 Rob174
commented
3 years ago
Rob174
commented
3 years ago Objectifs par ordre de priorité (1 = + prioritaire)
- "Stabiliser" autant que possible les courbes d'erreur tr et valid :
On veut ce type de courbe :
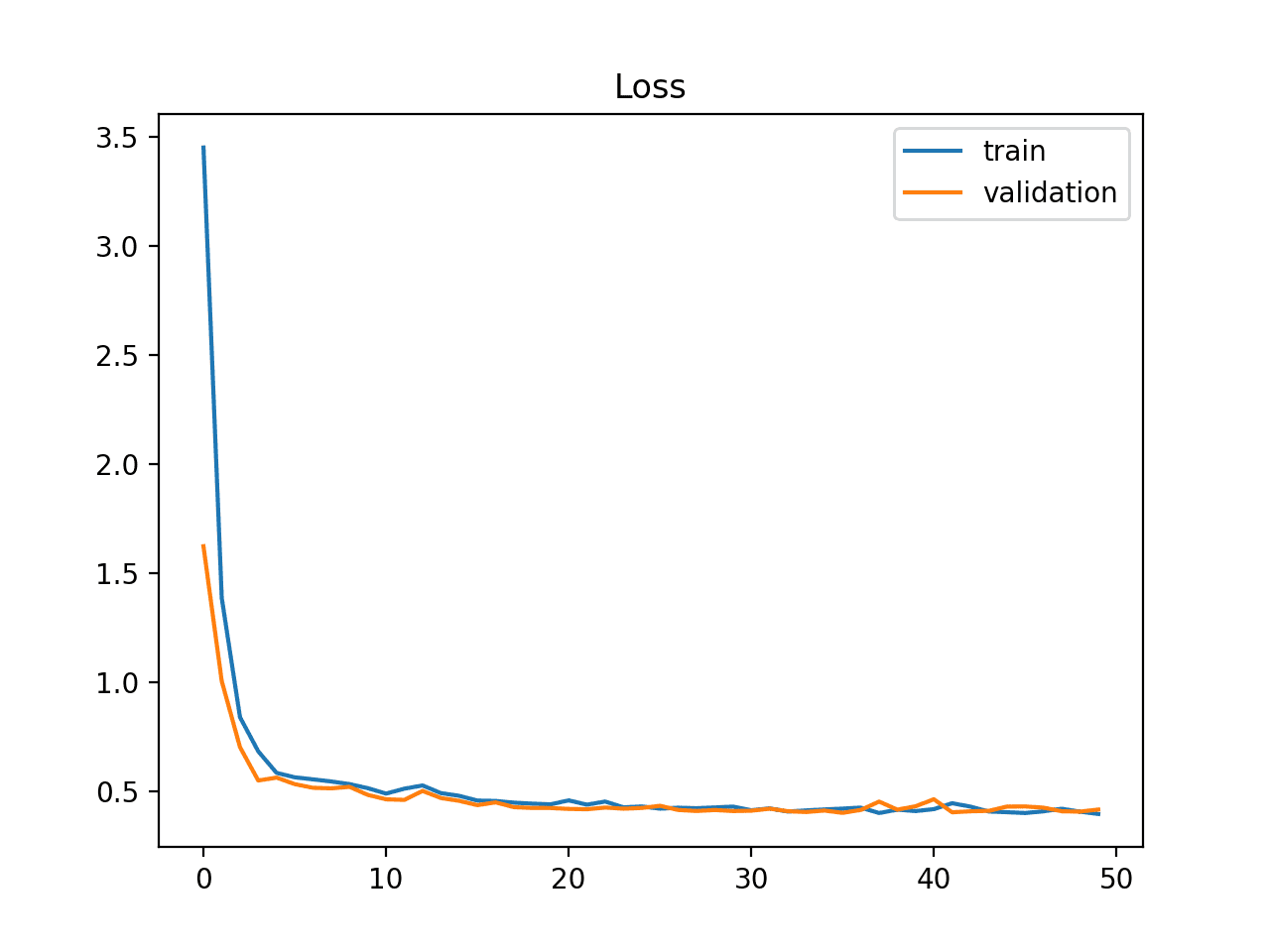
(source )
- Améliorer la précision finale de l'IA
Comme on le voit sur l'image du dessus l'erreur décroit mais fini par se stabiliser au bout d'un certain temps. Si on continue d'entrainer le modèle, l'erreur de validation réaugmentera car le modèle surrajustera. On veut donc
- Faire décroitre erreur_valid vers une valeur minimale la + basse possible
- Déterminer à quel moment cette valeur minimale est atteinte et donc à partir de quand le modèle surrajuste
- Dans la mesure du possible faire en sorte que l'erreur tr et l'erreur valid restent assez proches : si les 2 courbes d'erreur sont proches le modèle a bien généralisé les connaissances acquises par les images d'entrainement
Tests à réaliser :
Interprétation générale : pas d'apprentissage, peut-être pas de généralisation
Tests pour tenter d'améliorer l'aptitude à généraliser
(chiffre petit = + prioritaire ; chiffre grand = - prioritaire)
| Test | Priorité | But | Effet observé | Testé |
|---|---|---|---|---|
| Diminuer le nb de filtre | 4 | - de paramètres = + simple à optimiser (et + difficile de surrajuster et "mémoriser" le dataset) | toujours pas d'amélioration | ✔️ |
| Augmenter le nb de filtres | 4 | si le paramètre n'a pas assez de paramètres pour apprendre à distinguer les classes | ||
| Passer en Conv simple | 5 | Revenir à des couches + simples (intérêt très limité car ces couches ont l'avantage de réduire le nombre de paramètres) | ||
| Augmenter le epsilon de Adam pour ralentir l'apprentissage et permettre une potentielle meilleure généralisation | 1 | Ralentir l'apprentissage pour améliorer la généralisation | Aucun changement fortement notable | ✔️ |
| Diminuer la learning rate | 1 | idem | Aucun effet (par contre trop l'augmenter diminue la précision) | ✔️ |
