 sandyhouse
commented
4 years ago
sandyhouse
commented
4 years ago 请问你的基线是什么,相对于基线做了什么修改?
Closed hubu-wangpei closed 4 years ago
sandyhouse
commented
4 years ago 请问你的基线是什么,相对于基线做了什么修改?
 hubu-wangpei
commented
4 years ago
hubu-wangpei
commented
4 years ago 请问你的基线是什么,相对于基线做了什么修改?
在AlexNet的基础上,又增加了几层卷积层。可以说是重新设计网络结构了,下面是这个网络的结构图
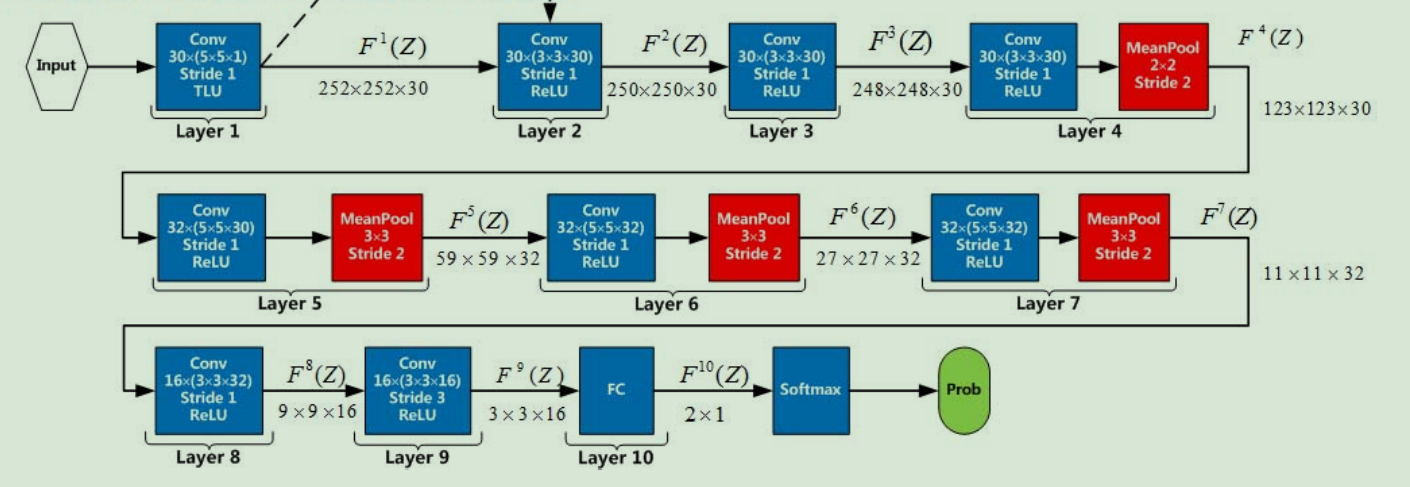
我是根据别人的tensorflow版本改的,但是一直出现上面的情况。尝试过下面这些方法,还是无法解决,还有什么情况会导致这样的结果?
1 训练数据需要打乱,要检查每此batch是否都是一个类别,如果是,则没有办法优化; 2 检查网络是不是没有回传梯度,而是只做了前向运算; 3 检查输入数据是否有做标准化,可能直接传入 0∼255 像素进去了; 4 二分类问题中 0.5 的 acc 接近随机猜测的值,可以检查下标签是否标错; 5 检查参数有没有初始化; 6检查第一层的卷积输出是否正常,是不是全 0 之类的; 7 尝试不同的 Learning Rate;
sandyhouse
commented
4 years ago 二分类问题的类别数不应该数2吗,为什么全连接层参数的ouput_dim设置为1: self.fc1 = Linear(input_dim=144, output_dim=1)
 parap1uie-s
commented
4 years ago
parap1uie-s
commented
4 years ago 二分类问题的类别数不应该数2吗,为什么全连接层参数的ouput_dim设置为1: self.fc1 = Linear(input_dim=144, output_dim=1)
二分类问题用一个输出也合理吧,但fc的输出要是sigmoid激活
hubu-wangpei
commented
4 years ago 二分类问题的类别数不应该数2吗,为什么全连接层参数的ouput_dim设置为1: self.fc1 = Linear(input_dim=144, output_dim=1)
二分类问题用一个输出也合理吧,但fc的输出要是sigmoid激活
是的,我这里用的sigmoid,先计算一个类别的概率,再计算另一个。我这里不知道为啥,acc一直在0.5
logits = model(img)
# 进行loss计算
loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label)
avg_loss = fluid.layers.mean(loss)
pred = fluid.layers.sigmoid(logits)
pred2 = pred * (-1.0) + 1.0
有没有试过大一些的学习率,是不是学习太低导致模型更新较慢。或者有没有可复现的数据,我们复现一下看看。 @hubu-wangpei
hubu-wangpei
commented
4 years ago 有没有试过大一些的学习率,是不是学习太低导致模型更新较慢。或者有没有可复现的数据,我们复现一下看看。 @hubu-wangpei
现在使用不了GPU服务器,稍晚一些我试试大一些的学习率。数据集,我公开了用于此次实验的数据集,使用bossbase_cover.zip、S-UNIWARD.zip 这两个压缩包里的图片作为数据集。bossbase_cover.zip里的是原始图像,S-UNIWARD.zip 是载密图像,各4w张。数据集地址为https://aistudio.baidu.com/aistudio/datasetdetail/26700 下面的代码是我划分训练集、验证集、测试集的代码,您可以直使用
import os
import shutil
import random
#path为批量文件的文件夹的路径
steg_path = '/home/aistudio/data/data26700/images_stego'
cover_path= '/home/aistudio/data/data26700/bossbase3'
train_path='/home/aistudio/data/data26700/train'
valid_path='/home/aistudio/data/data26700/valid'
test_path='/home/aistudio/data/data26700/test'
def renamefiles(path,prefix):
#文件夹中所有文件的文件名
file_names = os.listdir(path)
#print(file_names)
for name in file_names:
os.rename(os.path.join(path,name),os.path.join(path,prefix+name))
#print(os.path.join(path,name),"to",os.path.join(path,prefix+name))
#移动整个文件夹下的文件
def movefiles(src_path,percent):
per_train,per_valid,per_test=percent
filenames=os.listdir(src_path)
random.shuffle(filenames)
for i in range(int(per_train*40000)):
src_name=os.path.join(src_path,filenames[i])
dst_name=os.path.join(train_path,filenames[i])
shutil.move(src_name,dst_name)
for i in range(int(per_train*40000),int((per_train+per_valid)*40000)):
src_name=os.path.join(src_path,filenames[i])
dst_name=os.path.join(valid_path,filenames[i])
