 smu160
commented
9 months ago
smu160
commented
9 months ago Hi @totikom,
Thank you for your insight! This would be a great initial start to a "circuit optimizer" that can be run prior to executing the actual circuit. If you're interested in implementing your suggestion, you are more than welcome to submit a PR.
For the sake of completeness and posterity, I will include some other findings/insights:
In my recent tests, I found that the single-threaded performance difference is negligible whether applying H to the 0th qubit, or to the 29th qubit; however, once you throw more threads at the problem, the story changes. Applying H to the 0th qubit is 2x faster than applying H to the 29th qubit. In fact, applying H to the 29th qubit with more than a single thread degrades performance. Hence, your suggestion may be a way to fix this issue in the case where we only apply a gate to a subset of the qubits.
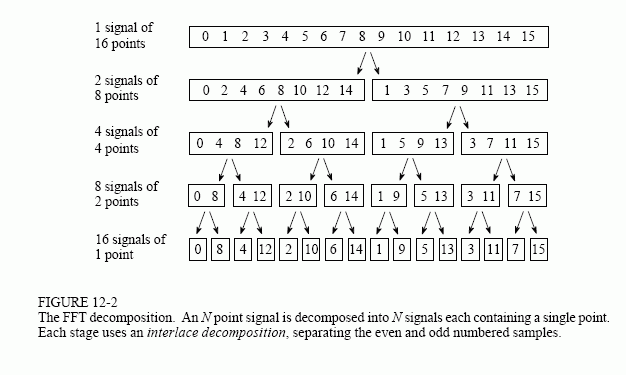
Note that applying a gate to the kth qubit has the same exact memory access pattern as the kth stage in the decimation-in-time FFT. I've been looking into leveraging strategies from high performance FFT implementations in order to improve data locality. In principle, we can bring all pairs right next to each-other by looking at how the FFT interleaves data-points at each stage.
This may be a way to tackle the implementation of your suggestion.
Best, Saveliy
 totikom
totikom{kind=link}
{kind=link}
(This may be completely unnecessary/inapplicable, so feel free to just close it)
The performance of simulating gates on big states drastically depends on its position (i.e. it is much faster to apply
Hto 0th qubit of the 30-qubit state that to the 29th)So, for "unbalanced" circuits it is very beneficial to move "the most used" qubits to lower indices.