 dsmiller
commented
6 years ago
dsmiller
commented
6 years ago Nice work... do you have numbers for approximately how long it take to synthesize audio with your fast wavenet?
Closed Rayhane-mamah closed 6 years ago
dsmiller
commented
6 years ago Nice work... do you have numbers for approximately how long it take to synthesize audio with your fast wavenet?
 Rayhane-mamah
commented
6 years ago
Rayhane-mamah
commented
6 years ago Not so quick overview of the latest commit (ec0cd50d24d7f5561f696a78d0cd47d5a2a14a43):
As you probably noticed, it has been a while since I pushed anything to the repository, so changes made in this latest commit will probably make your pretrained models useless.. sorry for that :(
So, let's have a not so quick overview of the major changes:
Wavenet Vocoder: (@MXGray I didn't say which Friday, so technically I'm still 6 days early! :) sigh Sorry for the delay..) -- The implementation of the wavenet vocoder is mainly inspired by @r9y9's Pytorch implementation, much thanks for your awesome work! I also relied on the Official Fast Wavenet implementation which corresponds to the Fast Wavenet paper to try optimizing training and synthesis times. (@dsmiller, Synthesis of 1 sec of audio takes about 56 seconds (around 330 audio_frames/sec). Please keep in mind that these stats were provided using a fairly powerful GPU (but only 50% of its potential is used in synthesis due to the recurrent nature of the model)). -- Both training and synthesis of Wavenet are up and running -- Global conditioning is not yet implemented (data reading part), and there still is an issue with training Wavenet on GTA mels so I recommend setting hparams.train_with_GTA to False for now. -- I also did not test Wavenet 100% yet so you might find few bugs here and there. If you also encounter some malfunctioning of the network, please let me know!
End-to-End Tacotron-2: Full Tacotron-2 pipeline is now available for train and synthesis. It is set as default behavior.
Now, to less important news:
Masking Encoder and Decoder paddings: -- Default training behavior changed to mask encoder and decoder paddings. This slows down attention convergence a little bit but improves the overall model results since it only trains it on real data without taking paddings into consideration. -- Decoder masks are done by applying masks on the loss function instead of imputing finished outputs during decoding. This allows for a faster execution and I personally find it cleaner
Weighted Cross Entropy: Due to masks on the decoder paddings, the model finds difficulty learning when to predict a
Curriculum-Learning:
-- Inspired by Bengio et al.(2015), I have added the possibility to use Curriculum-Learning for the Spectrogram Prediction Network training to help the model capture the reader's speaking style better while reducing the robotic effect in the reading style of the model. It is mainly a way to translate the training process of the model from teacher-forcing to the sampling scheme while ensure a fast and smooth learning process. (refer to the paper for more info)
-- CL uses a slow transition of the teacher forcing ratio from 1. to 0., which slowly introduces noise to the model inputs and shifts the output distribution from perfect (training) distribution to noisy (test) distribution that the model encounters during synthesis. In this work, Teacher forcing ratio decay over time follows a cosine decay:
 -- To activate the CL, change hparams.tacotron_teacher_forcing_mode to scheduled. This is still in test phase so I recommend sticking with vanilla teacher forcing for now.
-- To activate the CL, change hparams.tacotron_teacher_forcing_mode to scheduled. This is still in test phase so I recommend sticking with vanilla teacher forcing for now.
Add Evaluation modes and stats: To monitor possible overfitting (reported by @PetrochukM), I added Natural Eval for Tacotron model and Incremental eval for Wavenet. The natural eval purpose is to also show the effects of CL on the final outcome of the model and give an approximate overview of the model performance at synthesis times.
Live synthesis using Tacotron+G-L: as requested by @seatonullberg, I have added a live mode to the tacotron synthesis, which is not a fancy web interface, just a terminal interactive small app to toy a little with the Spectrogram Prediction Network (I usually try to make it bark or laugh..sigh). Audio is inverted using G-L or LWS (check hparams.py) to ensure a real time synthesis. @seatonullberg, I am sure you can improve on this modest app..
Correct Zoneout: As corrected by @Ondal90, The project now uses a corrected version of Zoneout. Natural synthesis is no longer faster than ground truth. @Ondal90, you sir are a hero, thank you very much!
Correct hparams override: Whoever brought this to my attention, I am really sorry I can't find where you requested that.. Anyway, overriding hparams now works properly, no need to make changes on hparams.py directly, parameters can now be modified within the python arguments call.
