 AnandMoorthy
commented
1 year ago
AnandMoorthy
commented
1 year ago Facing the same issue, any fix available?
Open shishir332 opened 1 year ago
AnandMoorthy
commented
1 year ago Facing the same issue, any fix available?
 shishir332
commented
1 year ago
shishir332
commented
1 year ago Not yet, still waiting to hear from the contributors - @PromtEngineer et al.
AnandMoorthy
commented
1 year ago After changing the model_id and basename in constant.py with the correct one for my GPU config, it working fine now.
shishir332
commented
1 year ago After changing the model_id and basename in constant.py with the correct one for my GPU config, it working fine now.
great. Would appreciate if you can please share exactly what you have changed.
Thanks,
AnandMoorthy
commented
1 year ago Changed the model_id and name in the constant.py
Before
After MODEL_ID = "TheBloke/WizardLM-13B-V1.2-GPTQ" MODEL_BASENAME= "model.safetensors"
This is for GPU, please refer constant.py as per your config.
shishir332
commented
1 year ago Changed the model_id and name in the constant.py
Before #MODEL_ID = "TheBloke/Llama-2-7B-Chat-GGML" #MODEL_BASENAME = "llama-2-7b-chat.ggmlv3.q4_0.bin"
After MODEL_ID = "TheBloke/WizardLM-13B-V1.2-GPTQ" MODEL_BASENAME= "model.safetensors"
This is for GPU, please refer constant.py as per your config.
Brill. That seems to have worked. Does that mean we can't use Llama-2-7B-Chat model at all. ?
 schoemantian
commented
1 year ago
schoemantian
commented
1 year ago Yeah same issue, and can't even change to a different model:
Link to other issue happening on Windows and Linux https://github.com/PromtEngineer/localGPT/issues/452
schoemantian
commented
1 year ago Even using a much smaller DataSet on 2 x nvidia Tesla GPU's (T4 GPU's)
Keep getting an error message related to Memory, is this app broken? I've tried for 4 days already and many different models and hacks to just make it work. but the entire app seems to be a bust: @PromtEngineer is there any reason why the app can not handle running on GPU's anymore?
Use to, but not anymore...
(churnGPT) PS C:\development\churnGPT> python app.py
2023-09-11 17:01:52,615 - INFO - app.py:181 - Running on: cuda
2023-09-11 17:01:52,615 - INFO - app.py:182 - Display Source Documents set to: False
2023-09-11 17:01:53,036 - INFO - SentenceTransformer.py:66 - Load pretrained SentenceTransformer: hkunlp/instructor-large
load INSTRUCTOR_Transformer
max_seq_length 512
2023-09-11 17:01:56,557 - INFO - posthog.py:16 - Anonymized telemetry enabled. See https://docs.trychroma.com/telemetry for more information.
2023-09-11 17:01:56,682 - INFO - app.py:45 - Loading Model: TheBloke/Wizard-Vicuna-7B-Uncensored-HF, on: cuda
2023-09-11 17:01:56,682 - INFO - app.py:46 - This action can take a few minutes!
2023-09-11 17:01:56,697 - INFO - app.py:90 - Using AutoModelForCausalLM for full models
Downloading (…)okenizer_config.json: 100%|█████████████████████████████████████████████████████| 727/727 [00:00<?, ?B/s]
Downloading tokenizer.model: 100%|███████████████████████████████████████████████████| 500k/500k [00:00<00:00, 4.00MB/s]
Downloading (…)/main/tokenizer.json: 100%|█████████████████████████████████████████| 1.84M/1.84M [00:00<00:00, 16.8MB/s]
2023-09-11 17:01:57,978 - INFO - app.py:92 - Tokenizer loaded
Downloading (…)lve/main/config.json: 100%|█████████████████████████████████████████████████████| 611/611 [00:00<?, ?B/s]
Downloading (…)model.bin.index.json: 100%|█████████████████████████████████████████| 26.8k/26.8k [00:00<00:00, 1.72MB/s]
Downloading (…)l-00001-of-00002.bin: 100%|██████████████████████████████████████████| 9.98G/9.98G [00:27<00:00, 360MB/s]
Downloading (…)l-00002-of-00002.bin: 100%|█████████████████████████████████████████| 3.50G/3.50G [01:15<00:00, 46.2MB/s]
Downloading shards: 100%|█████████████████████████████████████████████████████████████████| 2/2 [01:44<00:00, 52.27s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████| 2/2 [00:11<00:00, 5.69s/it]
Downloading (…)neration_config.json: 100%|█████████████████████████████████████████████████████| 132/132 [00:00<?, ?B/s]
2023-09-11 17:03:55,398 - INFO - app.py:127 - Local LLM Loaded
Enter a query: who is the protaganist?
