 Virtsionis
commented
2 years ago
Virtsionis
commented
2 years ago Hi! I missed that out. Your change was simply to add the corresponding deconv layers right? Thanks a lot for pointing that out! I will make the change ASAP!
PS: The caps weren't necessary... It's a two men open source project and we are trying to help people here.
 zhgqcn
zhgqcn oublalkhalid
oublalkhalid
I had prosed the issue about the vae. The problem was that the mu and std were always the same and the VAE loss didn't drop well.
Now I know the problem is that your VAE decoder is wrong ! As you can see from the picture blow , all the deconvolution layers use the same layer named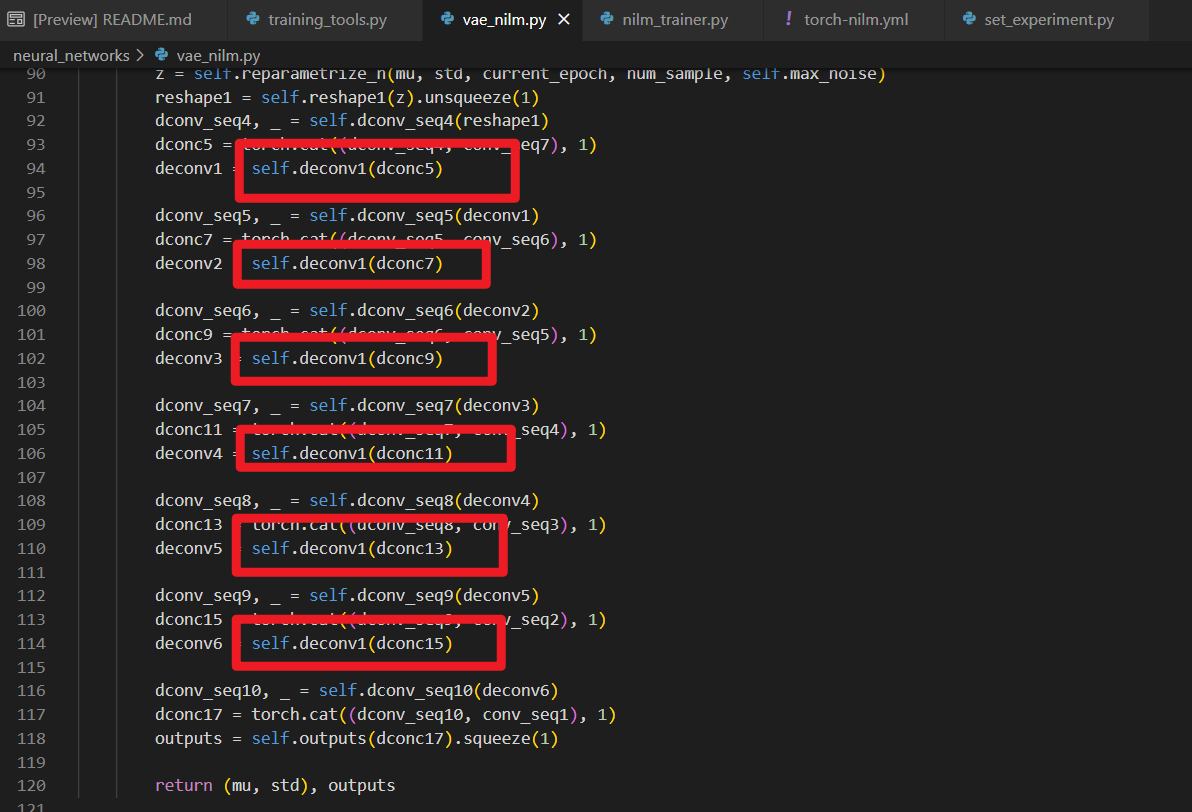
self.deconv1, which seriously affects network performance.After my change, the vae loss drops well