Add seeds and random states: To allow for results repeatability, I added models seeds for both Tacotron and Wavenet, also random seeds for train_test_split.
I believe these are the most important changes, if you notice any malfunctions, please let me know, I will provide full trained models probably within a week or two. Enjoy!
 cobr123
commented
6 years ago
cobr123
commented
6 years ago trained with python train.py
then tried evaluate python synthesize.py --model='Both' --mode='eval'
Running End-to-End TTS Evaluation. Model: Both Synthesizing mel-spectrograms from text.. Traceback (most recent call last): File "/home/cobr123/Videos/home/cobr123/Tacotron-2-WaveNet-female/tacotron/synthesize.py", line 111, in tacotron_synthesize checkpoint_path = tf.train.get_checkpoint_state(checkpoint).model_checkpoint_path AttributeError: 'NoneType' object has no attribute 'model_checkpoint_path'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "synthesize.py", line 90, in
cobr123
commented
6 years ago if run
python synthesize.py --mode='eval'
then
Running End-to-End TTS Evaluation. Model: Tacotron-2
Synthesizing mel-spectrograms from text..
loaded model at logs-Tacotron-2/pretrained/model.ckpt-11000
Traceback (most recent call last):
File "synthesize.py", line 90, in
Rayhane-mamah
commented
6 years ago @cobr123 Thank for reporting those,
I believe they are fixed now, and training with model as "Tacotron-2" and testing with "Both" (and vice versa) should be doable now. Also fixed few bugs here and there with T2 train and test pipeline.
Thank again for the feedback, feel free to post any other problems you encounter!
 nikita-smetanin
commented
6 years ago
nikita-smetanin
commented
6 years ago @Rayhane-mamah there's some criticism about curriculum-learning http://www.inference.vc/scheduled-sampling-for-rnns-scoring-rule-interpretation/ (tl;dr of the blogpost — it forces a model to produce marginal, not conditional distribution), does it offer any quality improvement for this model?
Rayhane-mamah
commented
6 years ago @nsmetanin, that's an interesting way to look at it!
Actually the idea to use CL in this project was an intuition of mine, I only discovered bengio's paper later on when trying to find similar previous works. As the blog mentioned, paper authors did not propose CL as a new training approach and there are few GAN alternatives (It would be a pain to implement them and get them working properly..)
From a theoretical point of view, I think the blog is making a point although I am not entirely convinced the resulting distribution is marginal, considering that when teacher forcing ratio is high, model is drawn close to the eventual conditional (teacher-forcing) distribution and thus preventing it from generating completely random outputs. When conducting experiments, I found out that for our application, CL is effective at teaching the model to better capture the speaking style from data (When to stop mid-sentence, increase and decrease of pitch..) at the cost of extra blur in the mels output. I believe this latter behavior is due to the fast decrease of teacher forcing ratio, although now that I read this article, few extra reasons came to mind..
LJ021-0176.wav.tar.gz is a nice example of what a teacher forced model finds hard to reproduce with high fidelity. Usually, a teacher-forcing trained model will read this sentence with a fixed tone, it sometimes doesn't stop on the "?" either.
So, usual teacher-forcing training works 100% with Tacotron-2, CL is only an extra feature I am testing at the moment to see if it can make generate voice sound a little more natural without affecting the overall quality of the model. if it doesn't work, I think I'll consider few GAN approaches.
Thank a lot for sharing, I will tell you how things go.
 sneakycastro
commented
6 years ago
sneakycastro
commented
6 years ago Hi @Rayhane-mamah, i can't get a good alignment on your current repo, i used my own dataset.
 I trained on 0b3a267 and the result is good though.
I trained on 0b3a267 and the result is good though.
 al3chen
commented
6 years ago
al3chen
commented
6 years ago @ Rayhane-mamah, I can not get acceptance alignment on tacotron training after 30k steps if outputs_per_step = 2. But before May 15, the result is good after 30k steps. I checked script and found default max tacotron training steps be updated as 300k. Do you mean we need more training steps for same good result now ?
Rayhane-mamah
commented
6 years ago @sneakycastro and @al3chen thanks for reaching out!