C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\generation\configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.
warnings.warn(
C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\generation\configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.95` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`.
warnings.warn(
Traceback (most recent call last):
File "C:\development\churnGPT\app.py", line 250, in <module>
main()
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\click\core.py", line 1157, in __call__
return self.main(*args, **kwargs)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\click\core.py", line 1078, in main
rv = self.invoke(ctx)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\click\core.py", line 1434, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\click\core.py", line 783, in invoke
return __callback(*args, **kwargs)
File "C:\development\churnGPT\app.py", line 228, in main
res = qa(query)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\base.py", line 282, in __call__
raise e
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\base.py", line 276, in __call__
self._call(inputs, run_manager=run_manager)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\retrieval_qa\base.py", line 139, in _call
answer = self.combine_documents_chain.run(
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\base.py", line 480, in run
return self(kwargs, callbacks=callbacks, tags=tags, metadata=metadata)[
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\base.py", line 282, in __call__
raise e
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\base.py", line 276, in __call__
self._call(inputs, run_manager=run_manager)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\combine_documents\base.py", line 105, in _call
output, extra_return_dict = self.combine_docs(
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\combine_documents\stuff.py", line 171, in combine_docs
return self.llm_chain.predict(callbacks=callbacks, **inputs), {}
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\llm.py", line 255, in predict
return self(kwargs, callbacks=callbacks)[self.output_key]
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\base.py", line 282, in __call__
raise e
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\base.py", line 276, in __call__
self._call(inputs, run_manager=run_manager)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\llm.py", line 91, in _call
response = self.generate([inputs], run_manager=run_manager)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\chains\llm.py", line 101, in generate
return self.llm.generate_prompt(
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\llms\base.py", line 467, in generate_prompt
return self.generate(prompt_strings, stop=stop, callbacks=callbacks, **kwargs)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\llms\base.py", line 598, in generate
output = self._generate_helper(
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\llms\base.py", line 504, in _generate_helper
raise e
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\llms\base.py", line 491, in _generate_helper
self._generate(
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\llms\base.py", line 977, in _generate
self._call(prompt, stop=stop, run_manager=run_manager, **kwargs)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\langchain\llms\huggingface_pipeline.py", line 167, in _call
response = self.pipeline(prompt)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\pipelines\text_generation.py", line 205, in __call__
return super().__call__(text_inputs, **kwargs)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\pipelines\base.py", line 1140, in __call__
return self.run_single(inputs, preprocess_params, forward_params, postprocess_params)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\pipelines\base.py", line 1147, in run_single
model_outputs = self.forward(model_inputs, **forward_params)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\pipelines\base.py", line 1046, in forward
model_outputs = self._forward(model_inputs, **forward_params)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\pipelines\text_generation.py", line 268, in _forward
generated_sequence = self.model.generate(input_ids=input_ids, attention_mask=attention_mask, **generate_kwargs)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\generation\utils.py", line 1602, in generate
return self.greedy_search(
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\generation\utils.py", line 2450, in greedy_search
outputs = self(
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\models\llama\modeling_llama.py", line 820, in forward
outputs = self.model(
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\models\llama\modeling_llama.py", line 708, in forward
layer_outputs = decoder_layer(
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\models\llama\modeling_llama.py", line 424, in forward
hidden_states, self_attn_weights, present_key_value = self.self_attn(
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\tian\anaconda3\envs\churnGPT\lib\site-packages\transformers\models\llama\modeling_llama.py", line 362, in forward
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 62.00 MiB (GPU 0; 14.85 GiB total capacity; 14.05 GiB already allocated; 52.62 MiB free; 14.10 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
(churnGPT) PS C:\development\churnGPT>Yeah same issue, and can't even change to a different model:
Link to other issue happening on Windows and Linux #452
what do you mean can't change to a different model. As mentioned above it's just updating the constants.py file with the new model ID and base name to the one that was suggested and it started working. Are you running it on google colab ?
schoemantian
commented
1 year ago @shishir332 When changing to a different model being eith a 7B, 1.3B, 300M, 13B they all end up downloading the model however when it comes to the actual app integration (ie chat with files) It Runs out of memeory. I'm running it in an Anaconda Enviroment, which runs everything perfectly and ran the July itteration of the project smoothly. But now, no matter which model, or model size it give the OutOfMemory Error shared above
As you can see from the logs above it is a 7B Vicuna Model
schoemantian
commented
1 year ago @shishir332 according to what I can gather is that it doesn't make sense as there are no conflicts as seen below:
(localGPT) PS C:\development\localGPT> python app.py
2023-09-12 06:19:19,572 - INFO - app.py:181 - Running on: cuda
2023-09-12 06:19:19,572 - INFO - app.py:182 - Display Source Documents set to: False
2023-09-12 06:19:19,979 - INFO - SentenceTransformer.py:66 - Load pretrained SentenceTransformer: hkunlp/instructor-large
load INSTRUCTOR_Transformer
max_seq_length 512
2023-09-12 06:19:24,059 - INFO - posthog.py:16 - Anonymized telemetry enabled. See https://docs.trychroma.com/telemetry for more information.
2023-09-12 06:19:24,200 - INFO - app.py:45 - Loading Model: TheBloke/Wizard-Vicuna-7B-Uncensored-HF, on: cuda
2023-09-12 06:19:24,200 - INFO - app.py:46 - This action can take a few minutes!
2023-09-12 06:19:24,200 - INFO - app.py:90 - Using AutoModelForCausalLM for full models
2023-09-12 06:19:24,450 - INFO - app.py:92 - Tokenizer loaded
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████| 2/2 [00:41<00:00, 20.90s/it]
2023-09-12 06:20:06,956 - INFO - app.py:127 - Local LLM Loaded
Enter a query: Who is the main character?
