 ujibang
commented
2 years ago
ujibang
commented
2 years ago RESTHeart does not cache query results. It does have a mechanism to speed up requests for your use case, called Cursor Pool, see https://restheart.org/docs/mongodb-rest/speedup-requests-with-cursor-pools
Getting the n-th page implies using cursor.skip((n-1)*pagesize). The fact that subsequent pages take longer and longer depends on the MongoDB cursor.skip() operation that slows downs linearly. See https://www.mongodb.com/docs/manual/reference/method/cursor.skip/
The skip() method requires the server to scan from the beginning of the input results set before beginning to return results. As the offset increases, skip() will become slower.
In the same doc page, MongoDB suggests to use Range Queries, that is exactly what you already want to do and the correct way of querying a collection with 5 millions documents.
Consider using range-based pagination for these kinds of tasks. That is, query for a range of objects, using logic within the application to determine the pagination rather than the database itself. This approach features better index utilization, if you do not need to easily jump to a specific page.
The Cursor Pool features tries to speed up queries by pre-allocating cursors where the skip operation is executed for the subsequent pages. However it won't help if the requests are executed quickly one after the other or in parallel, because it does require some time to actually allocating the cursors. For instance, it work very well in the common case of an application showing paginated data to a user, who changes page with some delay.
You might also want to define an aggregation; in this case you can optimize your query and also pass the time boundaries via variables
 camlin
camlin


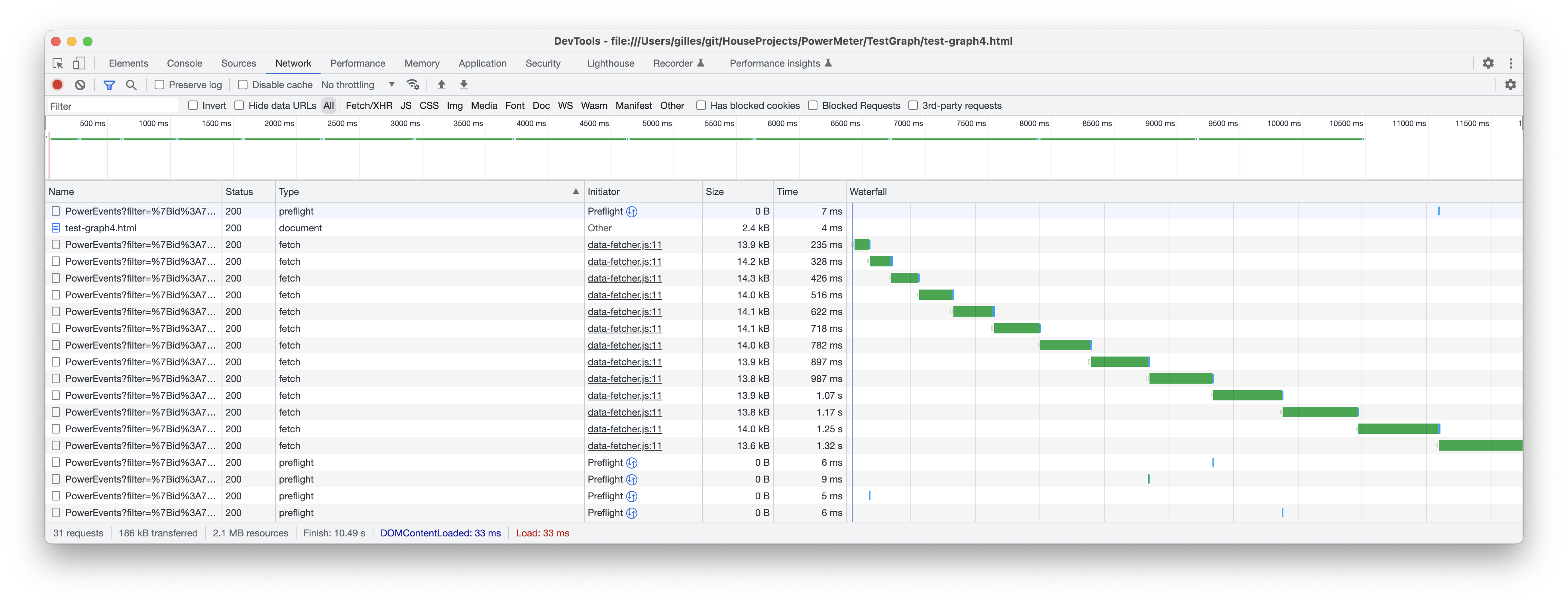





Doing a GET request to retrieve multiple pages of documents takes longer and longer for each subsequent page.
Expected Behavior
I would have expected RestHeart/MongoDB to cache the query meaning the initial Get (page 1) would have taken most of the time and getting the subsequent pages would have taken noticeably less time.
Current Behavior
Each time I increment the page (without changing the query) the request takes longer and longer to return the result:
Context
First request is this query and takes 300ms: http://192.168.2.11:8080/PowerEvents?filter=%7Bid%3A492%2Ctime%3A%7B%24gt%3A1668099145480%2C%24lt%3A1668185545480%7D%7D&sort=%7Btime%3A+1%7D&pagesize=1000&page=1
i.e.:
The last request is this query and takes 1280ms: http://192.168.2.11:8080/PowerEvents?filter=%7Bid%3A492%2Ctime%3A%7B%24gt%3A1668099145480%2C%24lt%3A1668185545480%7D%7D&sort=%7Btime%3A+1%7D&pagesize=1000&page=13
i.e.:
The collection is indexed by the "time" value.
The "id" is just a device identifier and is different from the MongoDB "_id" (which are unique).
I suspect I will hack it by always requesting "page=1" and just programmatically increment the time filter so that it matches the "next page" boundary (thus relying on the MongoDB index), but that should not have been necessary.
Also note that the browser correctly keeps the connection alive and re-use it to request the subsequent pages (perhaps that could have been used as a clue to determine when to create/clear the cache entry).
Environment
OS: Linux Debian 11: 5.10.0-19-amd64 SMP Debian 5.10.149-2 (2022-10-21) RestHeart version: 6.5.0 (JAR download variant) Java version: 17.0.4-amzn MongoDB version: 4.4.14 (Community Server)
Currently using the default config files with no modifications (other than the auth token).
Collection currently has 5 millions+ documents (but the query only retrieves around 15,000 of them).