Yes you're both right, I forgot to mention that when masking input paddings during attention computation, alignments tend to become harder to learn (with r=1, it only shows around 50k steps depending on the dataset). If you seek a fast learning model, please set mask_encoder to False:
https://github.com/Rayhane-mamah/Tacotron-2/blob/d375c67fbfda2989294ecb4ec9892762055d8277/hparams.py#L79
Usually, if training using r>1 and without masking input paddings, you get a fine working model at 20k steps (but information spreading can be highly imbalanced between the network's parameters which leads to overfitting). I personally like to let it train for few more steps beyond 50k and keep controlling how it performs on eval sentences by generating audio multiple times to check if there is too much variance that can be captured by ears. A second way of controlling overfit is to use the eval dataset with same teacher forcing plan as training. (equivalent commit coming in a couple of hours).
@sneakycastro, while we're at it, usually if attention starts with a similar form to what you're reporting, it takes even more steps to converge than usual. I still have no idea why it sometimes starts that way..
 reidsanders
commented
6 years ago
reidsanders
commented
6 years ago In case it would be helpful: with new hparams I'm at 53k steps, and no sign of alignment. In fact it seems to be even more 'stuck in the corner' like sneakycastro's than before. I was considering giving up on this train as loss was also rising, but will let it go a while longer and post if it starts learning alignment.

EDIT: btw by 76.5k steps loss was still increasing with no sign of alignment.
Other experiments: with r=5, batch_size=34, and encoder_mask=False I got alignment at 6k. With r=5, batch_size=34, and encoder_mask=True I got alignment at 13.5k. This was all on m-ailabs elizabeth_klett with sequences longer than 800 removed and a 5% test set withheld. I'll try the new changes.
 begeekmyfriend
commented
6 years ago
begeekmyfriend
commented
6 years ago I disabled both mask_encoder and mask_decoder and it began getting to convergence in 4K steps.

al3chen
commented
6 years ago mask_encoder = False

Rayhane-mamah
commented
6 years ago About (fb5564b7584ae0dc62ffecaa89d463ff24a3c251):
Decoder size / 2: I recently have been trying to reduce network's size to speed up train/synthesis and most of all to reduce network complexity and overfit with it. I recently was able to confirm that new default decoder parameters give same results as old ones (just need a little more training): https://github.com/Rayhane-mamah/Tacotron-2/blob/fb5564b7584ae0dc62ffecaa89d463ff24a3c251/hparams.py#L77-L79
Hann Window modification: Also changed window size to allow for less noisy mels and for some reason new setup helps the model learning faster: https://github.com/Rayhane-mamah/Tacotron-2/blob/fb5564b7584ae0dc62ffecaa89d463ff24a3c251/hparams.py#L32-L35
minimal frequency: Also discovered that for some datasets (e.g: M-AILABS, en_US, judy_bieber) high values of minimal frequencies can loose low frequencies information in mels, thus making things harder for the model. So we reduced fmin=25 to match with some of M-AILABS speakers. This parameter is highly dependent on the dataset so try toying with it!
https://github.com/Rayhane-mamah/Tacotron-2/blob/fb5564b7584ae0dc62ffecaa89d463ff24a3c251/hparams.py#L52
Faster attention: Due to one of the upper causes, and after the suggestion of @begeekmyfriend, I started using bias in the location features computation (convolution):
https://github.com/Rayhane-mamah/Tacotron-2/blob/fb5564b7584ae0dc62ffecaa89d463ff24a3c251/tacotron/models/attention.py#L161-L163
This led to a faster attention despite the encoder and decoder masks
 butterl
commented
6 years ago
butterl
commented
6 years ago @Rayhane-mamah so the hope size and win_size need to be changed when sample rate is changed?
Tacotron-2/hparams.py
Lines 32 to 35 in fb5564b
n_fft = 2048, #Extra window size is filled with 0 paddings to match this parameter
hop_size = 275, #For 22050Hz, 275 ~= 12.5 ms
win_size = 1100, #For 22050Hz, 1100 ~= 50 ms (If None, win_size = n_fft)
sample_rate = 22050, #22050 Hz (corresponding to ljspeech dataset) If you want to keep the 50 ms window size and 12.5 ms shift yes.
Hop_size_ms = hop_size / sr Win_size_ms = win_size / sr If win_size = None, then win_size = n_fft (number of points for the fourier transform, when n_fft > win_size, the latter is padded with zeros to match the length of the former).
So for 24kHz for example: Win_size = 1200 ==> 50 ms Hop_size = 300 ==> 12.5 ms etc..
On Sat, 26 May 2018, 02:51 butterl, notifications@github.com wrote:
@Rayhane-mamah https://github.com/Rayhane-mamah so the hope size and win_size need to be changed when sample rate is changed?
