 ymlab
commented
1 year ago
ymlab
commented
1 year ago dist方式跑eval我还没测过的,目前不太清楚会有什么坑,或许等忙过这一阵我一并检查下dist方式的训练和测试流程。
Henry @.***> 于2023年4月8日周六 14:15写道:
我下载了作者train的模型本地使用pytorch进行test和eval, 具体命令参照作者workdir文件下对应的log文件,但是我用torch推理后测评的结果比作者log中的结果低很多,不同之处: 作者是用slurm我是用pytorch,我两张A100推理,难道与这有关?还是其他什么因素 [image: image] https://user-images.githubusercontent.com/52202915/230706508-112ee1ee-4d5b-48ec-aa26-a9d590ca2826.png
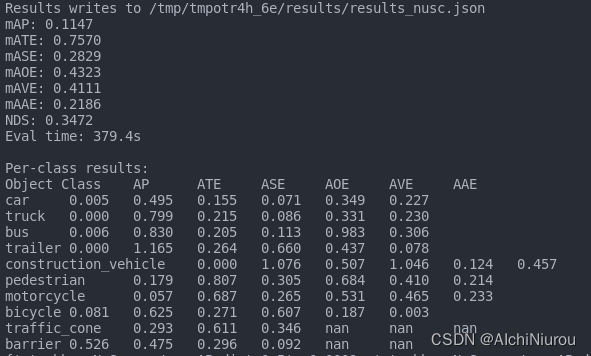
我对作者m2模型测评结果 [image: image] https://user-images.githubusercontent.com/52202915/230706547-bca061e2-b4d8-4668-b73a-812cd2cea3bb.png
具体测试命令如下,请指教
test
python3 -m torch.distributed.launch --nnodes=1 --node_rank=0 --nproc_per_node 2 --master_addr 127.0.0.1 tools/test.py \ configs/fastbev/exp/paper/fastbev_m2_r34_s256x704_v200x200x4_c224_d4_f4.py work_dirs/fastbev/exp/paper/fastbev_m2_r34_s256x704_v200x200x4_c224_d4_f4/epoch_20.pth \ --launcher=pytorch --out work_dirs/fastbev/exp/paper/fastbev_m2_r34_s256x704_v200x200x4_c224_d4_f4/results/results.pkl \ --format-only \ --eval-options jsonfile_prefix=work_dirs/fastbev/exp/paper/fastbev_m2_r34_s256x704_v200x200x4_c224_d4_f4/results
eval
python3 -m torch.distributed.launch --nnodes=1 --node_rank=0 --nproc_per_node 2 --master_addr 127.0.0.1 tools/eval.py \ configs/fastbev/exp/paper/fastbev_m2_r34_s256x704_v200x200x4_c224_d4_f4.py \ --launcher=pytorch --out work_dirs/fastbev/exp/paper/fastbev_m2_r34_s256x704_v200x200x4_c224_d4_f4/results/results.pkl \ --eval bbox
— Reply to this email directly, view it on GitHub https://github.com/Sense-GVT/Fast-BEV/issues/47, or unsubscribe https://github.com/notifications/unsubscribe-auth/A2SSIGY2GMCTK6F7R235L6DXAD673ANCNFSM6AAAAAAWXIPKZI . You are receiving this because you are subscribed to this thread.Message ID: @.***>
 HenryZhangJianhe
HenryZhangJianhe
 zhangkangkai
zhangkangkai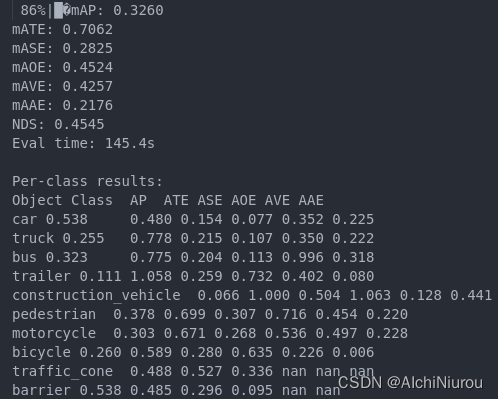{kind=link}
{kind=link}
我下载了作者train的模型本地使用pytorch进行test和eval, 具体命令参照作者workdir文件下对应的log文件,但是我用torch推理后测评的结果比作者log中的结果低很多,不同之处: 作者是用slurm我是用pytorch,我两张A100推理,难道与这有关?还是其他什么因素
我对作者m2模型测评结果
具体测试命令如下,请指教