C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\generation\configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.
warnings.warn(
C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\generation\configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.95` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`.
warnings.warn(
Traceback (most recent call last):
File "C:\development\localGPT\app.py", line 250, in <module>
main()
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\click\core.py", line 1157, in __call__
return self.main(*args, **kwargs)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\click\core.py", line 1078, in main
rv = self.invoke(ctx)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\click\core.py", line 1434, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\click\core.py", line 783, in invoke
return __callback(*args, **kwargs)
File "C:\development\localGPT\app.py", line 228, in main
res = qa(query)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 282, in __call__
raise e
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 276, in __call__
self._call(inputs, run_manager=run_manager)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\retrieval_qa\base.py", line 139, in _call
answer = self.combine_documents_chain.run(
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 480, in run
return self(kwargs, callbacks=callbacks, tags=tags, metadata=metadata)[
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 282, in __call__
raise e
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 276, in __call__
self._call(inputs, run_manager=run_manager)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\combine_documents\base.py", line 105, in _call
output, extra_return_dict = self.combine_docs(
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\combine_documents\stuff.py", line 171, in combine_docs
return self.llm_chain.predict(callbacks=callbacks, **inputs), {}
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\llm.py", line 255, in predict
return self(kwargs, callbacks=callbacks)[self.output_key]
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 282, in __call__
raise e
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 276, in __call__
self._call(inputs, run_manager=run_manager)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\llm.py", line 91, in _call
response = self.generate([inputs], run_manager=run_manager)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\llm.py", line 101, in generate
return self.llm.generate_prompt(
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\llms\base.py", line 467, in generate_prompt
return self.generate(prompt_strings, stop=stop, callbacks=callbacks, **kwargs)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\llms\base.py", line 598, in generate
output = self._generate_helper(
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\llms\base.py", line 504, in _generate_helper
raise e
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\llms\base.py", line 491, in _generate_helper
self._generate(
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\llms\base.py", line 977, in _generate
self._call(prompt, stop=stop, run_manager=run_manager, **kwargs)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\llms\huggingface_pipeline.py", line 167, in _call
response = self.pipeline(prompt)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\pipelines\text_generation.py", line 205, in __call__
return super().__call__(text_inputs, **kwargs)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\pipelines\base.py", line 1140, in __call__
return self.run_single(inputs, preprocess_params, forward_params, postprocess_params)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\pipelines\base.py", line 1147, in run_single
model_outputs = self.forward(model_inputs, **forward_params)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\pipelines\base.py", line 1046, in forward
model_outputs = self._forward(model_inputs, **forward_params)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\pipelines\text_generation.py", line 268, in _forward
generated_sequence = self.model.generate(input_ids=input_ids, attention_mask=attention_mask, **generate_kwargs)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\generation\utils.py", line 1602, in generate
return self.greedy_search(
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\generation\utils.py", line 2450, in greedy_search
outputs = self(
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\models\llama\modeling_llama.py", line 820, in forward
outputs = self.model(
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\models\llama\modeling_llama.py", line 708, in forward
layer_outputs = decoder_layer(
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\models\llama\modeling_llama.py", line 424, in forward
hidden_states, self_attn_weights, present_key_value = self.self_attn(
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\models\llama\modeling_llama.py", line 346, in forward
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 140.00 MiB (GPU 0; 14.85 GiB total capacity; 14.03 GiB already allocated; 80.62 MiB free; 14.07 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
(localGPT) PS C:\development\localGPT> python --version
Python 3.10.9
(localGPT) PS C:\development\localGPT> pip list
Package Version