Tacotron-2/hparams.py
Lines 32 to 35 in fb5564b n_fft = 2048, #Extra window size is filled with 0 paddings to match this parameter hop_size = 275, #For 22050Hz, 275 ~= 12.5 ms win_size = 1100, #For 22050Hz, 1100 ~= 50 ms (If None, win_size = n_fft) sample_rate = 22050, #22050 Hz (corresponding to ljspeech dataset)
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub https://github.com/Rayhane-mamah/Tacotron-2/issues/4#issuecomment-392227026, or mute the thread https://github.com/notifications/unsubscribe-auth/AhFSwCPbb_GrEdeXo9EBAiPI6HSttrbvks5t2LUTgaJpZM4SSQwC .
butterl
commented
6 years ago @Rayhane-mamah Thanks for your reply! Any limitation to select the hop_size (frame_shift_ms) with different sample_rate ? Win_size seems must be multiple of hop_size, hparam init relationship like this?
n_fft = 2048, #Extra window size is filled with 0 paddings to match this parameter
sample_rate = 22050,
frame_shift_ms = 12.5, # <<< Any relationship with sample_rate ?
hop_size = frame_shift_ms * sample_rate / 1000, #For 22050Hz, 275 ~= 12.5 ms
win_size = 4 * hop_size, #For 22050Hz, 1100 ~= 50 ms (If None, win_size = n_fft) atreyas313
commented
6 years ago
atreyas313
commented
6 years ago Hi all, @Rayhane-Mamah Your implementation is very excellent. I want to work on tacotron2 and replace sampleRNN (as vocoder) with wavenet, but don't know how samplerRNN conditioning on Mel spectrogram prediction. Is it possible for you to guide me implement this code?
Rayhane-mamah
commented
6 years ago @butterl yes excellent point! the ms values of frame shift or window size are independent of the sample rate, they are mainly related to what we are trying to predict/learn. For speech, 50 ms window size and 12.5 shift is usually the way to go. their respective values in frames is dependent on the sample rate.
Also as you mentioned, win_size = 4 * hop_size is correct. It is not necessary to use n_fft = 2048, one can set win_size to None and use n_fft instead (win_size will take by default same value as n_fft).
@atreyas313 Hi, Because I never thought of this option and don't have much knowledge on sampleRNN, and because I most certainly don't want to give you false information, I will take few days to explore you request. Thank you for your patience. Also, because this request isn't really related to the repo and so that we don't spam with an out of context discussion, please hit me an e-mail to my address, I will gladly help you as much as I can :)
begeekmyfriend
commented
6 years ago @butterl 50ms can be regarded as a steady wave frame and 12.5ms as a steady shift hop regardless of the sample rate according to engineering experience. Therefore given 16KHz sample rate, the window length is 800 and the hop size is 200. However we can also set window length as 64ms and hop length as 16ms and then the sample size is corresponding 1024 and 256.
 osungv
commented
6 years ago
osungv
commented
6 years ago Hi ! @Rayhane-mamah Thank you for your implementation of Tacotron2 and WaveNet vocoder. I trained the prediction network with my own dataset and the dataset resemble the LJ speech dataset.(metadata.csv, wavs folder) The Tacotron's training is successful but there is some problem in the wavenet's training. I made the gta/map.txt file using synthesize.py with GTA=True condition. But an error is occurred like following line.
I do googling and many people say, 'it is a bug because of cpu and gpu'. Is the wavenet's training based on the gpu?
Rayhane-mamah
commented
6 years ago Hello @osungv thanks for reaching out!
This is indeed related to CPU. i am assuming your CPU doesn't use MKL either which makes some ops only doable when channels last. For performance we tend to use channels first on GPU. Since you get this error while it never occurred to me, I am going to request that you verify your GPU is being used for Wavenet training. By default Wavenet training is set on GPU, so could you confirm that your GPU is working properly for other tensorflow projects? Could you provide information about your GPU and CPU (Along with RAM) stats when training the model?
butterl
commented
6 years ago @Rayhane-mamah @begeekmyfriend Thanks for reaching out ! I tried window length as 64ms and hop length as 16ms(thchs30), and param as below
hop_size = 256,
win_size = 1024,
sample_rate = 16000,
outputs_per_step = 2,
enc_conv_num_layers = 5, It get good aligned 22K+

But it exploded at 22.5K+


begeekmyfriend
commented
6 years ago @butterl I do not recommend THCHS30 since I have trained on it with the previous version. It got to convergence within 5K steps but I heard a lot of silence in the synthesized audio. Now I have successfully trained on 10h single speaker dataset and go on WaveNet training. By the way, the hyper parameters you set is OK for me.
