 Eliot-P
commented
4 years ago
Eliot-P
commented
4 years ago Mesure de performance et optimisation du nombre de threads
Mesure de temps
Suite au récent post sur les mesures de temps en code C, voici le résultat de mes recherches personelles :
Il y a plusieurs manières assez simple pour mesurer le temps pris par une foncion trouvable assez facilement sur internet, cependant elles ne sont pas toutes adaptées pour du multithreading. Les méthodes décritent ici font partie du module
Mesure de temps avec clock(3P)
Prennons comme exemple ce code :
double *timer_1(){
double time_taken;
clock_t start,end;
start = clock();
fun();
end = clock();
time_taken =1000*((double)(end - start) / (double)(CLOCKS_PER_SEC));
return time_taken;
}La fonction clock(3P) permet de mesurer le temps d'utilisation du processeur. Pour pouvoir obtenir un résultat en seconde il faut donc diviser le résultat par CLOCKS_PER_SEC. Bien que cette fonction soit interessante pour des programmes sans mutlithreading, celle-ci ne lira pas des valeurs correctes pour un programme multithread. En effet puisqu'un programme multithread utilise plusieurs coeur d'un processeur en même temps, c'est du temps processeur en plus alors que le temps réel, lui, reste le même.
Mesure de temps avec time(3P)
Prennons comme exemple ce code :
double timer_2(){
time_t start,end;
start = time(NULL);
fun();
end = time(NULL);
return (double)(end - start);
}La fonction time(3P) nous retourne le temps écoulé en seconde depuis "l'époque". L'époque est une date fixée, pour linux il s'agit du 1er janvier 1970 à 00h 00m 00s GMT (fun-fact, il s'agit de la date du début de l'ère UNIX). Il nous suffit ensuite de faire la différence entre end et start afin de trouver le temps écoulé. Bien que cette fonction lise des valeurs totalement correctes pour un programme singlethread et multithread, il peut être interessant de vouloir une précision supplémentaire en millisecondes.
Mesure de temps avec gettimeofday(3P)
Prennons comme exemple ce code :
double timer_3(){
struct timeval start,end;
gettimeofday(&start, NULL) ;
fun();
gettimeofday(&end,NULL);
double time_taken;
time_taken = (end.tv_sec - start.tv_sec) * 1e6;
time_taken = (time_taken + (end.tv_usec - start.tv_usec)) * 1e-6;
return time_taken;
}la fonction gettimeofday(3P) nous retourne une lecture précise de la date et de l'heure actuelle. Il nous suffit de nouveau donc de faire une difference entre les seconde et les micro secondes de end et start pour avoir le temps écoulé. Pour effectuer cette différence nous utilison les attributs .tv_sec et .tv_usec de la structure timeval décrite dans <sys/time.h>.
Optimisation du nombre de threads
Afin de trouver le nombre de threads optimal, il nous faudrait executer plusieurs fois le programme avec un nombre de threads différent à chaque execution. Cependant avec un même nombre de thread, le temps d'execution peut varier. Il est donc interessant d'executer le programme X fois pour n threads et ceci de 1 à N threads.
Pour pouvoir mettre tout ces résultats dans un joli graphique et pouvoir inclure ce dernier dans le rapport, une solution assez évidente est d'utiliser python et ses librairies matplotlib et numpy.