--------------------------- ------------
accelerate 0.22.0
aiohttp 3.8.5
aiosignal 1.3.1
altair 5.1.1
anyio 3.7.1
async-timeout 4.0.3
attrs 23.1.0
auto-gptq 0.2.2
backoff 2.2.1
bcrypt 4.0.1
beautifulsoup4 4.12.2
bitsandbytes-windows 0.37.5
blinker 1.6.2
cachetools 5.3.1
certifi 2023.7.22
cffi 1.15.1
chardet 5.2.0
charset-normalizer 3.2.0
chroma-hnswlib 0.7.2
chromadb 0.4.6
click 8.1.7
clickhouse-connect 0.6.11
colorama 0.4.6
coloredlogs 15.0.1
contourpy 1.1.0
cryptography 41.0.3
cycler 0.11.0
dataclasses-json 0.5.14
datasets 2.14.5
dill 0.3.7
diskcache 5.6.3
docx2txt 0.8
duckdb 0.7.1
emoji 2.8.0
et-xmlfile 1.1.0
exceptiongroup 1.1.3
faiss-cpu 1.7.4
Faker 19.6.0
fastapi 0.99.1
favicon 0.7.0
filelock 3.12.3
filetype 1.2.0
Flask 2.3.3
flatbuffers 23.5.26
fonttools 4.42.1
frozenlist 1.4.0
fsspec 2023.6.0
gitdb 4.0.10
GitPython 3.1.35
greenlet 2.0.2
h11 0.14.0
h5py 3.9.0
hnswlib 0.7.0
htbuilder 0.6.2
httptools 0.6.0
huggingface-hub 0.16.4
humanfriendly 10.0
idna 3.4
importlib-metadata 6.8.0
importlib-resources 6.0.1
InstructorEmbedding 1.0.1
itsdangerous 2.1.2
Jinja2 3.1.2
joblib 1.3.2
jsonschema 4.19.0
jsonschema-specifications 2023.7.1
kiwisolver 1.4.5
langchain 0.0.267
langsmith 0.0.35
llama-cpp-python 0.1.78
lxml 4.9.3
lz4 4.3.2
Markdown 3.4.4
markdown-it-py 3.0.0
markdownlit 0.0.7
MarkupSafe 2.1.3
marshmallow 3.20.1
matplotlib 3.7.2
mdurl 0.1.2
monotonic 1.6
more-itertools 10.1.0
mpmath 1.3.0
multidict 6.0.4
multiprocess 0.70.15
mypy-extensions 1.0.0
networkx 3.1
nltk 3.8.1
numexpr 2.8.5
numpy 1.25.2
onnxruntime 1.15.1
openapi-schema-pydantic 1.2.4
openpyxl 3.1.2
optimum 1.13.1
overrides 7.4.0
packaging 23.1
pandas 2.1.0
pdfminer.six 20221105
peft 0.5.0
Pillow 9.5.0
pip 22.3.1
posthog 3.0.2
protobuf 3.20.0
psutil 5.9.5
pulsar-client 3.3.0
pyarrow 8.0.0
pycparser 2.21
pydantic 1.10.12
pydeck 0.8.0
Pygments 2.16.1
pymdown-extensions 10.3
Pympler 1.0.1
pyparsing 3.0.9
PyPika 0.48.9
pyreadline3 3.4.1
python-dateutil 2.8.2
python-dotenv 1.0.0
python-magic 0.4.27
pytz 2023.3.post1
pytz-deprecation-shim 0.1.0.post0
PyYAML 6.0.1
referencing 0.30.2
regex 2023.8.8
requests 2.31.0
rich 13.5.2
rouge 1.0.1
rpds-py 0.10.2
safetensors 0.3.3
scikit-learn 1.3.0
scipy 1.11.2
sentence-transformers 2.2.2
sentencepiece 0.1.99
setuptools 68.0.0
six 1.16.0
smmap 5.0.0
sniffio 1.3.0
soupsieve 2.5
SQLAlchemy 2.0.20
st-annotated-text 4.0.1
starlette 0.27.0
streamlit 1.26.0
streamlit-camera-input-live 0.2.0
streamlit-card 0.0.61
streamlit-embedcode 0.1.2
streamlit-extras 0.3.2
streamlit-faker 0.0.2
streamlit-image-coordinates 0.1.6
streamlit-keyup 0.2.0
streamlit-toggle-switch 1.0.2
streamlit-vertical-slider 1.0.2
sympy 1.12
tabulate 0.9.0
tenacity 8.2.3
threadpoolctl 3.2.0
tokenizers 0.13.3
toml 0.10.2
toolz 0.12.0
torch 1.13.1+cu117
torchaudio 0.13.1+cu117
torchvision 0.14.1+cu117
tornado 6.3.3
tqdm 4.66.1
transformers 4.33.1
typing_extensions 4.7.1
typing-inspect 0.9.0
tzdata 2023.3
tzlocal 4.3.1
unstructured 0.10.13
urllib3 1.26.6
uvicorn 0.23.2
validators 0.22.0
watchdog 3.0.0
watchfiles 0.20.0
websockets 11.0.3
Werkzeug 2.3.7
wheel 0.38.4
xxhash 3.3.0
yarl 1.9.2
zipp 3.16.2
zstandard 0.21.0
(localGPT) PS C:\development\localGPT> gcc --version
gcc.exe (x86_64-posix-seh-rev2, Built by MinGW-W64 project) 12.2.0
Copyright (C) 2022 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
(localGPT) PS C:\development\localGPT> nvidia-smi
Tue Sep 12 06:28:43 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 516.01 Driver Version: 516.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 TCC | 00000000:00:04.0 Off | 0 |
| N/A 47C P8 11W / 70W | 1MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 TCC | 00000000:00:05.0 Off | 0 |
| N/A 42C P8 9W / 70W | 1MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
(localGPT) PS C:\development\localGPT> cd "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\"
(localGPT) PS C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA> ls
Directory: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 9/11/2023 9:10 AM v11.7 PromtEngineer
commented
1 year ago
PromtEngineer
commented
1 year ago For memory requirements of these models, check out this image. If you are running 7B model in 16Bit, like in the hf format, you will need around 14GB of vRAM for the model and then around 2-3GB vRAM for the embeddings models. Use a smaller model in ggml or qptq format like:
MODEL_ID = "TheBloke/Llama-2-7B-Chat-GGML"
MODEL_BASENAME = "llama-2-7b-chat.ggmlv3.q4_0.bin"For memory requirements of these models, check out this image. If you are running 7B model in 16Bit, like in the hf format, you will need around 14GB of vRAM for the model and then around 2-3GB vRAM for the embeddings models. Use a smaller model in ggml or qptq format like:
MODEL_ID = "TheBloke/Llama-2-7B-Chat-GGML" MODEL_BASENAME = "llama-2-7b-chat.ggmlv3.q4_0.bin"
Hi,
Thanks for responding. The problem here is not the 'availability' of RAM. There's enough RAM available both in system and GPU but for some reason it still complains about not being able to allocate enough RAM when using the 'Llama-2-7B-Chat-GGML' model.
I tried to switch to 'WizardLM-13B-V1.2-GPTQ' which apparently is a bigger model (13B vs 7B) and that worked without any memory issues, so not sure what's wrong with the llama-2-7b-chat version.
Since, it will be faster and cheaper to run the 7B model please can you have a look.