butterl
commented
6 years ago @begeekmyfriend thanks for reaching out! I do not got any private dataset now and will try with the single speaker in thchs30, any hparam suggestion for short time single speaker dataset?
begeekmyfriend
commented
6 years ago @butterl The hyper parameter is the same. But I cannot assure you the effects on the results.
 unwritten
commented
6 years ago
unwritten
commented
6 years ago @Rayhane-mamah I notice there're many pronunciation error cases in my generation, do you get insight on how to avoid this in training or the model?
begeekmyfriend
commented
6 years ago @unwritten maybe you need g2p?
 StevenZYj
commented
6 years ago
StevenZYj
commented
6 years ago Hi @Rayhane-mamah ,
I have a small question here. I notice that you've removed gta if-condition when reaching finished condition in TrainingHelper, I wonder if that if-condition has the same effect (when gta is False) as impute_finished=True?
atreyas313
commented
6 years ago Hi @Rayhane-mama, what is the reason of preemphasis remove in tacotron 2?
 ishansan38
commented
6 years ago
ishansan38
commented
6 years ago Hey @Rayhane-mamah Amazing work with the repo! I was wondering if you could provide the pretrained model so I could quickly evaluate results on my end.
Thanks!
atreyas313
commented
6 years ago hi, after train and synthesize the Tacotron model, for train the Wavenet model has occurred OOM error. information about my GPU: GTX 1080, with 8G memory. Is possible for you to say the wavenet's training based on the GPU(Along with RAM)?
 ghost
commented
6 years ago
ghost
commented
6 years ago hi, @Rayhane-mamah I do not know why the WAV should be rescaled during the preprocessing procedure, in this way:
if hparams.rescale:
wav = wav / np.abs(wav).max() * hparams.rescaling_maxCould you tell me why, or is there any keyword I could search via Google? Thank you so much.
 DanRuta
commented
6 years ago
DanRuta
commented
6 years ago Hi @Rayhane-mamah. Having the an issue similar to @osungv , above.
I ran python train.py --model='Both', after pre-processing the LJ dataset, and the Tacotron model trained fine, the gta/map.txt was generated, but the InvalidArgumentError: Conv2DCustomBackpropFilterOp only supports NHWC error arises when it reaches the Wavenet training stage, and on subsequent Wavenet only runs.
I've made no changes to the (latest) code, and I've ensured that the GPU is used.
I did change outputs_per_step to 5, in hparams.py as my 8GB of GPU memory wasn't enough, and I saw this suggestion somewhere.
GPU: GTX 1080 CPU: 7700k RAM: 32GB tensorflow-gpu version: 1.8.0 Running on Windows
Any ideas?
 jgarciadominguez
commented
6 years ago
jgarciadominguez
commented
6 years ago We have trained 200.000 steps with a small corpus. Not good result, but the weird thing is that everytime we syntetize the result is slightly different.
python3 synthesize.py --model='Tacotron' --mode='eval' --hparams='symmetric_mels=False,max_abs_value=4.0,power=1.1,outputs_per_step=1' --text_to_speak='this is a test'
and hparams
Hyperparameters: allow_clipping_in_normalization: True attention_dim: 128 attention_filters: 32 attention_kernel: (31,) cleaners: english_cleaners cumulative_weights: True decoder_layers: 2 decoder_lstm_units: 1024 embedding_dim: 512 enc_conv_channels: 512 enc_conv_kernel_size: (5,) enc_conv_num_layers: 3 encoder_lstm_units: 256 fft_size: 1024 fmax: 7600 fmin: 125 frame_shift_ms: None griffin_lim_iters: 60 hop_size: 256 impute_finished: False input_type: raw log_scale_min: -32.23619130191664 mask_encoder: False mask_finished: False max_abs_value: 4.0 max_iters: 2500 min_level_db: -100 num_freq: 513 num_mels: 80 outputs_per_step: 1 postnet_channels: 512 postnet_kernel_size: (5,) postnet_num_layers: 5 power: 1.1 predict_linear: False prenet_layers: [256, 256] quantize_channels: 65536 ref_level_db: 20 rescale: True rescaling_max: 0.999 sample_rate: 22050 signal_normalization: True silence_threshold: 2 smoothing: False stop_at_any: True symmetric_mels: False tacotron_adam_beta1: 0.9 tacotron_adam_beta2: 0.999 tacotron_adam_epsilon: 1e-06 tacotron_batch_size: 2 tacotron_decay_learning_rate: True tacotron_decay_rate: 0.4 tacotron_decay_steps: 50000 tacotron_dropout_rate: 0.5 tacotron_final_learning_rate: 1e-05 tacotron_initial_learning_rate: 0.001 tacotron_reg_weight: 1e-06 tacotron_scale_regularization: True tacotron_start_decay: 50000 tacotron_teacher_forcing_ratio: 1.0 tacotron_zoneout_rate: 0.1 trim_silence: True use_lws: True Constructing model: Tacotron
Any ideas why this could be happening?