shutil.move(src_name,dst_name)
for i in range(int((per_train+per_valid)*40000),40000):
src_name=os.path.join(src_path,filenames[i])
dst_name=os.path.join(test_path,filenames[i])
shutil.move(src_name,dst_name)
def dataprocess():
#先修改名字
renamefiles(steg_path,"steg_")
renamefiles(cover_path,"cover_")
if not os.path.exists(train_path):
os.mkdir(train_path)
if not os.path.exists(valid_path):
os.mkdir(valid_path)
if not os.path.exists(test_path):
os.mkdir(test_path)
movefiles(steg_path,[0.6,0.2,0.2])
movefiles(cover_path,[0.6,0.2,0.2])
dataprocess()二分类问题的类别数不应该数2吗,为什么全连接层参数的ouput_dim设置为1: self.fc1 = Linear(input_dim=144, output_dim=1)
二分类问题用一个输出也合理吧,但fc的输出要是sigmoid激活
是的,我这里用的sigmoid,先计算一个类别的概率,再计算另一个。我这里不知道为啥,acc一直在0.5
logits = model(img) # 进行loss计算 loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label) avg_loss = fluid.layers.mean(loss) pred = fluid.layers.sigmoid(logits) pred2 = pred * (-1.0) + 1.0
Paddle 的accuracy算子,是基于topk的,也就是只支持多分类的那个模式… 如果你模型只有一个输出的话,topk(argmax)的值恒为0,因此accuracy的输出,实际上是你数据中标签为0的数量的比例。
这个坑以前我踩过,解决方法是自己写一个正确率计算方法,比如这样:
predict = FL.reduce_sum(FL.cast(predict >= 0.5, "float32"), dim=1, keep_dim=True)
equal_num = FL.equal(predict, FL.cast(label, "float32")) # bool type
accuracy = FL.mean(FL.cast(equal_num, "float32"))二分类问题的类别数不应该数2吗,为什么全连接层参数的ouput_dim设置为1: self.fc1 = Linear(input_dim=144, output_dim=1)
二分类问题用一个输出也合理吧,但fc的输出要是sigmoid激活
是的,我这里用的sigmoid,先计算一个类别的概率,再计算另一个。我这里不知道为啥,acc一直在0.5
logits = model(img) # 进行loss计算 loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label) avg_loss = fluid.layers.mean(loss) pred = fluid.layers.sigmoid(logits) pred2 = pred * (-1.0) + 1.0Paddle 的accuracy算子,是基于topk的,也就是只支持多分类的那个模式… 如果你模型只有一个输出的话,topk(argmax)的值恒为0,因此accuracy的输出,实际上是你数据中标签为0的数量的比例。
这个坑以前我踩过,解决方法是自己写一个正确率计算方法,比如这样:
predict = FL.reduce_sum(FL.cast(predict >= 0.5, "float32"), dim=1, keep_dim=True) equal_num = FL.equal(predict, FL.cast(label, "float32")) # bool type accuracy = FL.mean(FL.cast(equal_num, "float32"))
我改成了两个输出,
logits = model(img)
am=fluid.layers.argmax(logits,1)
equal=fluid.layers.equal(am,label[0])
avg_acc=fluid.layers.reduce_mean(fluid.layers.cast(equal,np.float32))训练了5个epoch,正确率还是0.5,loss还是在0.69左右,,先不管正确率了,loss跟正确率没关系吧?怎么改loss也是在0.69附近
sandyhouse
commented
4 years ago 另外,你这个模型的出处在哪里,原始模型在数据集上的训练效果是什么样的? @hubu-wangpei
hubu-wangpei
commented
4 years ago 另外,你这个模型的出处在哪里,原始模型在数据集上的训练效果是什么样的? @hubu-wangpei
出处是一个tensorflow模型 YeNet,训练6 、7个epoch后正确率就有70%多了,
sandyhouse
commented
4 years ago 你先做一下对齐吧,比如初始化参数和模型结构。如果和TF实现对齐后精度还是有问题,可以抛出来一起看一下。 @hubu-wangpei
hubu-wangpei
commented
4 years ago 你先做一下对齐吧,比如初始化参数和模型结构。如果和TF实现对齐后精度还是有问题,可以抛出来一起看一下。 @hubu-wangpei
是不是这里的loss计算的有问题,我这样写有错吗,模型的输出是两个值,batch_size为10,那么logits 的shape为[10,2],而label的shape为[10,1] 即[[0],[1]....]这个样子,然后我下面用的softmax_with_cross_entropy(logits,label) ,这样是不是不对?
