 SunXinFei
commented
4 years ago
SunXinFei
commented
4 years ago js中的继承
我们先说下《JS高级程序设计》中提到的组合式继承;继承即为继承父类属性和继承父类方法,组合式继承核心是使用call继承属性;原型对象上挂载要继承的方法;故为代码如下:
//父类构造函数
function SuperType(name){
this.name = name;
this.colors = ['red','white']
}
SuperType.prototype.sayName = function(){
console.log(this.name);
}
function SubType(name,age){
this.age = age;
SuperType.call(this, name);
}
SubType.prototype = new SuperType();
SubType.prototype.constructor = SubType;
SubType.prototype.sayAge = function(){
console.log(this.age);
}
let instance = new SubType('Nical',12);

缺点:父类构造函数执行了两次,SubType.prototype = new SuperType();会导致SubType.prototype挂载上父类的属性:name和colors,通过SuperType.call(this, name);在子类实例上挂载属性进行屏蔽。
寄生组合式继承
核心思想:复制一个父类的原型对象赋值给子类的prototype,不必为了指定子类的原型而调用超类构造函数。
/**
* subType- 子类型构造函数
* superType-超类型构造函数
*/
function inheritPrototype(subType, superType) {
//1.创建了超类(父类)原型的(副本)浅复制
var prototype = Object.create(superType.prototype);
/*
2.修正子类原型的构造函数属性
constructor属性也是对象才拥有的,它是从一个对象指向一个函数,含义就是指向该对象的构造函数
prototype.constructor 未修改前指向的 superType,为了弥补因重写原型而失去的默认constructor属性。
*/
prototype.constructor = subType;
// 3.将子类的原型替换为超类(父类)原型的(副本)浅复制
subType.prototype = prototype;
}function SuperType(name) {
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function () {
alert(this.name);
};
function SubType(name, age) {
//构造函数式继承--子类构造函数中执行父类构造函数
SuperType.call(this, name);
this.age = age;
}
// 核心:因为是对父类原型的复制,所以不包含父类的构造函数,也就不会调用两次父类的构造函数造成浪费
inheritPrototype(SubType, SuperType);
SubType.prototype.sayAge = function () {
alert(this.age);