TEST 1:
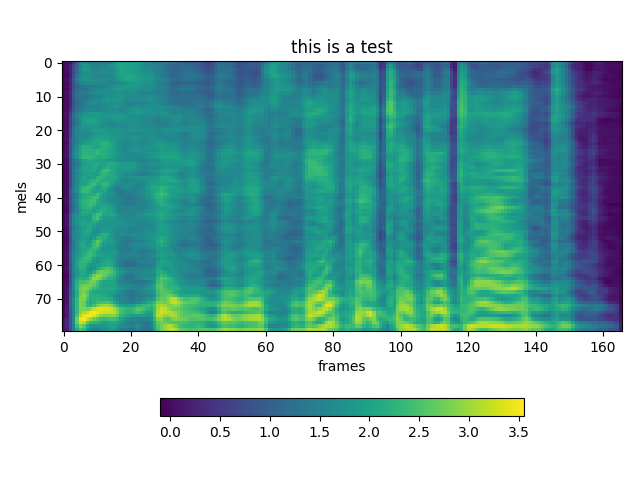
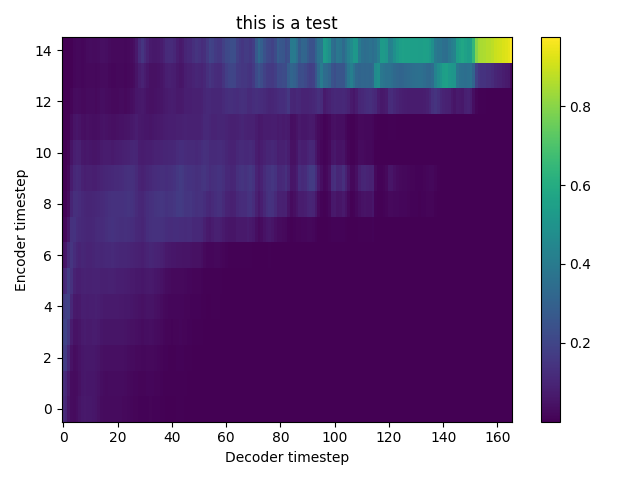 TEST 2:
TEST 2:
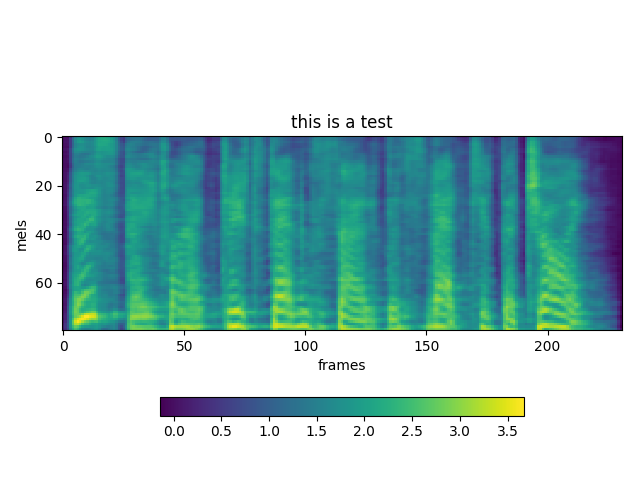
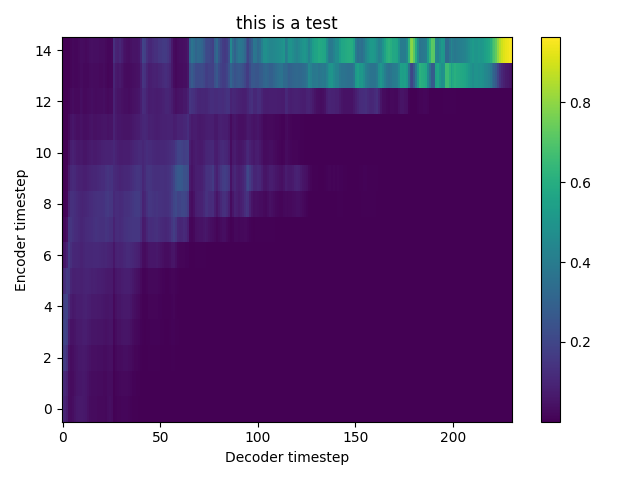
atreyas313
commented
6 years ago Hi, I trained network using "python train.py --model='Both' " then tried to synthesis from checkpoints using "python synthesize.py --model='Tacotron-2' " and happen this error: DataLossError (see above for traceback): file is too short to be an sstable [[Node: model_1/save/RestoreV2 = RestoreV2[dtypes=[DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, ..., DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT], _device="/job:localhost/replica:0/task:0/device:CPU:0"](_arg_model_1/save/Const_0_0, model_1/save/RestoreV2/tensor_names, model_1/save/RestoreV2/shape_and_slices)]] [[Node: model_1/save/RestoreV2/_493 = _Recv[client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device_incarnation=1, tensor_name="edge_498_model_1/save/RestoreV2", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:GPU:0"]()]]
Can anyone guide me how can I fix this error?
 hadaev8
commented
6 years ago
hadaev8
commented
6 years ago @Rayhane-mamah What do you think about? https://www.tensorflow.org/api_docs/python/tf/keras/layers/CuDNNLSTM
 ben-8878
commented
6 years ago
ben-8878
commented
6 years ago @atreyas313 I met same error, do you have solve it? I train model with ‘Tacotron-2’ and test with 'Both' as the author said, but still met the error.
Rayhane-mamah
commented
6 years ago @jgarciadominguez results are different everytime because we keep decoder prenet dropout active even during synthesis. As for the quality, your batch size if very small during training which causes the model to not learn how to align, thus the bad quality. Don't use smaller batch size than 32, it's okey to use outputs_per_step=3 for that purpose.
@atreyas313 and @v-yunbin this "Both" option is causing everyone problems it seems, I took it off so please make sure to train with "Tacotron-2" instead (it will train Tacotron+Wavenet)
