 jcrist
commented
3 years ago
jcrist
commented
3 years ago I think dask and kubernetes are unlikely to be the culprits here, rather I suspect your CreateSyncJob (or the RunNamespacedJob) task accumulates memory over time. Since these tasks are mostly IO bound, you might try running with a LocalDaskExecutor instead to eliminate dask.distributed from consideration.
# Swapping out executor for this should do it
executor = LocalDaskExecutor(num_workers=6) joelluijmes
joelluijmes

 novotl
novotl github-actions[bot]
github-actions[bot] charalamm
charalamm cicdw
cicdw
Description
I’m running Prefect in Kubernetes. What I have is a flow which spawns 15 Kubernetes high CPU intense jobs. In order to do some parallelism, I have in the flow a DaskExecutor configured (6 workers, 1 thread).
What I see is the prefect-job which is created by the Kubernetes agent, uses quite some resources which grows over time. See attached screenshot.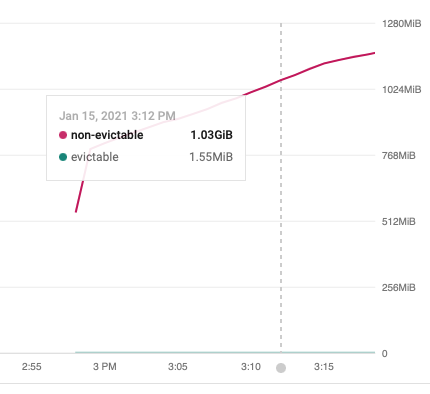
Note: I’m talking about the job created by the prefect agent. The actual job executing code is only using 188MiB.
It seems like there is a possible memory leak in either Prefect or Dask. Is there a better alternative to deploy this? Which uses less resources?
Expected Behavior
Well first of all, I wouldn't expect this high memory usage. But most of all, not that it seems to be growing indefinitely. In this instance, the flow wasn't killed (yet) by Kubernetes due high memory usage, but that is something I was running into.
Reproduction
Reproduction is bit tricky as this flow is generated from a config file on running the script. I think I got all the relevant bits below:
Visualizing one of the flows show: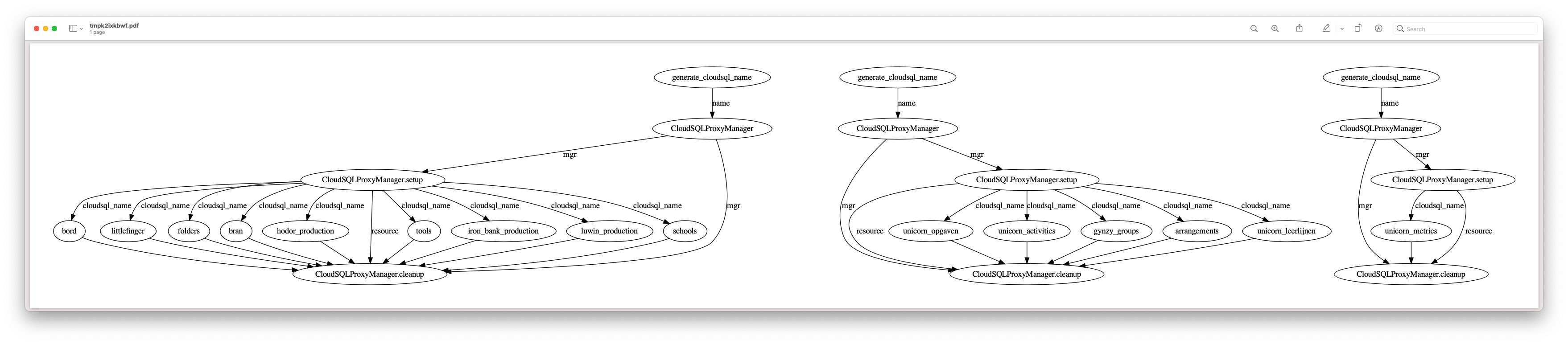
Environment
Running Prefect Server 0.14.0 on Kubernetes 1.18.x in Google Cloud.
Originally reported on slack: https://prefect-community.slack.com/archives/CL09KU1K7/p1610706804087800