 ademar
commented
5 years ago
ademar
commented
5 years ago @haraldsteinlechner thanks for taking the time to file this bug report; I'll get to it as soon as I get back to civilization (in a couple of days) as I'm currently traveling with limited internet access. I think we will find the source of contention in the buffer manager.
 haraldsteinlechner
haraldsteinlechner
 krauthaufen
krauthaufen
I encountered two (most likely independent) performance problems with suave websockets. A setup which demonstrates the problem can be achieved as such:
lurkerslurkers).In this setup here the WebSocket example has been modified in order to show the problem in a consice manner. For demostration, use the test repo, start the modified websocket example and open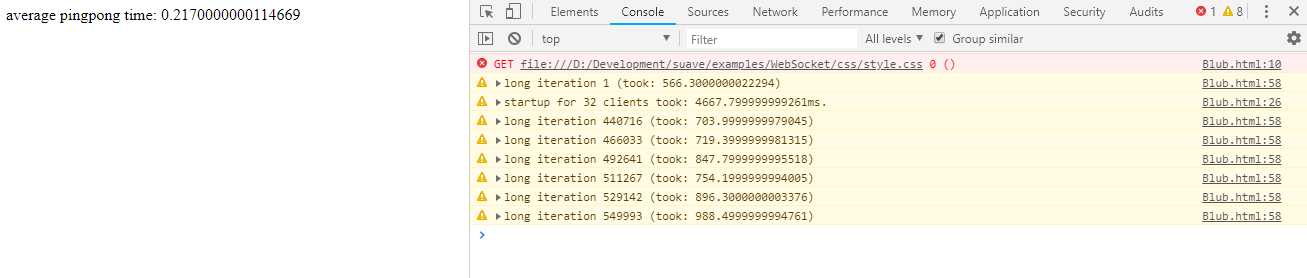
Blub.htmlavailable in the Websocket directory in a web browser. In your chrome you will see:Problem 1:
As you will see, typically the ping pong takes 0.21ms, however suddenly the application starts printing long iteration warning - showing more than 500ms roundtrip time. In the output log you will see stuff as such:
On a machine with more cpus or setting higher MinThreads in the threadpool this problem goes away. We will shortly submit an issue to coreclr @krauthaufen
The problem is simply the way async operations work on sockets in combination with varying workloads as simulated by the two kinds of sockets.
Problem 2:
Using many WebSocket connections, beginning from approx 10 take forever. You can see the connection time for 32 clients (as you will see in Blub.html) in the screenshot which is about 5seconds-20secons.
This is most likely due to problems in concurrent buffer management.