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
label=fluid.layers.cast(label,np.int64)
#label=fluid.one_hot(label,2)
# 运行模型前向计算,得到预测值
logits = model(img)
# 进行loss计算
loss = fluid.layers.softmax_with_cross_entropy(logits, label)
我手动算了了一下,交叉熵算的没错。这个任务的数据集是原始图片和隐写图片,隐写图片采用的自适应隐写算法,导致隐写图片和原始图片的很多统计特征都很相似。所以我弄的这个模型的输出值是两个很接近的数值。
softmax_with_cross_entropy(logits,label)的写法是对的。如果隐写图像和原始图像的很多统计特征相似的话,的确有可能导致分类不准确。TF的实现也是用的同样的数据集吗?
hubu-wangpei
commented
4 years ago softmax_with_cross_entropy(logits,label)的写法是对的。如果隐写图像和原始图像的很多统计特征相似的话,的确有可能导致分类不准确。TF的实现也是用的同样的数据集吗?
是用的同样的数据集
sandyhouse
commented
4 years ago 出处是一个tensorflow模型 YeNet,训练6 、7个epoch后正确率就有70%多了
如果所有的实现细节,包括数据预处理,模型结构、参数初始化等过程都是和TF对齐的,那么理论上准确率也应该是基本持平的。方面打包贴一下对齐后的代码吗,我们复现一下结果。
hubu-wangpei
commented
4 years ago 出处是一个tensorflow模型 YeNet,训练6 、7个epoch后正确率就有70%多了
如果所有的实现细节,包括数据预处理,模型结构、参数初始化等过程都是和TF对齐的,那么理论上准确率也应该是基本持平的。方面打包贴一下对齐后的代码吗,我们复现一下结果。
原tensorflow模型 YeNet,我公开了用于此次实验的数据集,使用bossbase_cover.zip、S-UNIWARD.zip 这两个压缩包里的图片作为数据集。bossbase_cover.zip里的是原始图像,S-UNIWARD.zip 是载密图像,各4w张。数据集地址为https://aistudio.baidu.com/aistudio/datasetdetail/26700。 处理数据集的代码
import os
import shutil
import random
#path为批量文件的文件夹的路径
steg_path = '/home/aistudio/data/data26700/images_stego'
cover_path= '/home/aistudio/data/data26700/bossbase3'
train_path='/home/aistudio/data/data26700/train'
valid_path='/home/aistudio/data/data26700/valid'
test_path='/home/aistudio/data/data26700/test'
def renamefiles(path,prefix):
#文件夹中所有文件的文件名
file_names = os.listdir(path)
#print(file_names)
for name in file_names:
os.rename(os.path.join(path,name),os.path.join(path,prefix+name))
#print(os.path.join(path,name),"to",os.path.join(path,prefix+name))
#移动整个文件夹下的文件
def movefiles(src_path,percent):
per_train,per_valid,per_test=percent
filenames=os.listdir(src_path)
random.shuffle(filenames)
for i in range(int(per_train*40000)):
src_name=os.path.join(src_path,filenames[i])
dst_name=os.path.join(train_path,filenames[i])
shutil.move(src_name,dst_name)
for i in range(int(per_train*40000),int((per_train+per_valid)*40000)):
src_name=os.path.join(src_path,filenames[i])
dst_name=os.path.join(valid_path,filenames[i])
shutil.move(src_name,dst_name)
for i in range(int((per_train+per_valid)*40000),40000):
src_name=os.path.join(src_path,filenames[i])
dst_name=os.path.join(test_path,filenames[i])
shutil.move(src_name,dst_name)
def dataprocess():
#先修改名字
renamefiles(steg_path,"steg_")
renamefiles(cover_path,"cover_")
if not os.path.exists(train_path):
os.mkdir(train_path)
if not os.path.exists(valid_path):
os.mkdir(valid_path)
if not os.path.exists(test_path):
os.mkdir(test_path)
movefiles(steg_path,[0.6,0.2,0.2])
movefiles(cover_path,[0.6,0.2,0.2])
dataprocess()对齐后的代码
import cv2
import random
import numpy as np
# 对读入的图像数据进行预处理
def transform_img(img):
img = img[np.newaxis, :]
img = img.astype('float32')
img = img / 255.