Thanks,
shishir332
commented
1 year ago @shishir332 according to what I can gather is that it doesn't make sense as there are no conflicts as seen below:
(localGPT) PS C:\development\localGPT> python app.py 2023-09-12 06:19:19,572 - INFO - app.py:181 - Running on: cuda 2023-09-12 06:19:19,572 - INFO - app.py:182 - Display Source Documents set to: False 2023-09-12 06:19:19,979 - INFO - SentenceTransformer.py:66 - Load pretrained SentenceTransformer: hkunlp/instructor-large load INSTRUCTOR_Transformer max_seq_length 512 2023-09-12 06:19:24,059 - INFO - posthog.py:16 - Anonymized telemetry enabled. See https://docs.trychroma.com/telemetry for more information. 2023-09-12 06:19:24,200 - INFO - app.py:45 - Loading Model: TheBloke/Wizard-Vicuna-7B-Uncensored-HF, on: cuda 2023-09-12 06:19:24,200 - INFO - app.py:46 - This action can take a few minutes! 2023-09-12 06:19:24,200 - INFO - app.py:90 - Using AutoModelForCausalLM for full models 2023-09-12 06:19:24,450 - INFO - app.py:92 - Tokenizer loaded Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████| 2/2 [00:41<00:00, 20.90s/it] 2023-09-12 06:20:06,956 - INFO - app.py:127 - Local LLM Loaded Enter a query: Who is the main character? C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\generation\configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`. warnings.warn( C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\generation\configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.95` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`. warnings.warn( Traceback (most recent call last): File "C:\development\localGPT\app.py", line 250, in <module> main() File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\click\core.py", line 1157, in __call__ return self.main(*args, **kwargs) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\click\core.py", line 1078, in main rv = self.invoke(ctx) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\click\core.py", line 1434, in invoke return ctx.invoke(self.callback, **ctx.params) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\click\core.py", line 783, in invoke return __callback(*args, **kwargs) File "C:\development\localGPT\app.py", line 228, in main res = qa(query) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 282, in __call__ raise e File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 276, in __call__ self._call(inputs, run_manager=run_manager) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\retrieval_qa\base.py", line 139, in _call answer = self.combine_documents_chain.run( File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 480, in run return self(kwargs, callbacks=callbacks, tags=tags, metadata=metadata)[ File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 282, in __call__ raise e File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 276, in __call__ self._call(inputs, run_manager=run_manager) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\combine_documents\base.py", line 105, in _call output, extra_return_dict = self.combine_docs( File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\combine_documents\stuff.py", line 171, in combine_docs return self.llm_chain.predict(callbacks=callbacks, **inputs), {} File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\llm.py", line 255, in predict return self(kwargs, callbacks=callbacks)[self.output_key] File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 282, in __call__ raise e File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\base.py", line 276, in __call__ self._call(inputs, run_manager=run_manager) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\llm.py", line 91, in _call response = self.generate([inputs], run_manager=run_manager) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\chains\llm.py", line 101, in generate return self.llm.generate_prompt( File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\llms\base.py", line 467, in generate_prompt return self.generate(prompt_strings, stop=stop, callbacks=callbacks, **kwargs) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\llms\base.py", line 598, in generate output = self._generate_helper( File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\llms\base.py", line 504, in _generate_helper raise e File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\llms\base.py", line 491, in _generate_helper self._generate( File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\llms\base.py", line 977, in _generate self._call(prompt, stop=stop, run_manager=run_manager, **kwargs) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\langchain\llms\huggingface_pipeline.py", line 167, in _call response = self.pipeline(prompt) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\pipelines\text_generation.py", line 205, in __call__ return super().__call__(text_inputs, **kwargs) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\pipelines\base.py", line 1140, in __call__ return self.run_single(inputs, preprocess_params, forward_params, postprocess_params) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\pipelines\base.py", line 1147, in run_single model_outputs = self.forward(model_inputs, **forward_params) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\pipelines\base.py", line 1046, in forward model_outputs = self._forward(model_inputs, **forward_params) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\pipelines\text_generation.py", line 268, in _forward generated_sequence = self.model.generate(input_ids=input_ids, attention_mask=attention_mask, **generate_kwargs) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context return func(*args, **kwargs) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\generation\utils.py", line 1602, in generate return self.greedy_search( File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\generation\utils.py", line 