Prérequis
- Utiliser Linux
- Installer la librairie py-cpuinfo (pas obligatoire)
- Avoir executable du programme de la forme ./fact [-N nombre_de_threads] fichier_input fichier_output
- fact imprime UNIQUEMENT le temps en micro-seconde dans le terminal
Les imports
import os
from numpy import *
import matplotlib.pyplot as plt
import cpuinfoOn écrit premièrement une fonction qui prend comme argument le nombre de thread et qui retourne le temps pris en micro-secondes au moyen de la librairie os qui est comprise de base dans python :
def exec (Number_of_thread) :
execution = os.popen('./fact -N ' + str(Number_of_thread) + 'Input.txt Output.txt') #écrit dans le terminal
time_taken_raw = execution.read() #lit ce que l'execution écris dans le terminal
time_taken = float(time_taken_raw.strip()) #transforme en float et retire le "\n"
os.system('rm -rf Output.txt')
return time_takenOn écrit ensuite une fonction qui prend pour arguments le nombre de threads maximum et le nombre d'exéctuions du programme pour n threads :
def main (number_of_exec,max_number_of_thread):
big_array = []
for n in range (max_number_of_thread):
array_of_time_for_n_thread = []
for i in range (number_of_exec):
time_taken = around(exec(max_number_of_thread)*100,2)
array_of_time_for_n_thread.append(time_taken)
big_array.append(array_of_time_for_n_thread)
grapher(big_array)Et finalement il ne nous reste plus qu'à écrire la fonction [grapher()]() qui prend pour argument l'array des temps d'executions et retourne un graphique. Il s'agit uniquement de fonctions matplotlib et numpy de base, je n'entrerais donc pas dans les détails sur cette fonction
def grapher(array):
n = 1
ax = plt.subplot()
arr = asarray(array)
mean_arr = []
for n_thread in arr :
maxi = amax(n_thread)
mini = amin(n_thread)
moy = mean(n_thread)
ax.plot(n,maxi,'go',)
ax.text(n-0.05,maxi,maxi)
ax.plot(n,mini,'go')
ax.text(n-0.05,mini,mini)
ax.plot([n,n],[mini,maxi],'g')
ax.plot(n,moy,'bo')
mean_arr.append(moy)
n+=1
mean_numpy_arr = asarray(mean_arr)
ax.plot(range(1,n),mean_numpy_arr,'b--')
ax.axhline(amin(mean_numpy_arr))
ax.set_xlabel('Number of thread [N]')
ax.set_ylabel('Time [ms]')
ax.set_title("Execution de fact avec l'exemple d'input sur un processeur " + cpuinfo.get_cpu_info()['brand'].split("w/")[0] ,pad=30)
#l'appel à cpuinfo.get_cpu_info()['brand'].split("w/")[0] permet d'avoir le nom du processeur
plt.show()Et voilà après en entrant par exemple cette commande dans le programme python :
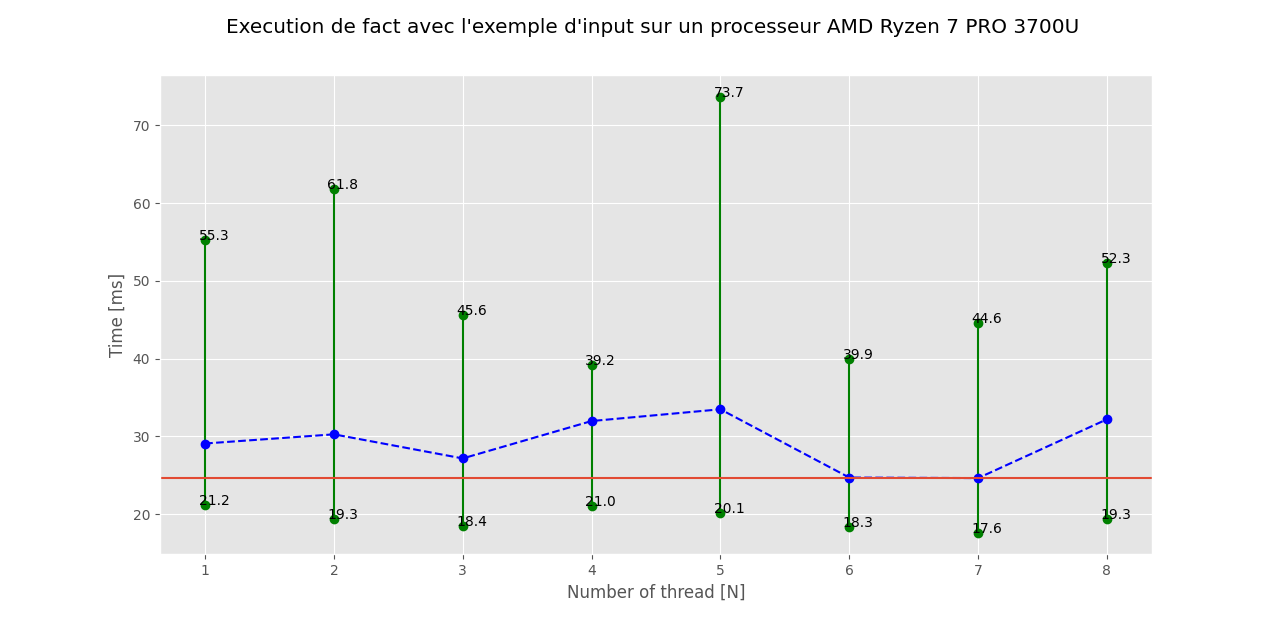
main(10, 8)Voici le graphique obtenu. En vert on peut voir le temps d execution maximum et minimum observés lors des X exéctuions pour n threads et en bleu la moyenne du temps mis pour n threads. Enfin en rouge on peut voir le minimum de la moyenne du graph.
 obonaventure
obonaventure
Bonjour Monsieur,
Suite au récents articles publié sur le blog, j'ai écris un article sur certaines manières de prendre des mesures de temps plus simples ainsi qu'une manière de représenter les temps d’exécutions sous python. Voici la proposition d'article.
Merci d'avance de votre réponse Eliot Peeters