 vincentpierre
commented
3 years ago
vincentpierre
commented
3 years ago Thank you for raising up this issue. We will be investigating. This is logged as MLA-1702 for internal tracking.
Closed Ihsees closed 1 year ago
vincentpierre
commented
3 years ago Thank you for raising up this issue. We will be investigating. This is logged as MLA-1702 for internal tracking.
 Ihsees
commented
3 years ago
Ihsees
commented
3 years ago Just to try to give more info, I set up an example environment that does close to nothing.
In every decision it gives a single observation. It's always 0. There is no reward.
For every 10000 steps it collects all received actions, bins them into a histogram and writes the resulting data to a csv-file.
I like to think of this environment of a scenario with a very sparse reward. And I'd expect the algorithm to try to maximize entropy as to explore more of the action-space.
However, even after a very low amout of steps (100000 steps is enough), the agent will only ever try -1 and 1.

using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Actuators;
public class EntropyTestAgent : Agent
{
int[] sampledActions = new int[401]; //actions will binned from -2 to 2 in increments of 0.01
long myStepCount;
// Start is called before the first frame update
void Start()
{
myStepCount = 0;
clearEntries();
}
void clearEntries()
{
//set all items to 0
System.Array.Clear(sampledActions, 0, sampledActions.Length);
}
void saveSampledActionsToDisk()
{
//first best code I could find to write csv-files
Debug.Log("writing to file " + Application.persistentDataPath + "\\sampledActions_" + myStepCount.ToString() + ".csv");
System.IO.StreamWriter writer = new System.IO.StreamWriter(Application.persistentDataPath + "\\sampledActions_" + myStepCount.ToString() + ".csv");
for (int i = 0; i < sampledActions.Length; i++)
{
writer.WriteLine(sampledActions[i]);
}
writer.Flush();
writer.Close();
}
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(0); //observation will never change
}
public override void OnActionReceived(ActionBuffers actions)
{
myStepCount++;
//add action to sampledActions-array
//get action
float action;
action = actions.ContinuousActions[0];
//find index
int indexToIncrease;
indexToIncrease = (int)((action + 2)/0.01f);
sampledActions[indexToIncrease]++;
if ((myStepCount % 1000)==0)
{
EndEpisode();
Debug.Log(base.CompletedEpisodes);
}
if ((myStepCount % 10000)==0)
{
saveSampledActionsToDisk();
//clear all entries to get ready for next 10k actions
clearEntries();
}
}
}This is my configuration, which I took directly from the Making a new Environment Page
behaviors:
EntropyTest:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 3.0e-4
beta: 5.0e-4
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
max_steps: 500000
time_horizon: 64
summary_freq: 10000this is how I call it:
mlagents-learn config\EntropyTest_config.yaml --run-id=EntropyTest_006 --time-scale=100
this is the entropy-output in tensorboard (shows 240k steps):

vincentpierre
commented
3 years ago Thank you, I was able to reproduce the issue. We are investigating this but like you said, the computation of entropy for clipped gaussian or tanhgaussian might be very hard to compute. This should not happen if there are enough rewards in the environment. An option could be clipping the standard deviation of the gaussian to avoid it to spread out too much, but this would probably cause other issues.
Ihsees
commented
3 years ago Thank you for having taken the time to investigate this. Not sure if your final sentence ("Therefore I will close this now and add this issue on our backlog") refers just to that PR or the general issue of ever-rising entropies with sparse rewards.
In the (now closed) PR you argue that exact entropy-calculation for the tanh-distribution is not worth it. I agree - if the alternative is having some sort of approximation. tanh-squashing sounds promising enough to me that I would give it a shot. But as far as I can tell the TanhGaussianDistInstance is just relying on the parent-class (GaussianDistInstance) for entropy calculation. Which brings me back to ever-rising entropies. Is that correct or am I missing something?