| Augmenter la batch_size | 2 | donner des échantillons + gros pour qu'ils soient + représentatif du dataset global | Aucun changement quelle que soit la taille de batch | ♻️ |
| Changer la loss pour une à base de categoricalcrossentropy | 3 | Actuellement MSE (+ efficaces pour l'entrainement que MSE pour guider le modèle) | :x: tâche de régression pas de prédiction | |
| Mettre le biais à false sur les couches de convolution | 1 | sur les docs indiqué comme cela | résultat non concluant | ✔️ |
| Passer de l'optimizer Adam à SGB | 1 | momentum 0.9 ; lr_init = 0.045 ; ( pour le decay car on ne sait même pas 2 epochs donc on ne le change pas) | résultat non concluant | ✔️ |





















































 AliciaC8
AliciaC8













{kind=link}
Problème d'apprentissage
Problème
Version a2fa05f
Aucun apprentissage Loss MSE
Etapes suivies / sommaire
Raisonnement générale
Sommaire - étapes 1 à 3 : Hypothèse : modèle ok juste à régler les paramètres d'entrainement (- de possibilités à tester)
Sommaire - étape 4 : les valeurs prédites sont contraintes de se sommer à 1 par la fonction d'activation softmax retournant un vecteur de probabilités. Remplacement par une sigmoid
Sommaire - étape 5 : actualisation des tests de paramètres d'entrainement
Sommaire - étape 6 : les valeurs prédites n'indiquent pas combien d'objet de chaque classe apparaissent sur chaque image
Sommaire - étape 6.a. : changement de sortie du réseau : nouvelle sortie, effectif de chaque classe pour chaque image. Tests pour trouver une nouvelle fonction d'activation finale adaptée qui ne limite pas chaque effectif à 1 comme une fonction sigmoid.
Sommaire - étape 7-8 : Supposition : nécessité d'ajuster l'architecture
Sommaire - étape 9 : Supposition : le modèle underfit : trop contraint, pas assez de couches pour prédire correctement.
⚠️ Note importante : le dernier code à jour de cette issue est sur la branche
model_keras_graphLayers