}
var instance = new SubType("lichonglou");
console.log(instance.name)
// console.log(instance.constructor)//指向SubType 如果没有修正原型的构造函数,则会指向父类构造函数



异步与同步
单线程与多线程
js为什么是单线程?js语言在设计之初就是单线程的,原因其实也比较简单,js主要是针对浏览器使用,浏览器中单线程能够保证页面中DOM的渲染不出现异常,也正是这个原因,所以在现在新标准允许JavaScript脚本多线程中有一个严格的要求,子线程不能够进行DOM操作,来严格把控住,所以所谓js多线程,也就只能做一些业务上面的运算,比如数量非常大的数据清洗等等。
任务队列
Philip Roberts的PPT视频《Help, I'm stuck in an event-loop》中已经非常清晰地说明了关于任务队列的讲解:
宏任务&微任务
宏任务一般包括:整体代码script,setTimeout,setInterval, setImmediate。 微任务:Promise,process.nextTick , Object.observe [已废弃], MutationObserver
https://juejin.im/post/6844903764202094606
浏览器与node的区别
浏览器为: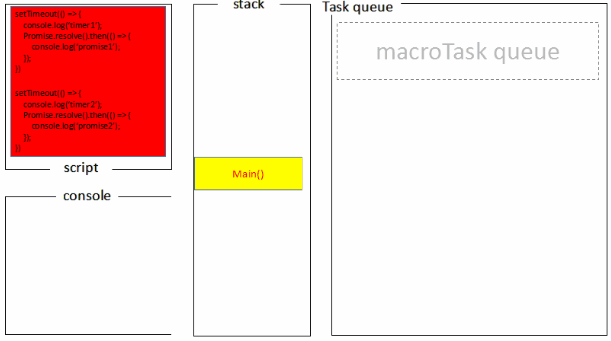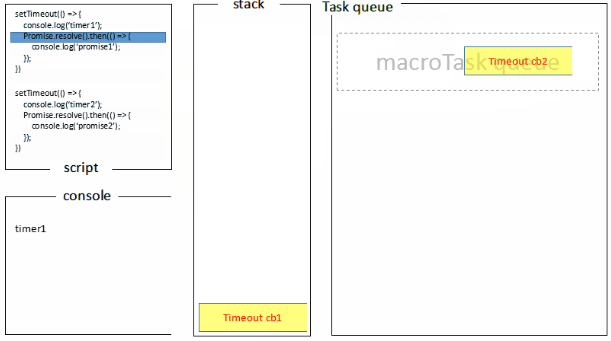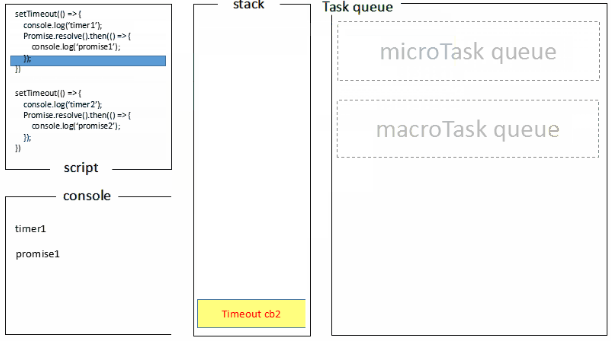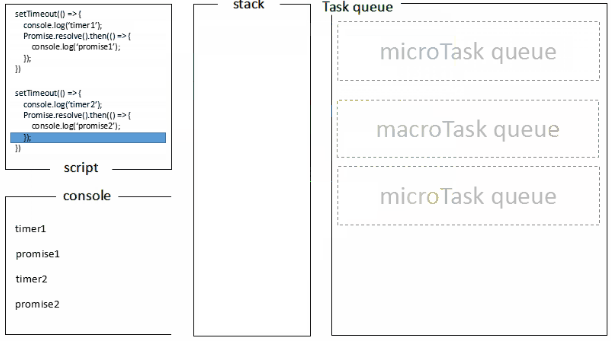 node为:
node为:
 浏览器环境下,microtask 的任务队列是每个 macrotask 执行完之后执行。而在 Node.js 中,microtask 会在事件循环的各个阶段之间执行,也就是一个阶段执行完毕,就会去执行 microtask 队列的任务。
浏览器环境下,microtask 的任务队列是每个 macrotask 执行完之后执行。而在 Node.js 中,microtask 会在事件循环的各个阶段之间执行,也就是一个阶段执行完毕,就会去执行 microtask 队列的任务。
SettimeOut
基于上面的任务队列,settimeOut函数也就可以解释一些参数0之类的问题了,方法先执行主线程中执行栈的方法,settimeout中的方法会放置到任务队列,并且先进先出,执行栈执行完之后,去任务队列中拿出方法放入执行栈去执行,直到结束为止。 其中delay的毫秒参数的含义如下,MDN,里面提到一点很重要实际延迟可能比预期的更长;这一点很容易理解:实际延迟的时间是看该延迟函数方法之前的那些主线程执行栈中方法执行的时间以及队列中放入执行栈去执行的时间。如果两者超出了延迟时间,那么就产生了实际延迟可能比预期的更长的现象,下面是实验代码验证这个观点
这个例子验证了一点,1000毫秒的含义,其实表示的是第一次运行到这里是1564650928851左右的时间,等到队列中的方法执行完之后,此时间隔时间如果超过了1000ms,则立即执行,如果低于1000ms,则去等待1000ms之后去执行。
这里就验证了,所谓的延迟100ms并不一定是相对延迟了100ms之后,就要去执行,实际延迟可能比预期的更长所以当队列执行到此时,时间已经延迟大于了100ms,所以就立即去执行log 2这个方法。