img = img * 2.0 - 1.0
return img
# 定义训练集数据读取器
def data_loader(datadir, batch_size=10, mode = 'train'):
# 将datadir目录下的文件列出来,每条文件都要读入
filenames = os.listdir(datadir)
def reader():
if mode == 'train':
# 训练时随机打乱数据顺序
random.shuffle(filenames)
batch_imgs = []
batch_labels = []
#print(filenames[:10])
for name in filenames:
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath,0)
img = transform_img(img)
if name[0] == 'c' :
# c开头的文件名表示载体图片,cover
# 属于负样本,标签为0
label = 0
elif name[0] == 's':
# S开头的是载密图像,属于正样本,标签为1
label = 1
else:
print(name)
raise('Not excepted file name')
# 每读取一个样本的数据,就将其放入数据列表中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 当数据列表的长度等于batch_size的时候,
# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
##########################################################
import os
import random
import paddle
import paddle.fluid as fluid
import numpy as np
DATADIR = '/home/aistudio/work/train'
DATADIR2 = '/home/aistudio/work/valid'
# 定义训练过程
def train(model):
with fluid.dygraph.guard():
print('start training ... ')
model.train()
epoch_num = 5
# 定义优化器
opt = fluid.optimizer.AdadeltaOptimizer(learning_rate=0.003, epsilon=1.0e-6, rho=0.95, parameter_list=model.parameters())
#opt = fluid.optimizer.Momentum(learning_rate=0.001, momentum=0.4, parameter_list=model.parameters())
#opt=fluid.optimizer.SGD(learning_rate=0.001,parameter_list=model.parameters())
# 定义数据读取器,训练数据读取器和验证数据读取器
train_loader = data_loader(DATADIR, batch_size=2, mode='train')
valid_loader = data_loader(DATADIR2,batch_size=2, mode='valid' )
for epoch in range(epoch_num):
accuracies = []
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
#print(x_data,y_data)
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
label=fluid.layers.cast(label,np.int64)
oh_label=fluid.one_hot(label,2)
oh_label=fluid.layers.cast(oh_label,np.int64)
# 运行模型前向计算,得到预测值
logits = model(img)
# 进行loss计算
loss = fluid.layers.softmax_with_cross_entropy(logits, oh_label)
avg_loss = fluid.layers.mean(loss)
pred = fluid.layers.softmax(logits)
# am=fluid.layers.argmax(logits,1)
# equal=fluid.layers.equal(am,label)
# acg_acc=fluid.layers.reduce_mean(fluid.layers.cast(equal,np.float32))
# accuracies.append(acg_acc.numpy())
if batch_id % 100 == 0:
print("after softmax",pred)
print(label)
print(loss)
print("epoch: {}, batch_id: {}, acc is :{} loss is: {}".format(epoch, batch_id,2333, avg_loss.numpy()))
# 反向传播,更新权重,清除梯度
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data, y_data = data
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
label=fluid.layers.cast(label,np.int64)
# 运行模型前向计算,得到预测值
logits = model(img)
loss = fluid.layers.softmax_with_cross_entropy(logits, label)
# 计算预测概率小于0.5的类别
acc = fluid.layers.accuracy(pred, fluid.layers.cast(label, dtype='int64'))
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
# save params of model
fluid.save_dygraph(model.state_dict(), 'mnist')
# save optimizer state
fluid.save_dygraph(opt.state_dict(), 'mnist')
#####################################################
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.layer_helper import LayerHelper
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, BatchNorm, Linear
from paddle.fluid.dygraph.base import to_variable
from paddle.fluid.initializer import NumpyArrayInitializer
class ConvBNLayer(fluid.dygraph.Layer):
def __init__(self,
num_channels,
num_filters,
filter_size,
stride=1,
groups=1,
padding=0,
act='relu'):
"""
name_scope, 模块的名字
num_channels, 卷积层的输入通道数
num_filters, 卷积层的输出通道数
stride, 卷积层的步幅
groups, 分组卷积的组数,默认groups=1不使用分组卷积
act, 激活函数类型,默认act=None不使用激活函数
"""
super(ConvBNLayer, self).__init__()
# 创建卷积层
w_init=fluid.ParamAttr(initializer=fluid.initializer.XavierInitializer(),
regularizer=fluid.regularizer.L2Decay(5e-4))
b_init=fluid.ParamAttr(initializer=fluid.initializer.ConstantInitializer(0.2),
regularizer=None)
self._conv = Conv2D(
num_channels=num_channels,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=padding,
groups=groups,
act=act,
param_attr=w_init,
bias_attr=b_init)
# 创建BatchNorm层
#self._batch_norm = BatchNorm(num_filters, act=act,momentum=0.9)
def forward(self, inputs):
y = self._conv(inputs)
#y = self._batch_norm(y)
return y
class YeNet(fluid.dygraph.Layer):
def __init__(self, name_scope, num_classes=1):
super(YeNet, self).__init__(name_scope)
name_scope = self.full_name()
#Layer1
SRM_kernel=np.load("/home/aistudio/work/SRM_Kernels.npy")
SRM_kernel=np.transpose(SRM_kernel,[3,2,0,1])
w_init=fluid.ParamAttr(initializer=NumpyArrayInitializer(value=SRM_kernel))
b_init=fluid.ParamAttr(initializer=fluid.initializer.ConstantInitializer(0.))
self.conv0 = Conv2D(num_channels=1,
num_filters=30,
filter_size=[5, 5],
param_attr=w_init,
bias_attr=b_init)
#Layer2
self.conv1 = ConvBNLayer(num_channels=30, num_filters=30, filter_size=3, stride=1, padding=0, act='relu')
#Layer3
self.conv2 = ConvBNLayer(num_channels=30, num_filters=30, filter_size=3, stride=1, padding=0, act='relu')
#Layer4
self.conv3 = ConvBNLayer(num_channels=30, num_filters=30, filter_size=3, stride=1, padding=0, act='relu')
self.pool3 = Pool2D(pool_size=2, pool_stride=2, pool_type='avg')
#Layer5
self.conv4 = ConvBNLayer(num_channels=30, num_filters=32, filter_size=5, stride=1, padding=0, act='relu')
self.pool4 = Pool2D(pool_size=3, pool_stride=2, pool_type='avg')
#Layer6
self.conv5 = ConvBNLayer(num_channels=32, num_filters=32, filter_size=5, stride=1, padding=0, act='relu')
self.pool5 = Pool2D(pool_size=3, pool_stride=2, pool_type='avg')
#Layer7
self.conv6 = ConvBNLayer(num_channels=32, num_filters=32, filter_size=5, stride=1, padding=0, act='relu')
self.pool6 = Pool2D(pool_size=3, pool_stride=2, pool_type='avg')
#Layer8
self.conv7 = ConvBNLayer(num_channels=32, num_filters=16, filter_size=3, stride=1, padding=0, act='relu')
#Layer9
self.conv8 = ConvBNLayer(num_channels=16, num_filters=16, filter_size=3, stride=3, padding=0, act='relu')
#Layer10
import math
stdv = 1.0 / math.sqrt(2048 * 1.0)
# 创建全连接层,输出大小为类别数目
self.fc1 = Linear(input_dim=144, output_dim=2,param_attr=fluid.param_attr.ParamAttr(
initializer=fluid.initializer.Normal(loc=0.0, scale=0.01)),bias_attr=b_init)
def forward(self, x):
x=self.conv0(x)
#
x=fluid.layers.clip(x=x, min=-3.0, max=3.0)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.pool3(x)
x = self.conv4(x)
x = self.pool4(x)
x = self.conv5(x)
x = self.pool5(x)
x = self.conv6(x)
x = self.pool6(x)
x = self.conv7(x)
x = self.conv8(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x=self.fc1(x)
return x
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
with fluid.dygraph.guard(place):
model = YeNet("YeNet")
train(model)
能方便吧TF的运行日志也贴一下吗?