@hadaev8 I thought about using that for faster computation but didn't really spend much time trying to apply zoneout on it, if you get any success with it let me know :)
This is a sample of the wavenet from last commit on M-AILABS mary_ann: wavenet-northandsouth_01_f000005.wav.tar.gz
Because all objectives of this repo are now done, I will close this issue and make a tour on all issues open to answer most of them this evening. The pretrained models and samples will be updated soon in the README.md. If any problems persist, feel free to open issues.
 puneet-kr
commented
6 years ago
puneet-kr
commented
6 years ago Hi there, first of all, I'm thankful for this code.
I'm a beginner and trying to run it. With the parallelization implemented in datasets/preprocessor.py, I'm getting this error: BrokenProcessPool: A process in the process pool was terminated abruptly while the future was running or pending.
Can somebody please convert this code to serial implementation:
executor = ProcessPoolExecutor(max_workers=n_jobs) futures = [] index = 1 for input_dir in input_dirs: with open(os.path.join(input_dir, 'metadata.csv'), encoding='utf-8') as f: for line in f: parts = line.strip().split('|') basename = parts[0] wav_path = os.path.join(input_dir, 'wavs', '{}.wav'.format(basename)) text = parts[2] futures.append(executor.submit(partial(_process_utterance, mel_dir, linear_dir, wav_dir, basename, wav_path, text, hparams))) index += 1 return [future.result() for future in tqdm(futures) if future.result() is not None]
I understood that i. __process_utterance (out_dir, index, wav_path, text) needs to be called for every input. But I couldn't yet understand how to modify this statement:
return [future.result() for future in tqdm(futures) if future.result() is not None]
 anushaprakash90
commented
6 years ago
anushaprakash90
commented
6 years ago Hi Rayhane,
I am running this code for the first time. I am training the tacotron-2 model using the LJSpeech dataset. The model is training without any issues, but on the cpu and not the gpus (checked with nvidia-smi). Is there anything that needs to be specified explicitly so that training can be done on the gpus?