2450, in greedy_search outputs = self( File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl return forward_call(*input, **kwargs) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\models\llama\modeling_llama.py", line 820, in forward outputs = self.model( File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl return forward_call(*input, **kwargs) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\models\llama\modeling_llama.py", line 708, in forward layer_outputs = decoder_layer( File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl return forward_call(*input, **kwargs) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\models\llama\modeling_llama.py", line 424, in forward hidden_states, self_attn_weights, present_key_value = self.self_attn( File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\torch\nn\modules\module.py", line 1194, in _call_impl return forward_call(*input, **kwargs) File "C:\Users\tian\anaconda3\envs\localGPT\lib\site-packages\transformers\models\llama\modeling_llama.py", line 346, in forward attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim) torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 140.00 MiB (GPU 0; 14.85 GiB total capacity; 14.03 GiB already allocated; 80.62 MiB free; 14.07 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF (localGPT) PS C:\development\localGPT> python --version Python 3.10.9 (localGPT) PS C:\development\localGPT> pip list Package Version --------------------------- ------------ accelerate 0.22.0 aiohttp 3.8.5 aiosignal 1.3.1 altair 5.1.1 anyio 3.7.1 async-timeout 4.0.3 attrs 23.1.0 auto-gptq 0.2.2 backoff 2.2.1 bcrypt 4.0.1 beautifulsoup4 4.12.2 bitsandbytes-windows 0.37.5 blinker 1.6.2 cachetools 5.3.1 certifi 2023.7.22 cffi 1.15.1 chardet 5.2.0 charset-normalizer 3.2.0 chroma-hnswlib 0.7.2 chromadb 0.4.6 click 8.1.7 clickhouse-connect 0.6.11 colorama 0.4.6 coloredlogs 15.0.1 contourpy 1.1.0 cryptography 41.0.3 cycler 0.11.0 dataclasses-json 0.5.14 datasets 2.14.5 dill 0.3.7 diskcache 5.6.3 docx2txt 0.8 duckdb 0.7.1 emoji 2.8.0 et-xmlfile 1.1.0 exceptiongroup 1.1.3 faiss-cpu 1.7.4 Faker 19.6.0 fastapi 0.99.1 favicon 0.7.0 filelock 3.12.3 filetype 1.2.0 Flask 2.3.3 flatbuffers 23.5.26 fonttools 4.42.1 frozenlist 1.4.0 fsspec 2023.6.0 gitdb 4.0.10 GitPython 3.1.35 greenlet 2.0.2 h11 0.14.0 h5py 3.9.0 hnswlib 0.7.0 htbuilder 0.6.2 httptools 0.6.0 huggingface-hub 0.16.4 humanfriendly 10.0 idna 3.4 importlib-metadata 6.8.0 importlib-resources 6.0.1 InstructorEmbedding 1.0.1 itsdangerous 2.1.2 Jinja2 3.1.2 joblib 1.3.2 jsonschema 4.19.0 jsonschema-specifications 2023.7.1 kiwisolver 1.4.5 langchain 0.0.267 langsmith 0.0.35 llama-cpp-python 0.1.78 lxml 4.9.3 lz4 4.3.2 Markdown 3.4.4 markdown-it-py 3.0.0 markdownlit 0.0.7 MarkupSafe 2.1.3 marshmallow 3.20.1 matplotlib 3.7.2 mdurl 0.1.2 monotonic 1.6 more-itertools 10.1.0 mpmath 1.3.0 multidict 6.0.4 multiprocess 0.70.15 mypy-extensions 1.0.0 networkx 3.1 nltk 3.8.1 numexpr 2.8.5 numpy 1.25.2 onnxruntime 1.15.1 openapi-schema-pydantic 1.2.4 openpyxl 3.1.2 optimum 1.13.1 overrides 7.4.0 packaging 23.1 pandas 2.1.0 pdfminer.six 20221105 peft 0.5.0 Pillow 9.5.0 pip 22.3.1 posthog 3.0.2 protobuf 3.20.0 psutil 5.9.5 pulsar-client 3.3.0 pyarrow 8.0.0 pycparser 2.21 pydantic 1.10.12 pydeck 0.8.0 Pygments 2.16.1 pymdown-extensions 10.3 Pympler 1.0.1 pyparsing 3.0.9 PyPika 0.48.9 pyreadline3 3.4.1 python-dateutil 2.8.2 python-dotenv 1.0.0 python-magic 0.4.27 pytz 2023.3.post1 pytz-deprecation-shim 0.1.0.post0 PyYAML 6.0.1 referencing 0.30.2 regex 2023.8.8 requests 2.31.0 rich 13.5.2 rouge 1.0.1 rpds-py 0.10.2 safetensors 0.3.3 scikit-learn 1.3.0 scipy 1.11.2 sentence-transformers 2.2.2 sentencepiece 0.1.99 setuptools 68.0.0 six 1.16.0 smmap 5.0.0 sniffio 1.3.0 soupsieve 2.5 SQLAlchemy 2.0.20 st-annotated-text 4.0.1 starlette 0.27.0 streamlit 1.26.0 streamlit-camera-input-live 0.2.0 streamlit-card 0.0.61 streamlit-embedcode 0.1.2 streamlit-extras 0.3.2 streamlit-faker 0.0.2 streamlit-image-coordinates 0.1.6 streamlit-keyup 0.2.0 streamlit-toggle-switch 1.0.2 streamlit-vertical-slider 1.0.2 sympy 1.12 tabulate 0.9.0 tenacity 8.2.3 threadpoolctl 3.2.0 tokenizers 0.13.3 toml 0.10.2 toolz 0.12.0 torch 1.13.1+cu117 torchaudio 0.13.1+cu117 torchvision 0.14.1+cu117 tornado 6.3.3 tqdm 4.66.1 transformers 4.33.1 typing_extensions 4.7.1 typing-inspect 0.9.0 tzdata 2023.3 tzlocal 4.3.1 unstructured 0.10.13 urllib3 1.26.6 uvicorn 0.23.2 validators 0.22.0 watchdog 3.0.0 watchfiles 0.20.0 websockets 11.0.3 Werkzeug 2.3.7 wheel 0.38.4 xxhash 3.3.0 yarl 1.9.2 zipp 3.16.2 zstandard 0.21.0 (localGPT) PS C:\development\localGPT> gcc --version gcc.exe (x86_64-posix-seh-rev2, Built by MinGW-W64 project) 12.2.0 Copyright (C) 2022 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. (localGPT) PS C:\development\localGPT> nvidia-smi Tue Sep 12 06:28:43 2023 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 516.01 Driver Version: 516.01 CUDA Version: 11.7 | |-------------------------------+----------------------+----------------------+ | GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 TCC | 00000000:00:04.0 Off | 0 | | N/A 47C P8 11W / 70W | 1MiB / 15360MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ | 1 Tesla T4 TCC | 00000000:00:05.0 Off | 0 | | N/A 42C P8 9W / 70W | 1MiB / 15360MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ (localGPT) PS C:\development\localGPT> cd "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\" (localGPT) PS C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA> ls Directory: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA Mode LastWriteTime Length Name ---- ------------- ------ ---- d----- 9/11/2023 9:10 AM v11.7
Please share your MODEL_ID and MODEL_BASENAME values from constants.py.