unmodified entropy-code of GaussianDist / TanhGaussianDist for reference:
class GaussianDistInstance(DistInstance):
def __init__(self, mean, std):
super().__init__()
self.mean = mean
self.std = std
def sample(self):
sample = self.mean + torch.randn_like(self.mean) * self.std
return sample
def log_prob(self, value):
var = self.std ** 2
log_scale = torch.log(self.std + EPSILON)
return (
-((value - self.mean) ** 2) / (2 * var + EPSILON)
- log_scale
- math.log(math.sqrt(2 * math.pi))
)
def pdf(self, value):
log_prob = self.log_prob(value)
return torch.exp(log_prob)
def entropy(self):
return torch.mean(
0.5 * torch.log(2 * math.pi * math.e * self.std ** 2 + EPSILON),
dim=1,
keepdim=True,
) # Use equivalent behavior to TF
def exported_model_output(self):
return self.sample()
class TanhGaussianDistInstance(GaussianDistInstance):
def __init__(self, mean, std):
super().__init__(mean, std)
self.transform = torch.distributions.transforms.TanhTransform(cache_size=1)
def sample(self):
unsquashed_sample = super().sample()
squashed = self.transform(unsquashed_sample)
return squashed
def _inverse_tanh(self, value):
capped_value = torch.clamp(value, -1 + EPSILON, 1 - EPSILON)
return 0.5 * torch.log((1 + capped_value) / (1 - capped_value) + EPSILON)
def log_prob(self, value):
unsquashed = self.transform.inv(value)
return super().log_prob(unsquashed) - self.transform.log_abs_det_jacobian(
unsquashed, value
)Hi,
I do not think we will be able to address this issue in the near future (This is what I meant on the closed PR). The issue of ever-rising entropy is real, but there is no easy solution to it.
The TanhGaussian distribution should NOT be using the underlying Gaussian distribution as entropy because they are not the same. (Our trainers currently do not use the entropy of the tanh gaussian distribution anywhere, so we did not implement the entropy method) :

If you want to try to approximate the entropy of the tanh distribution, I think this is the exact equation :

Is your feature request related to a problem? Please describe. I'm experimenting with self-play for my environment. My environment has 8 continous actions, around 50 observations, and a sparse reward for the main goal (due to the opponent getting better only around 1 reward per 2000-step episode). Training basic behaviour with a 2x512 layer network is possible, but I want to try more layers as well.
Even with reward shaping to provide more immediate rewards, my trainings need to run for a long time to train (the longest so far had 1 Billion (1.000.000.000) timesteps). The training times are not a problem, it will usually run for a week with me looking at tensorboard graphs from time to time.
I think with these high step-numbers I'm running into some quirks with how entropy is calculated that otherwise would not be noticeable: My entropy (as observed in tensorboard) is rising, but at some point my agent will only ever try actions that are either -1 or 1. The sampling of actions is much more predictable than the high entropy value suggests. The reported entropy in tensorboard tops out a little later.
Now, I should (and will) probably experiment with different values for beta to prevent the entropy from rising in the first place. But since entropy (and KL-divergence) are a central part of PPO, I think it is worth investigating what happens:
I'm still working with ml-agents-envs 0.21.1 and tensorflow, but I don't think entropy calculation has changed much. Currently it's implemented like this: https://github.com/Unity-Technologies/ml-agents/blob/fbd4bd7eea52e00f95182566024109f44242f0bc/ml-agents/mlagents/trainers/torch/distributions.py#L75
It is in line with entropy for a normal-distribution as described on wikipedia https://en.wikipedia.org/wiki/Normal_distribution
MLAgents, however, clips actions to [-1, 1]. And this changes everything.
The distribution that results from clipping is most closely described in wikipedia as a "Rectified Gaussian Distribution" https://en.wikipedia.org/wiki/Rectified_Gaussian_distribution
I think, basically, ML-Agents still samples from a Gauss-Distribution, but all values beyond the range of [-1 to 1] are set to -1 and 1.
This results in increased probablities of drawing -1 or 1. When drawn as a probability distribution those high probabilites will appear as spikes at -1 and 1.
Entropy of this distribution of course is much lower than the unclipped version (it's more predictable). The problem is that MLAgents' entropy-calculation doesn't take this into account, and so a viscious cycle begins:
Training stagnating? -> algorithm is rewarded for increasing entropy ->algorithm increases standard-deviation of the distribution -> increased standard-deviation leads to a higher reported entropy, but actually DECREASES the entropy -> agent exploring less of it's action space -> Training stagnating.