hubu-wangpei
commented
4 years ago 能方便吧TF的运行日志也贴一下吗?
晚点发给你,我在重新跑Tensorflow的需要点时间
hubu-wangpei
commented
4 years ago 能方便吧TF的运行日志也贴一下吗?
tensorflow模型,loss在减小
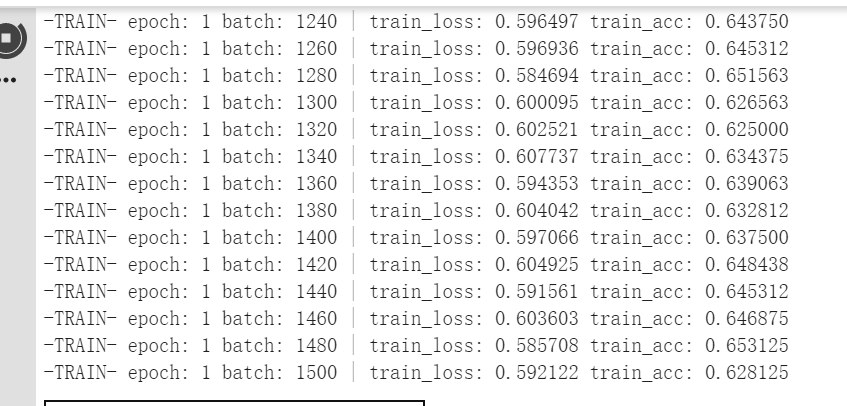
sandyhouse
commented
4 years ago 你的模型实现和TF的实现没有完全对齐呀。 我用你的代码,做了下面的修改:
修改后loss值可以下降,acc值也可以上升。

除此之外,应该还有没对齐的实现,你再仔细看看吧。
hubu-wangpei
commented
4 years ago 你的模型实现和TF的实现没有完全对齐呀。 我用你的代码,做了下面的修改:
- Optimizer做了对齐: opt = fluid.optimizer.AdadeltaOptimizer(learning_rate=4e-1, epsilon=1.0e-8, rho=0.95, parameter_list=model.parameters())
- 图像处理部分做了修改(transform_img): 注释掉下面两行:
img=img/255.0
img=img*2.0 - 1.0
- img = cv2.imread(filepath,0)修改为img = misc.imread(filepath)
修改后loss值可以下降,acc值也可以上升。
除此之外,应该还有没对齐的实现,你再仔细看看吧。
非常感谢,我再仔细看看
hubu-wangpei
commented
4 years ago 你的模型实现和TF的实现没有完全对齐呀。 我用你的代码,做了下面的修改:
- Optimizer做了对齐: opt = fluid.optimizer.AdadeltaOptimizer(learning_rate=4e-1, epsilon=1.0e-8, rho=0.95, parameter_list=model.parameters())
- 图像处理部分做了修改(transform_img): 注释掉下面两行:
img=img/255.0
img=img*2.0 - 1.0
- img = cv2.imread(filepath,0)修改为img = misc.imread(filepath)
修改后loss值可以下降,acc值也可以上升。
除此之外,应该还有没对齐的实现,你再仔细看看吧。
真不知道为啥,我按照您说的修改了,还是那样,您能把您修改后的代码贴一下吗(非常感谢)。
sandyhouse
commented
4 years ago import cv2
import random
from scipy import misc
import numpy as np
def transform_img(img):
img = img[np.newaxis, :]
img = img.astype('float32')
#img = img / 255.0
#img = img * 2.0 - 1.0
return img
def data_loader(datadir, batch_size=10, mode = 'train'):
filenames = os.listdir(datadir)
def reader():
if mode == 'train':
random.shuffle(filenames)
batch_imgs = []
batch_labels = []
for name in filenames:
filepath = os.path.join(datadir, name)
#img = cv2.imread(filepath,0)
img = misc.imread(filepath)
img = transform_img(img)
if name[0] == 'c' :
label = 0
elif name[0] == 's':
label = 1
else:
print(name)
raise('Not excepted file name')
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('int64').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('int64').reshape(-1, 1)
yield imgs_array, labels_array
return reader
import os
import random
import paddle
import paddle.fluid as fluid
import numpy as np
DATADIR = 'xxx'
DATADIR2 = 'xxx'
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.layer_helper import LayerHelper
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, BatchNorm, Linear
from paddle.fluid.dygraph.base import to_variable
from paddle.fluid.initializer import NumpyArrayInitializer
class ConvBNLayer(fluid.dygraph.Layer):
def __init__(self,
num_channels,
num_filters,
filter_size,
stride=1,
groups=1,
padding=0,
act='relu'):
super(ConvBNLayer, self).__init__()
w_init=fluid.ParamAttr(initializer=fluid.initializer.XavierInitializer(),
regularizer=fluid.regularizer.L2Decay(5e-4))
b_init=fluid.ParamAttr(initializer=fluid.initializer.ConstantInitializer(0.2),
regularizer=None)
self._conv = Conv2D(
num_channels=num_channels,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=padding,
groups=groups,
act=act,
param_attr=w_init,
bias_attr=b_init)
self._batch_norm = BatchNorm(num_filters, act=act,momentum=0.9)
def forward(self, inputs):
y = self._conv(inputs)
y = self._batch_norm(y)
return y
class YeNet(fluid.dygraph.Layer):
def __init__(self, name_scope, num_classes=1):
super(YeNet, self).__init__(name_scope)
name_scope = self.full_name()
#Layer1
SRM_kernel=np.load("/home/lilong/issue/issue/SRM_Kernels.npy")
SRM_kernel=np.transpose(SRM_kernel,[3,2,0,1]).astype("float32")
print(SRM_kernel.shape)
w_init=fluid.ParamAttr(initializer=NumpyArrayInitializer(value=SRM_kernel))
b_init=fluid.ParamAttr(initializer=fluid.initializer.ConstantInitializer(0.))
self.conv0 = Conv2D(num_channels=1,
num_filters=30,
filter_size=[1, 1],
param_attr=w_init,
bias_attr=b_init)
#Layer2
self.conv1 = ConvBNLayer(num_channels=30, num_filters=30, filter_size=3, stride=1, padding=0, act='relu')
#Layer3
self.conv2 = ConvBNLayer(num_channels=30, num_filters=30, filter_size=3, stride=1, padding=0, act='relu')
#Layer4
self.conv3 = ConvBNLayer(num_channels=30, num_filters=30, filter_size=3, stride=1, padding=0, act='relu')
self.pool3 = Pool2D(pool_size=2, pool_stride=2, pool_type='avg')
#Layer5
self.conv4 = ConvBNLayer(num_channels=30, num_filters=32, filter_size=5, stride=1, padding=0, act='relu')
self.pool4 = Pool2D(pool_size=3, pool_stride=2, pool_type='avg')
#Layer6
self.conv5 = ConvBNLayer(num_channels=32, num_filters=32, filter_size=5, stride=1, padding=0, act='relu')
self.pool5 = Pool2D(pool_size=3, pool_stride=2, pool_type='avg')
#Layer7
self.conv6 = ConvBNLayer(num_channels=32, num_filters=32, filter_size=5, stride=1, padding=0, act='relu')
self.pool6 = Pool2D(pool_size=3, pool_stride=2, pool_type='avg')
#Layer8
self.conv7 = ConvBNLayer(num_channels=32, num_filters=16, filter_size=3, stride=1, padding=0, act='relu')
#Layer9
self.conv8 = ConvBNLayer(num_channels=16, num_filters=16, filter_size=3, stride=3, padding=0, act='relu')
#Layer10
import math
stdv = 1.0 / math.sqrt(2048 * 1.0)
self.fc1 = Linear(input_dim=144, output_dim=2,param_attr=fluid.param_attr.ParamAttr(
initializer=fluid.initializer.Normal(loc=0.0, scale=0.01)),
bias_attr=b_init)
def forward(self, x):
x=self.conv0(x)
x=fluid.layers.clip(x=x, min=-3.0, max=3.0)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.pool3(x)
x = self.conv4(x)
x = self.pool4(x)
x = self.conv5(x)
x = self.pool5(x)
x = self.conv6(x)
x = self.pool6(x)
x = self.conv7(x)
x = self.conv8(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x=self.fc1(x)
return x
use_cuda = True
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
with fluid.dygraph.guard(place):
model = YeNet("YeNet")
#train(model)
print('start training ... ')
#model.train()
epoch_num = 10
opt = fluid.optimizer.AdadeltaOptimizer(learning_rate=4e-1, epsilon=1.0e-8, rho=0.95, parameter_list=model.parameters())
#print(model.parameters())
#opt = fluid.optimizer.SGD(learning_rate=0.01, parameter_list=model.parameters())
train_loader = data_loader(DATADIR, batch_size=32, mode='train')
valid_loader = data_loader(DATADIR2,batch_size=32, mode='valid' )
for epoch in range(epoch_num):
accuracies = []
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
#print(x_data,y_data)
#print(x_data.shape)
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
label = fluid.layers.cast(label, dtype='int64')
logits = model(img)
#loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label)
loss, pred = fluid.layers.softmax_with_cross_entropy(logits, label, return_softmax=True)
avg_loss = fluid.layers.mean(loss)
#pred = fluid.layers.sigmoid(logits)
#pred2 = pred * (-1.0) + 1.0
#pred = fluid.layers.concat([pred2, pred], axis=1)
acc = fluid.layers.accuracy(pred, fluid.layers.cast(label, dtype='int64'))
accuracies.append(acc.numpy())
if batch_id % 100 == 0:
#print(pred)
#print(label)
#print(loss)
print("epoch: {}, batch_id: {}, acc is :{} loss is: {}".format(epoch, batch_id,np.mean(accuracies), avg_loss.numpy()))
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()import cv2 import random from scipy import misc import numpy as np def transform_img(img): img = img[np.newaxis, :] img = img.astype('float32') #img = img / 255.0 #img = img * 2.0 - 1.0 return img def data_loader(datadir, batch_size=10, mode = 'train'): filenames = os.listdir(datadir) def reader(): if mode == 'train': random.shuffle(filenames) batch_imgs = [] batch_labels = [] for name in filenames: filepath = os.path.join(datadir, name) #img = cv2.imread(filepath,0) img = misc.imread(filepath) img = transform_img(img) if name[0] == 'c' : label = 0 elif name[0] == 's': label = 1 else: print(name) raise('Not excepted file name') batch_imgs.append(img) batch_labels.append(label) if len(batch_imgs) == batch_size: imgs_array = np.array(batch_imgs).astype('float32') labels_array = np.array(batch_labels).astype('int64').reshape(-1, 1) yield imgs_array, labels_array batch_imgs = [] batch_labels = [] if len(batch_imgs) > 0: imgs_array = np.array(batch_imgs).astype('float32') labels_array = np.array(batch_labels).astype('int64').reshape(-1, 1) yield imgs_array, labels_array return reader import os import random import paddle import paddle.fluid as fluid import numpy as np DATADIR = 'xxx' DATADIR2 = 'xxx' import numpy as np import paddle import paddle.fluid as fluid from paddle.fluid.layer_helper import LayerHelper from paddle.fluid.dygraph.nn import Conv2D, Pool2D, BatchNorm, Linear from paddle.fluid.dygraph.base import to_variable from paddle.fluid.initializer import NumpyArrayInitializer class ConvBNLayer(fluid.dygraph.Layer): def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, padding=0, act='relu'): super(ConvBNLayer, self).