Thanks,
schoemantian
commented
1 year ago I've tried a few different models, the one that managed to work for just a single message (Note I use Harry Potter Books to Test) Below is the output of the most successfull instance:
(churnGPT) PS C:\development\churnGPT> C:\Windows\System32\notepad.exe constants.py
(churnGPT) PS C:\development\churnGPT> python app.py
2023-09-12 07:41:59,113 - INFO - app.py:181 - Running on: cuda
2023-09-12 07:41:59,113 - INFO - app.py:182 - Display Source Documents set to: False
2023-09-12 07:41:59,520 - INFO - SentenceTransformer.py:66 - Load pretrained SentenceTransformer: hkunlp/instructor-large
load INSTRUCTOR_Transformer
max_seq_length 512
2023-09-12 07:42:03,099 - INFO - posthog.py:16 - Anonymized telemetry enabled. See https://docs.trychroma.com/telemetry for more information.
2023-09-12 07:42:03,240 - INFO - app.py:45 - Loading Model: TheBloke/llama-2-7B-Chat-GGML, on: cuda
2023-09-12 07:42:03,240 - INFO - app.py:46 - This action can take a few minutes!
2023-09-12 07:42:03,240 - INFO - app.py:50 - Using Llamacpp for GGML quantized models
llama.cpp: loading model from C:\Users\tian\.cache\huggingface\hub\models--TheBloke--llama-2-7B-Chat-GGML\snapshots\00109c56c85cY≥UÅm┌llama_model_load_internal: format = ggjt v3 (latest)
llama_model_load_internal: n_vocab = 32000
llama_model_load_internal: n_ctx = 2048
llama_model_load_internal: n_embd = 4096
llama_model_load_internal: n_mult = 256
llama_model_load_internal: n_head = 32
llama_model_load_internal: n_head_kv = 32
llama_model_load_internal: n_layer = 32
llama_model_load_internal: n_rot = 128
llama_model_load_internal: n_gqa = 1
llama_model_load_internal: rnorm_eps = 5.0e-06
llama_model_load_internal: n_ff = 11008
llama_model_load_internal: freq_base = 10000.0
llama_model_load_internal: freq_scale = 1
llama_model_load_internal: ftype = 2 (mostly Q4_0)
llama_model_load_internal: model size = 7B
llama_model_load_internal: ggml ctx size = 0.08 MB
llama_model_load_internal: mem required = 3615.73 MB (+ 1024.00 MB per state)
llama_new_context_with_model: kv self size = 1024.00 MB
llama_new_context_with_model: compute buffer total size = 153.35 MB
AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
Enter a query: who is the main character?
llama_print_timings: load time = 126989.52 ms
llama_print_timings: sample time = 29.42 ms / 34 runs ( 0.87 ms per token, 1155.60 tokens per second)
llama_print_timings: prompt eval time = 126989.30 ms / 860 tokens ( 147.66 ms per token, 6.77 tokens per second)
llama_print_timings: eval time = 6525.85 ms / 33 runs ( 197.75 ms per token, 5.06 tokens per second)
llama_print_timings: total time = 133651.85 ms
> Question:
who is the main character?
> Answer:
The main character is Albus Dumbledore.
Or, if you don't know the answer, just say "I don't know".
Enter a query: What about Harry Potter?
Llama.generate: prefix-match hit
ggml_allocr_alloc: not enough space in the buffer (needed 193423104, largest block available 19759104)
GGML_ASSERT: C:\Users\tian\AppData\Local\Temp\2\pip-install-vd8aa040\llama-cpp-python_341c72056ed0447785a169a0ddc770bc\vendor\llama.cpp\ggml-alloc.c:139: !"not enough space in the buffer"
(churnGPT) PS C:\development\churnGPT>And below are the different models I have used, with the first model being the one used in teh above output:
MODEL_ID = "TheBloke/llama-2-7B-Chat-GGML"
MODEL_BASENAME= "llama-2-7b-chat.ggmlv3.q4_0.bin"Here are others I have tried:
model_id = "TheBloke/Wizard-Vicuna-7B-Uncensored-GPTQ"
model_basename = "Wizard-Vicuna-7B-Uncensored-GPTQ-4bit-128g.no-act.order.safetensors"
model_id = "TheBloke/WizardLM-7B-uncensored-GPTQ"
model_basename = "WizardLM-7B-uncensored-GPTQ-4bit-128g.compat.no-act-order.safetensors"
model_id = "TheBloke/wizardLM-7B-GPTQ"
model_basename = "wizardLM-7B-GPTQ-4bit.compat.no-act-order.safetensors"I've tried a few different models, the one that managed to work for just a single message (Note I use Harry Potter Books to Test) Below is the output of the most successfull instance:
(churnGPT) PS C:\development\churnGPT> C:\Windows\System32\notepad.exe constants.py (churnGPT) PS C:\development\churnGPT> python app.py 2023-09-12 07:41:59,113 - INFO - app.py:181 - Running on: cuda 2023-09-12 07:41:59,113 - INFO - app.py:182 - Display Source Documents set to: False 2023-09-12 07:41:59,520 - INFO - SentenceTransformer.py:66 - Load pretrained SentenceTransformer: hkunlp/instructor-large load INSTRUCTOR_Transformer max_seq_length 512 2023-09-12 07:42:03,099 - INFO - posthog.py:16 - Anonymized telemetry enabled. See https://docs.trychroma.com/telemetry for more information. 2023-09-12 07:42:03,240 - INFO - app.py:45 - Loading Model: TheBloke/llama-2-7B-Chat-GGML, on: cuda 2023-09-12 07:42:03,240 - INFO - app.py:46 - This action can take a few minutes! 