较高的数据,我们把它叫做活跃数据。
处理方法:
参考