 HolyZheng
commented
6 years ago
HolyZheng
commented
6 years ago 寻寻被试小程序端
1. 登录
采用官方提供的登录能力来获取用户标识,通过JWT(json web token)来保持登录状态,流程图:
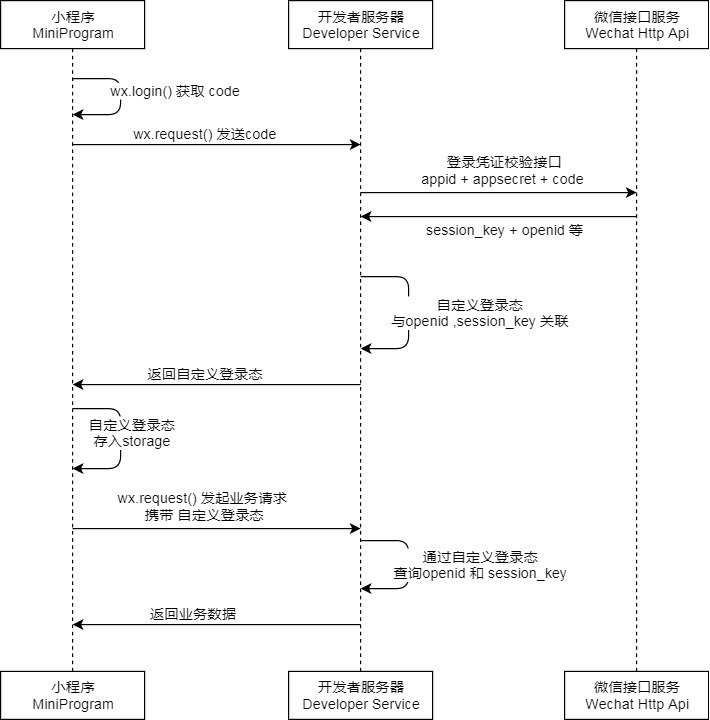
- 通过调用wx.login拿到code(有效期为5分钟),发送给后端。
- 后端拿到code后,通过code,appSecret和appId请求微信接口服务接口,获取到session_key和用户唯一标识openid。查看数据库是否已存在该openid,如果不存在的话,将openid和用户信息绑定在一起存到数据库。
`https://api.weixin.qq.com/sns/jscode2session?appid= ${option.appId}&secret=${option.appSecret} &js_code=${body.code}&grant_type=authorization_code` - 生成token,返回给前端。
- 前端每次请求带上token,后端进行验证。
具体实施
- wx.login
wx.login({ success: res => { res.code }, fail: err => { / ... } }) - 后台获取session_key和openid,查看数据库是否已存在该openid,如果不存在的话,将openid和用户信息绑定在一起存到数据库。
// https模块 const https = require('https') // 封装请求方法 const request = (url) => { return new Promise((resolve, reject) => { https.get(url, res => { let data = '' res.on('data', chunk => { data += chunk }) res.on('end', () => { resolve(JSON.parse(data)) }) }).on('error', err => { reject(err) }) }) }
const url = https://api.weixin.qq.com/sns/jscode2session?appid= ${option.appId}&secret=${option.appSecret} &js_code=${body.code}&grant_type=authorization_code
const login = async ctx => { try { const res = await request(url) let user = await users.find({ where: { open_id: res.openid } }) // 如果不存在该用户,向users表添加该用户 if (!user) { await users.create({ name: body.userName, picture: body.picture, open_id: res.openid }) // 获取该user user = await users.find({ where: { open_id: res.openid } }) } } catch (err) { // err } } export login
4. 使用密钥生成token
```js
import jsonwebtoken from 'jsonwebtoken'
// 封装方法
const signToken = payload => {
const token = jsonwebtoken.sign(
payload,
config.auth.jwtSecret, // 存放着openid
{
expiresIn: '24h'
}
)
return token
}- 对请求验证token
// 请求头带上token headers: { 'Authorization': 'Bearer ' + token }import jsonwebtoken from 'jsonwebtoken' // 封装方法 const checkToken = ctx => { const token = ctx.header.authorization.split(' ')[1] try { jsonwebtoken.verify(token, config.auth.jwtSecret, { expiresIn: '24h' }) } catch (err) { throw new Error('token验证错误:' + err) } }
// 注册中间件 app.use(jwt({ secret: config.auth.jwtSecret }).unless({ // 除开登录请求 path: [/\/login/] }))
[两种常用的认证方式](https://github.com/HolyZheng/holyZheng-blog/issues/9#issuecomment-402698538)
### 2. 优化
#### 图片懒加载
小程序image组件,自带lazy-load属性,但是为什么我还是选择自己实现懒加载呢,因为自带的懒加载并不是当图片出现在可视区域的时候再去加载,经过实践发现,它会提前两个屏幕的高度进行加载,也就是说你的图片数量多到超过可视范围的两个屏幕高度才能得到懒加载的好处,这个提前量太多了,所以有必要自己实现一个“真正的”懒加载。
```js
const ctx = this
let className = '.brief-image-' + ctx.properties.index
wx.createIntersectionObserver().relativeToViewport().observe(className, res => {
if (res.intersectionRatio > 0) {
ctx.setData({
load: true
})
}
})- 通过
createIntersectionObserver方法创建一个IntersectionObserver对象,小程序里面给它的定义是节点布局交叉状态API可用于监听组件节点在布局位置上的相交状态。 - 通过
relativeToViewport方法,接收一个选择符作为参数来规定相对的节点,默认为页面可视区域 - 再通过
observe方法,接收一个选择符作为参数来指定监视的节点。 - 在回调中判断
res.intersectionRatio是否大于 0 来判断始出出现在了可视区域。- 数据分组下载
通过
limit,offset参数来分组(分页)请求数据。// 后端 Experiments.findAll({ offset: parseInt(body.offset), limit: parseInt(body.limit), include: [{ model: Users }] })
- 数据分组下载
通过
寻寻被试