__init__() w_init=fluid.ParamAttr(initializer=fluid.initializer.XavierInitializer(), regularizer=fluid.regularizer.L2Decay(5e-4)) b_init=fluid.ParamAttr(initializer=fluid.initializer.ConstantInitializer(0.2), regularizer=None) self._conv = Conv2D( num_channels=num_channels, num_filters=num_filters, filter_size=filter_size, stride=stride, padding=padding, groups=groups, act=act, param_attr=w_init, bias_attr=b_init) self._batch_norm = BatchNorm(num_filters, act=act,momentum=0.9) def forward(self, inputs): y = self._conv(inputs) y = self._batch_norm(y) return y class YeNet(fluid.dygraph.Layer): def __init__(self, name_scope, num_classes=1): super(YeNet, self).__init__(name_scope) name_scope = self.full_name() #Layer1 SRM_kernel=np.load("/home/lilong/issue/issue/SRM_Kernels.npy") SRM_kernel=np.transpose(SRM_kernel,[3,2,0,1]).astype("float32") print(SRM_kernel.shape) w_init=fluid.ParamAttr(initializer=NumpyArrayInitializer(value=SRM_kernel)) b_init=fluid.ParamAttr(initializer=fluid.initializer.ConstantInitializer(0.)) self.conv0 = Conv2D(num_channels=1, num_filters=30, filter_size=[1, 1], param_attr=w_init, bias_attr=b_init) #Layer2 self.conv1 = ConvBNLayer(num_channels=30, num_filters=30, filter_size=3, stride=1, padding=0, act='relu') #Layer3 self.conv2 = ConvBNLayer(num_channels=30, num_filters=30, filter_size=3, stride=1, padding=0, act='relu') #Layer4 self.conv3 = ConvBNLayer(num_channels=30, num_filters=30, filter_size=3, stride=1, padding=0, act='relu') self.pool3 = Pool2D(pool_size=2, pool_stride=2, pool_type='avg') #Layer5 self.conv4 = ConvBNLayer(num_channels=30, num_filters=32, filter_size=5, stride=1, padding=0, act='relu') self.pool4 = Pool2D(pool_size=3, pool_stride=2, pool_type='avg') #Layer6 self.conv5 = ConvBNLayer(num_channels=32, num_filters=32, filter_size=5, stride=1, padding=0, act='relu') self.pool5 = Pool2D(pool_size=3, pool_stride=2, pool_type='avg') #Layer7 self.conv6 = ConvBNLayer(num_channels=32, num_filters=32, filter_size=5, stride=1, padding=0, act='relu') self.pool6 = Pool2D(pool_size=3, pool_stride=2, pool_type='avg') #Layer8 self.conv7 = ConvBNLayer(num_channels=32, num_filters=16, filter_size=3, stride=1, padding=0, act='relu') #Layer9 self.conv8 = ConvBNLayer(num_channels=16, num_filters=16, filter_size=3, stride=3, padding=0, act='relu') #Layer10 import math stdv = 1.0 / math.sqrt(2048 * 1.0) self.fc1 = Linear(input_dim=144, output_dim=2,param_attr=fluid.param_attr.ParamAttr( initializer=fluid.initializer.Normal(loc=0.0, scale=0.01)), bias_attr=b_init) def forward(self, x): x=self.conv0(x) x=fluid.layers.clip(x=x, min=-3.0, max=3.0) x = self.conv1(x) x = self.conv2(x) x = self.conv3(x) x = self.pool3(x) x = self.conv4(x) x = self.pool4(x) x = self.conv5(x) x = self.pool5(x) x = self.conv6(x) x = self.pool6(x) x = self.conv7(x) x = self.conv8(x) x = fluid.layers.reshape(x, [x.shape[0], -1]) x=self.fc1(x) return x use_cuda = True place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace() with fluid.dygraph.guard(place): model = YeNet("YeNet") #train(model) print('start training ... ') #model.train() epoch_num = 10 opt = fluid.optimizer.AdadeltaOptimizer(learning_rate=4e-1, epsilon=1.0e-8, rho=0.95, parameter_list=model.parameters()) #print(model.parameters()) #opt = fluid.optimizer.SGD(learning_rate=0.01, parameter_list=model.parameters()) train_loader = data_loader(DATADIR, batch_size=32, mode='train') valid_loader = data_loader(DATADIR2,batch_size=32, mode='valid' ) for epoch in range(epoch_num): accuracies = [] for batch_id, data in enumerate(train_loader()): x_data, y_data = data #print(x_data,y_data) #print(x_data.shape) img = fluid.dygraph.to_variable(x_data) label = fluid.dygraph.to_variable(y_data) label = fluid.layers.cast(label, dtype='int64') logits = model(img) #loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label) loss, pred = fluid.layers.softmax_with_cross_entropy(logits, label, return_softmax=True) avg_loss = fluid.layers.mean(loss) #pred = fluid.layers.sigmoid(logits) #pred2 = pred * (-1.0) + 1.0 #pred = fluid.layers.concat([pred2, pred], axis=1) acc = fluid.layers.accuracy(pred, fluid.layers.cast(label, dtype='int64')) accuracies.append(acc.numpy()) if batch_id % 100 == 0: #print(pred) #print(label) #print(loss) print("epoch: {}, batch_id: {}, acc is :{} loss is: {}".format(epoch, batch_id,np.mean(accuracies), avg_loss.numpy())) avg_loss.backward() opt.minimize(avg_loss) model.clear_gradients()
非常感谢您的指导。
 HeMancute
commented
3 years ago
HeMancute
commented
3 years ago 请问您解决了吗,我也是遇到这个问题,能指导一下吗?