Rayhane-mamah
commented
6 years ago Hello, @anushaprakash90
Our implementation automatically uses your GPUs if tensorflow detects them. So your issue is most likely related to your tensorflow installation. I would recommend removing all your installed tensorflow libraries, then only reinstall the gpu version of it (tensorflow-gpu). That should fix it. Please refer to other closed similar issues for more info, and feel free to start a new one if your problem persists or if you believe your issue is different.
Thanks
On Mon, 1 Oct 2018, 07:20 anushaprakash90, notifications@github.com wrote:
Hi Rayhane,
I am running this code for the first time. I am training the tacotron-2 model using the LJSpeech dataset. The model is training without any issues, but on the cpu and not the gpus (checked with nvidia-smi). Is there anything that needs to be specified explicitly so that training can be done on the gpus?
— You are receiving this because you modified the open/close state. Reply to this email directly, view it on GitHub https://github.com/Rayhane-mamah/Tacotron-2/issues/4#issuecomment-425800686, or mute the thread https://github.com/notifications/unsubscribe-auth/AhFSwBaDfT6OvJz0m2kdATeX8z2Q0Pegks5ugbQhgaJpZM4SSQwC .
 ishandutta2007
commented
6 years ago
ishandutta2007
commented
6 years ago @Rayhane-mamah Is the pretrained model ready ?
 lucasjinreal
commented
6 years ago
lucasjinreal
commented
6 years ago @Rayhane-mamah Does there any sample radios inference with trained model? Does that sounds well or not?
 hxs7709
commented
6 years ago
hxs7709
commented
6 years ago @Rayhane-mamah Thank you very much for the great repository, I like it. I see the clarinet paper and some code change are committed to our repository on 10.7. Does it mean it support clarinet now? Or do you have plan to support clarinet?
hxs7709
commented
6 years ago @Rayhane-mamah In README.md, we should add --mode='synthesis' to following command, otherwise we still run into eval mode because mode's default value is 'eval'. Please help to check double-check it. python synthesize.py --model='Tacotron' --GTA=True # synthesized mel spectrograms at tacotron_output/gta python synthesize.py --model='Tacotron' --GTA=False # synthesized mel spectrograms at tacotron_output/natural
In addition, the wavenet_preprocess.py directly get mel spectrograms at tacotron_output/gta for training data. What is the difference of two mel spectrograms from following two commands? They can both be used to separately training wavenet. python synthesize.py --model='Tacotron' --GTA=True python wavenet_preprocess.py
Thank you.
anushaprakash90
commented
6 years ago @Rayhane-mamah Thanks. After installing only tensorflow-gpu, I am able to run the code on the GPUs. I am now using the the updated scripts of Tacotron. When I run the code, it is running on all the available GPUs, but gives a segmentation fault just before training. This is perhaps a memory issue. I am trying to run the code on a single GPU. As mentioned in the hparams.py file, I have set num_gpus=0 and tacotron_gpu_start_idx appropriately. However, I am getting the following error:
ValueError: Attr 'num_split' of 'Split' Op passed 0 less than minimum 1.
Traceback: File "/speech/anusha/Tacotron-2/tacotron/models/tacotron.py", line 61, in initialize tower_input_lengths = tf.split(input_lengths, num_or_size_splits=hp.tacotron_num_gpus, axis=0)
This requires tacotron_num_gpus to be set to at least 1 so that it can recognize that a GPU is available. Should I modify any other parameter, etc.?
Thanks
ishandutta2007
commented
5 years ago 6k4 steps
@Rayhane-mamah: Do you mean 60000 steps or 6000 steps ?
 mrgloom
commented
5 years ago
mrgloom
commented
5 years ago What is the last model compatible with master?
 Arafat4341
commented
4 years ago
Arafat4341
commented
4 years ago Hi @Rayhane-mamah! Can we train using jsut data? I found no support for pre-processing jsut(japanese text corpus) data. That's why I tried to use deepvoice3's preprocess module to prepare data and then copied that folder inside cloned repo of tacotron2 and named it 'training_data'. Then I ran train.py module and I am getting this error:
`Traceback (most recent call last):
File "train.py", line 138, in
Can you help!!
this umbrella issue tracks my current progress and discuss priority of planned TODOs. It has been closed since all objectives are hit.
Goal
Model
Feature Prediction Model (Done)
Wavenet vocoder conditioned on Mel-Spectrogram (Done)
Scripts
Extra (optional):
Notes:
All models in this repository will be implemented in Tensorflow on a first stage, so in case you want to use a Wavenet vocoder implemented in Pytorch you can refer to this repository that shows very promising results.