LITONG99
commented
1 week ago
LITONG99
commented
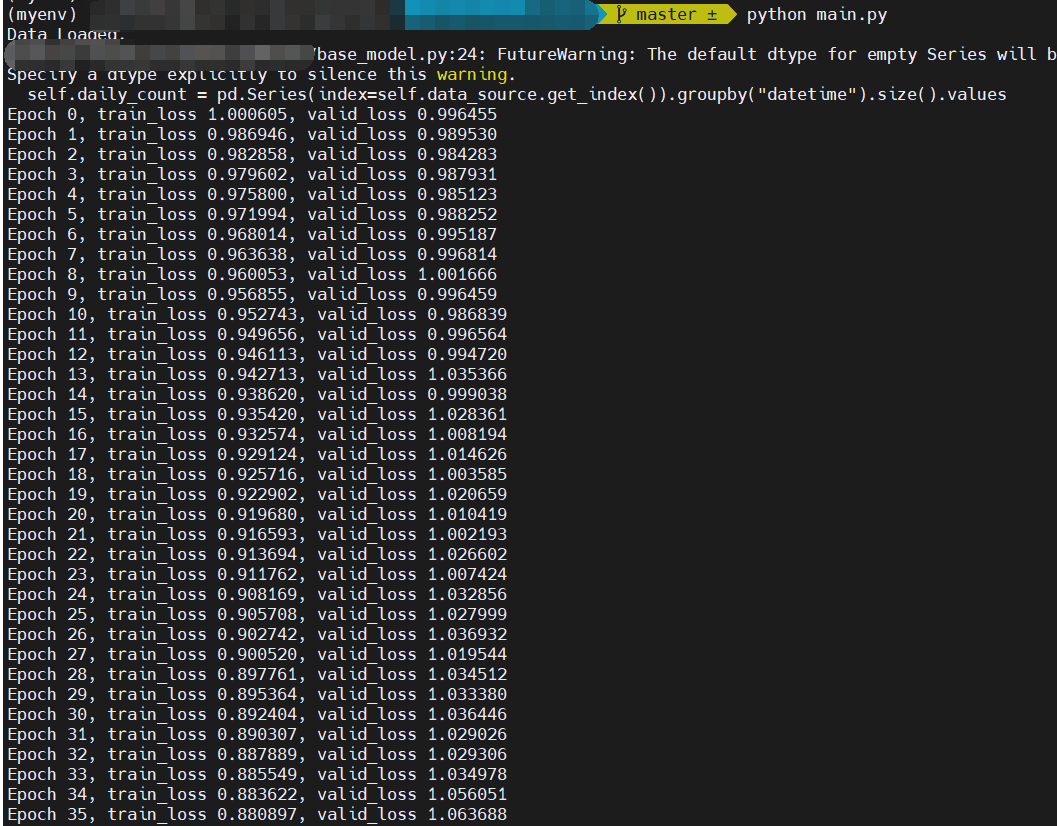
1 week ago Because the model is overfit. In other words, you may have trained for too many epochs.
In the figure, we can notice that, despite the fluctuation, the validation loss decreases first (0-10 epoch) and then increases.
We set train_stop_loss_thred=0.95 in the main.py: line 32 for early stopping, which is roughly when the validation loss stops decreasing in our repeated experiments. I think you may have altered this setting to explore. Indeed, due to its unique data properties, the model training and selection can be difficult in the stock price forecasting task.
 eator
eator
As the figure shows, the valid loss is increasing.