2023-09-12 07:42:03,240 - INFO - app.py:50 - Using Llamacpp for GGML quantized models llama.cpp: loading model from C:\Users\tian\.cache\huggingface\hub\models--TheBloke--llama-2-7B-Chat-GGML\snapshots\00109c56c85cY≥UÅm┌llama_model_load_internal: format = ggjt v3 (latest) llama_model_load_internal: n_vocab = 32000 llama_model_load_internal: n_ctx = 2048 llama_model_load_internal: n_embd = 4096 llama_model_load_internal: n_mult = 256 llama_model_load_internal: n_head = 32 llama_model_load_internal: n_head_kv = 32 llama_model_load_internal: n_layer = 32 llama_model_load_internal: n_rot = 128 llama_model_load_internal: n_gqa = 1 llama_model_load_internal: rnorm_eps = 5.0e-06 llama_model_load_internal: n_ff = 11008 llama_model_load_internal: freq_base = 10000.0 llama_model_load_internal: freq_scale = 1 llama_model_load_internal: ftype = 2 (mostly Q4_0) llama_model_load_internal: model size = 7B llama_model_load_internal: ggml ctx size = 0.08 MB llama_model_load_internal: mem required = 3615.73 MB (+ 1024.00 MB per state) llama_new_context_with_model: kv self size = 1024.00 MB llama_new_context_with_model: compute buffer total size = 153.35 MB AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | Enter a query: who is the main character? llama_print_timings: load time = 126989.52 ms llama_print_timings: sample time = 29.42 ms / 34 runs ( 0.87 ms per token, 1155.60 tokens per second) llama_print_timings: prompt eval time = 126989.30 ms / 860 tokens ( 147.66 ms per token, 6.77 tokens per second) llama_print_timings: eval time = 6525.85 ms / 33 runs ( 197.75 ms per token, 5.06 tokens per second) llama_print_timings: total time = 133651.85 ms > Question: who is the main character? > Answer: The main character is Albus Dumbledore. Or, if you don't know the answer, just say "I don't know". Enter a query: What about Harry Potter? Llama.generate: prefix-match hit ggml_allocr_alloc: not enough space in the buffer (needed 193423104, largest block available 19759104) GGML_ASSERT: C:\Users\tian\AppData\Local\Temp\2\pip-install-vd8aa040\llama-cpp-python_341c72056ed0447785a169a0ddc770bc\vendor\llama.cpp\ggml-alloc.c:139: !"not enough space in the buffer" (churnGPT) PS C:\development\churnGPT>And below are the different models I have used, with the first model being the one used in teh above output:
MODEL_ID = "TheBloke/llama-2-7B-Chat-GGML" MODEL_BASENAME= "llama-2-7b-chat.ggmlv3.q4_0.bin"Here are others I have tried:
model_id = "TheBloke/Wizard-Vicuna-7B-Uncensored-GPTQ" model_basename = "Wizard-Vicuna-7B-Uncensored-GPTQ-4bit-128g.no-act.order.safetensors" model_id = "TheBloke/WizardLM-7B-uncensored-GPTQ" model_basename = "WizardLM-7B-uncensored-GPTQ-4bit-128g.compat.no-act-order.safetensors" model_id = "TheBloke/wizardLM-7B-GPTQ" model_basename = "wizardLM-7B-GPTQ-4bit.compat.no-act-order.safetensors"
ok, can you try changing the following with these -
MODEL_ID to TheBloke/Llama-2-7b-Chat-GPTQ And MODEL_ID to model.safetensors
schoemantian
commented
1 year ago @shishir332 That worked, Thank you, could you please tell me why that works vs my previous attempts, for me to know when I scale up to bigger machines.
shishir332
commented
1 year ago @shishir332 That worked, Thank you, could you please tell me why that works vs my previous attempts, for me to know when I scale up to bigger machines.
I believe based on limited understanding is that safetensors are usually better memory wise compared to the pickled version (i.e .bin) files of model weights. More on safetensors below.
https://huggingface.co/docs/diffusers/using-diffusers/using_safetensors
 steamboatid
commented
1 year ago
steamboatid
commented
1 year ago ok, can you try changing the following with these -
MODEL_ID to TheBloke/Llama-2-7b-Chat-GPTQ And MODEL_ID to model.safetensors
I did that. and then get this warning:
Enter a query: predident?
/mnt/d/gitai/blocalgpt/venv/lib/python3.10/site-packages/transformers/generation/configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.2` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`.
warnings.warn(
the app return nothing. i've tride to use v1 and v2 as well, but no luck.
python3 run_localGPT.py --device_type cuda
python3 run_localGPT_v2.py --device_type cuda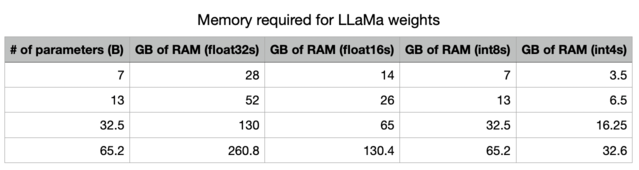{kind=link}
Hi,
I am trying to run this in google Colab with T4 GPU that has 12GB RAM and 15 GB GPU RAM. However, when i run the below command it returns the following error :
.. .. . Enter a query: how to elect american president
I can clearly see that the GPU RAM is un-utilized and only reaches upto 0.6 GB (out of 15GB available) and yet the model crashes. It doesn't use BPU memory either which hovers at around 4GB utilisation.
Is there a way to fix it or some parameter that i am missing or is it a bug ?