 shangzhizhou
commented
4 years ago
shangzhizhou
commented
4 years ago C++中未使用TensorRT而python中使用了,请在同样条件下测试看看
Closed QingYuan-L closed 3 years ago
shangzhizhou
commented
4 years ago C++中未使用TensorRT而python中使用了,请在同样条件下测试看看
 QingYuan-L
commented
4 years ago
QingYuan-L
commented
4 years ago 
def create_predictor(args):
config = AnalysisConfig(args.model_file, args.params_file)
config.switch_use_feed_fetch_ops(False)
config.enable_memory_optim()
# config.enable_tensorrt_engine(
# max_batch_size=1, min_subgraph_size=5,
# precision_mode=AnalysisConfig.Precision.Half,
# use_static=True, use_calib_mode=False)
if args.use_gpu:
config.enable_use_gpu(200, 0)
else:
# If not specific mkldnn, you can set the blas thread.
# The thread num should not be greater than the number of cores in the CPU.
config.set_cpu_math_library_num_threads(4)
#config.enable_mkldnn()
predictor = create_paddle_predictor(config)
return predictor@shangzhizhou 已经注释掉trt,显存没有变化
shangzhizhou
commented
4 years ago python执行前export FLAGS_fraction_of_gpu_memory_to_use = 0.1,python的enable_use_gpu显存设置不生效我们已经安排修复中。
 paddle-bot-old[bot]
commented
3 years ago
paddle-bot-old[bot]
commented
3 years ago Since you haven\'t replied for more than a year, we have closed this issue/pr. If the problem is not solved or there is a follow-up one, please reopen it at any time and we will continue to follow up. 由于您超过一年未回复,我们将关闭这个issue/pr。 若问题未解决或有后续问题,请随时重新打开,我们会继续跟进。
1)PaddlePaddle版本:在docker-dev中自己编译的1.8.4 2)GPU:gtx1060 3)系统环境:ubuntu18.04,python3.7 4)预测库来源:in docker latest-dev-cuda10.1-cudnn7-gcc82,正常编译
使用c++: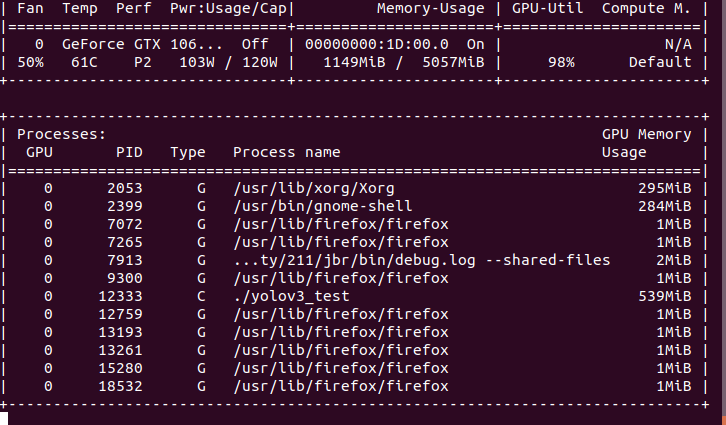
C++代码: