 Outfluencer
commented
8 months ago
Outfluencer
commented
8 months ago i personally add a component serial and deserialisation cache to my bungee do speed exactly this up I think not using gson is a bad idea, as gson is the most widely used lib
 andreasdc
andreasdc Janmm14
Janmm14
 bob7l
bob7l md-5
md-5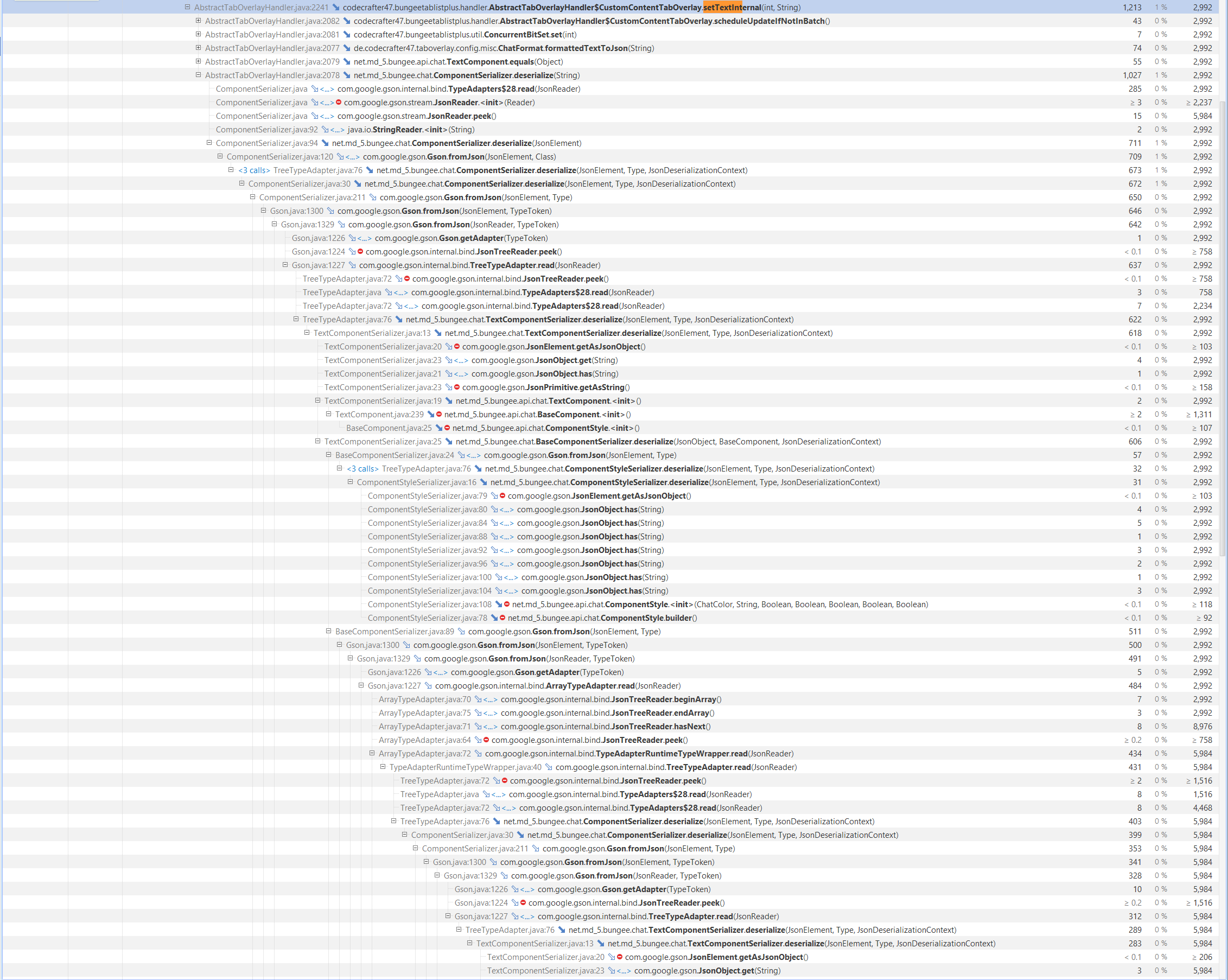{kind=link}
{kind=link}
{kind=link}
{kind=link}
Feature description
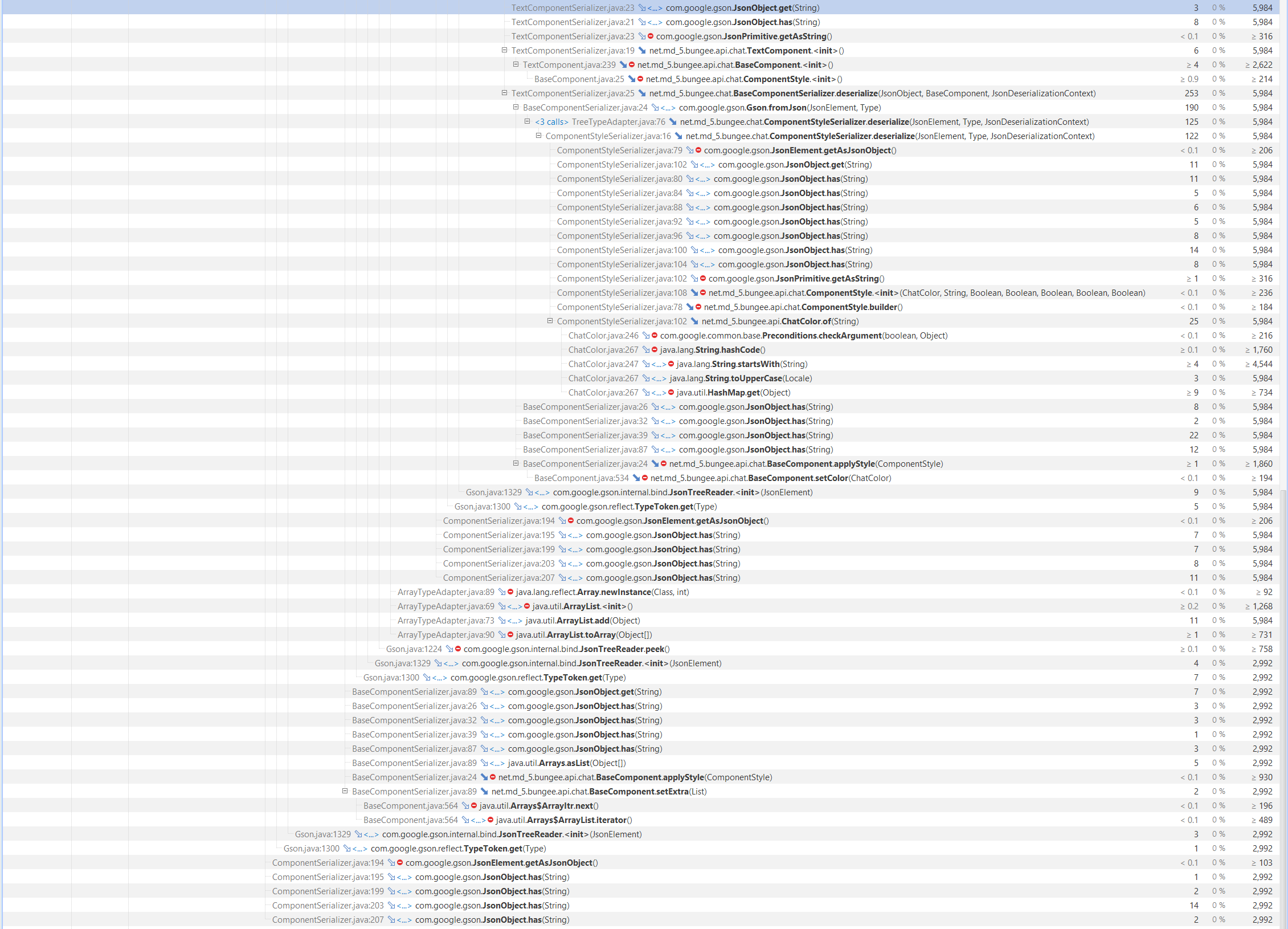
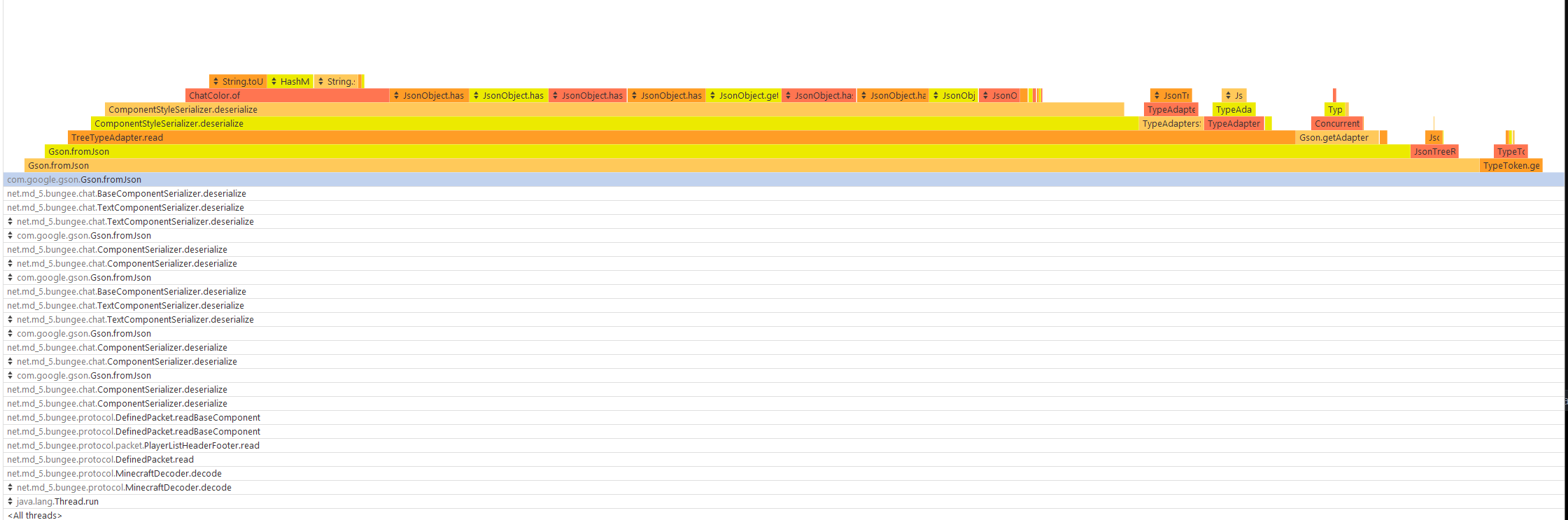
I was looking and the profiler and saw that serializing and deserializing of strings such as scoreboard components is taking some processing time, maybe it would be a good idea to change it to a faster library? The servers have scoreboard plugin, I think tablist plugin like https://github.com/CodeCrafter47/BungeeTabListPlus would have better performance too?

Goal of the feature
When looking at the results from here, gson, which is currently being used in BungeeCord, got 8677 ns, while for example fury-fastest got 442 and jackson 1994. This is almost 20x improvement with fury or 4x with jackson. https://github.com/eishay/jvm-serializers/wiki
Unfitting alternatives
-
Checking