The discrepancy is more pronounced at higher standard-deviations where basically all of the probability in the clipped gaussian cumulates in two equally likely spikes at -1 and 1. (I think my y-values for that graph are scaled wrong, but you get the point): First diagram: clipped distribution for different standard-deviations Second diagram: X-axis shows sigma, y axis shows calculated entropy for clipped and unclipped distributions)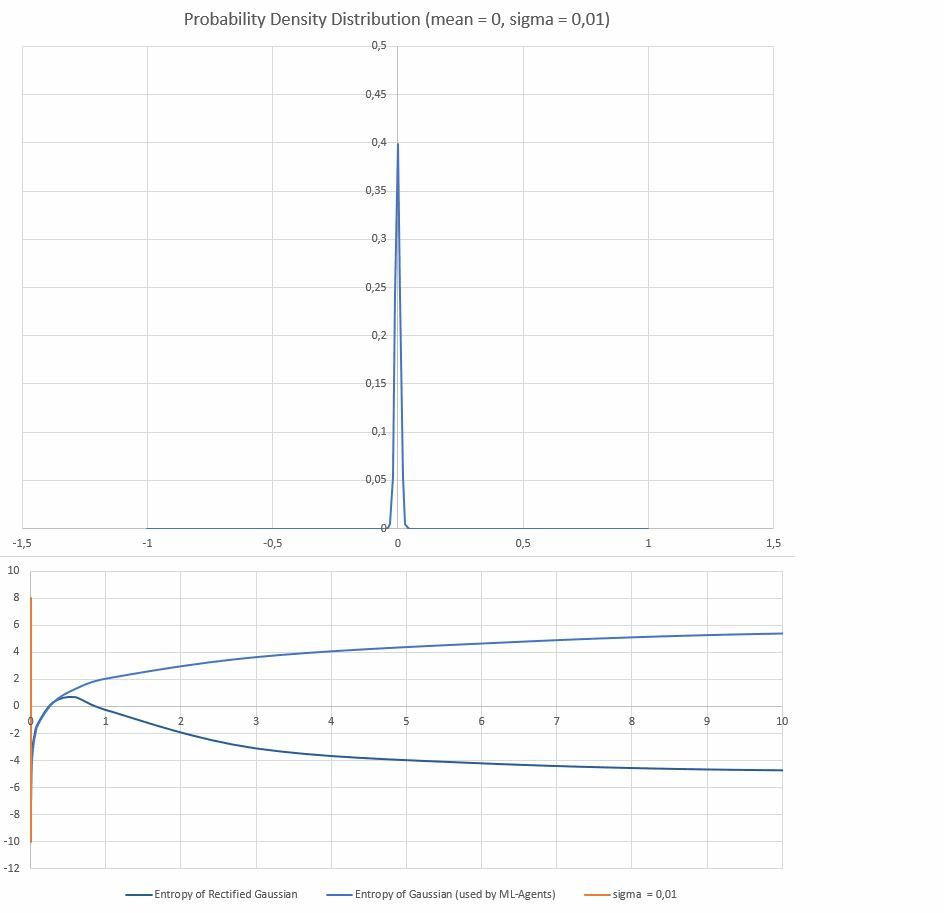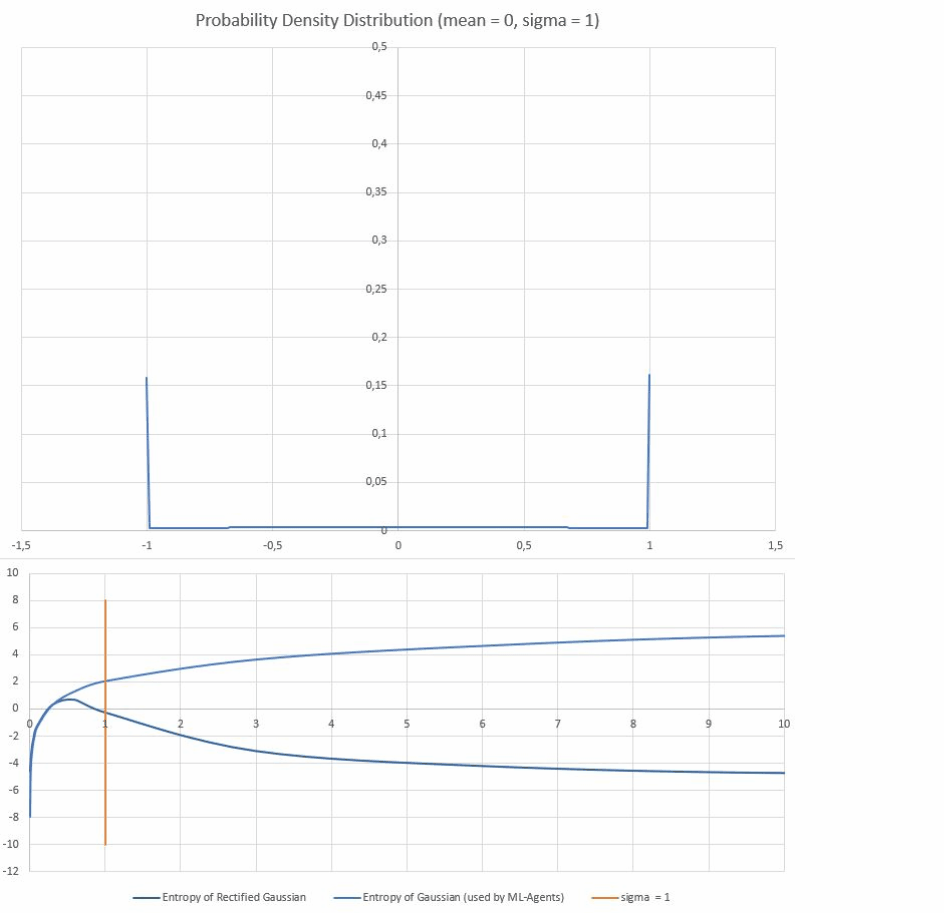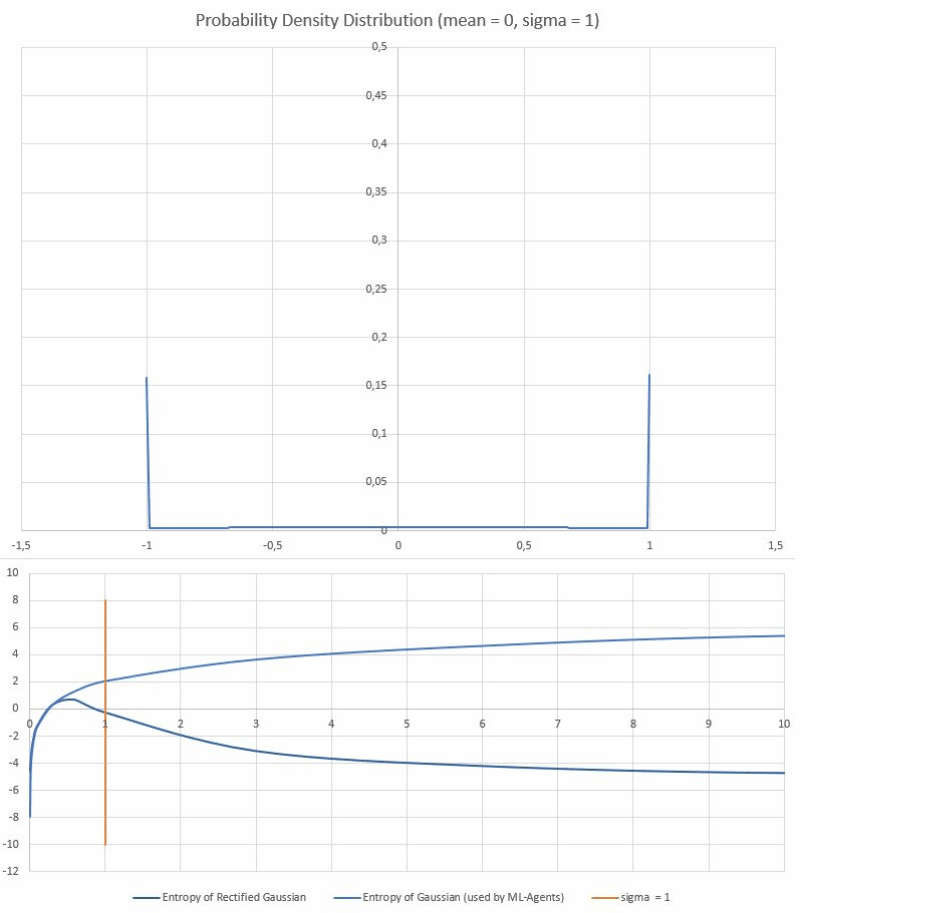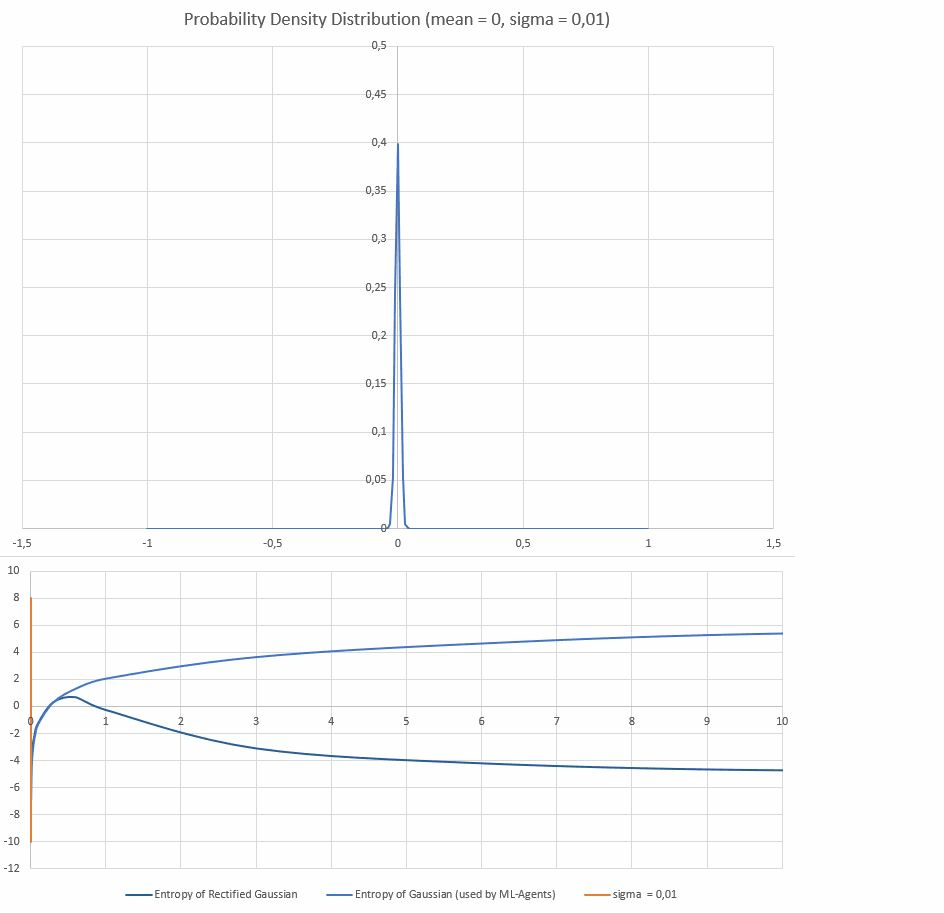
With a proper calculation of entropy the agent would actually get less entropy-reward for an inflated standard-deviation, thus pushing it to that local entropy-maximum at around 0.5 sigma. And explore more of its action space.