hubu-wangpei
commented
3 years ago 首先你得定位到你出现这个问题的原因,百度查查,如果都解决不了,尝试多跑几个迭代
---原始邮件--- 发件人: "HeMancute"<notifications@github.com> 发送时间: 2020年9月7日(周一) 凌晨0:20 收件人: "PaddlePaddle/Paddle"<Paddle@noreply.github.com>; 抄送: "State change"<state_change@noreply.github.com>;"hubu-wangpei"<602844523@qq.com>; 主题: Re: [PaddlePaddle/Paddle] 复现改造AlexNet,无法收敛,acc一直是0.5左右,检查了很多方面还是找不出问题 (#23501)
请问您解决了吗,我也是遇到这个问题,能指导一下吗?
— You are receiving this because you modified the open/close state. Reply to this email directly, view it on GitHub, or unsubscribe.
HeMancute
commented
3 years ago 跑了600轮了,还是一样,各种调参都没解决
hubu-wangpei
commented
3 years ago 这就不太知道了,我当时是因为跑的太少了
---原始邮件--- 发件人: "HeMancute"<notifications@github.com> 发送时间: 2020年9月7日(周一) 凌晨0:28 收件人: "PaddlePaddle/Paddle"<Paddle@noreply.github.com>; 抄送: "State change"<state_change@noreply.github.com>;"hubu-wangpei"<602844523@qq.com>; 主题: Re: [PaddlePaddle/Paddle] 复现改造AlexNet,无法收敛,acc一直是0.5左右,检查了很多方面还是找不出问题 (#23501)
跑了600轮了,还是一样,各种调参都没解决
— You are receiving this because you modified the open/close state. Reply to this email directly, view it on GitHub, or unsubscribe.
HeMancute
commented
3 years ago 你跑了多少轮
hubu-wangpei
commented
3 years ago 我才跑100个epoch
---原始邮件--- 发件人: "HeMancute"<notifications@github.com> 发送时间: 2020年9月7日(周一) 凌晨0:28 收件人: "PaddlePaddle/Paddle"<Paddle@noreply.github.com>; 抄送: "State change"<state_change@noreply.github.com>;"hubu-wangpei"<602844523@qq.com>; 主题: Re: [PaddlePaddle/Paddle] 复现改造AlexNet,无法收敛,acc一直是0.5左右,检查了很多方面还是找不出问题 (#23501)
跑了600轮了,还是一样,各种调参都没解决
— You are receiving this because you modified the open/close state. Reply to this email directly, view it on GitHub, or unsubscribe.
HeMancute
commented
3 years ago #img = img / 255.0
#img = img * 2.0 - 1.0你注释掉了吗
hubu-wangpei
commented
3 years ago #img = img / 255.0 #img = img * 2.0 - 1.0你注释掉了吗
是的,你也是做隐写分析的吗?加个Q说吧,你加我602844523
HeMancute
commented
3 years ago 有微信吗
HeMancute
commented
3 years ago 嗯
hubu-wangpei
commented
3 years ago 我加你微信吧,你发一下
------------------ 原始邮件 ------------------ 发件人: "HeMancute"<notifications@github.com>; 发送时间: 2020年9月7日(星期一) 凌晨0:42 收件人: "PaddlePaddle/Paddle"<Paddle@noreply.github.com>; 抄送: "hubu-wangpei"<602844523@qq.com>; "State change"<state_change@noreply.github.com>; 主题: Re: [PaddlePaddle/Paddle] 复现改造AlexNet,无法收敛,acc一直是0.5左右,检查了很多方面还是找不出问题 (#23501)
有微信吗
— You are receiving this because you modified the open/close state. Reply to this email directly, view it on GitHub, or unsubscribe.
HeMancute
commented
3 years ago 微信号lfxfcf
 qigang47
commented
8 months ago
qigang47
commented
8 months ago 微信号lfxfcf
兄弟还在不 解决没
如题,根据paddle的教程和图像隐写分析的模型,改造了AlexNet模型。但是在训练的时候,最后的全连接层输出的预测值都是比较小的值,在0附近(下面有图),经过sigmoid函数后的值都在0.5左右。导致acc一直在0.5上下,loss在0.69左右,试过很多网上的方法,都不行。训练集里正反例各一半,训练时,随机读取。下面是具体代码
每一层卷积层又加了bachnorm,但还是不收敛,下面是训练的时候的数据