The way it is now, the agent is incentified to increase it's standard deviation more and more.
Describe the solution you'd like Implementing the entropy-function for a rectified distribution should improve training behaviour.
Unfortunately the math behind this (calculating a bounded integral from -1 to 1 for the entropy, then adding additional terms for everything that was "cut off"), is terrifying to me. Wolframalpha gave up on the integral-part, integral calculator came up with this monstrosity:
Input was this (remember to set the integral bounds in the "options"): 1/(E^((x - a)^2/(2b^2)) Sqrt[2 Pi] b)ln(1/(E^((x - a)^2/(2b^2)) Sqrt[2 Pi]* b))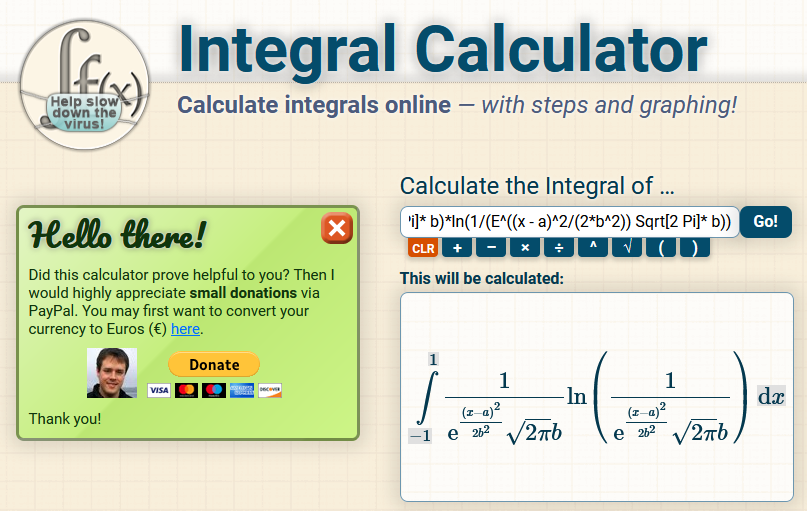
An approximation or look-up table would probably be better suited. Maybe someone more familiar in the ML-scene has stumpled across a paper for this problem? Can't imagine that this is the first time somebody has had this problem. I used Riemann-Integrals to approximate the values for the graphics. Which I'm happy with for demonstrating purposes, but will probably be much too slow for the actual training.
Describe alternatives you've considered Tuning hyper-parameter beta
Additional context I'm assuming that the stochastic nature of PPO can handle a change of the entropy-function and it's backpropagation. Or is there an explicit need for providing some kind of "inverse" of the entropy-function?