 Justin0388
commented
7 months ago
Justin0388
commented
7 months ago 我先做一版翻译的初稿吧
Closed WenjieDu closed 6 months ago
Justin0388
commented
7 months ago 我先做一版翻译的初稿吧
Justin0388
commented
7 months ago 一个致力于部分观测时间序列(POTS)机器学习任务的Python工具箱










⦿ 开发背景: 在现实数据收集场景下,收集者常常会面临传感器故障、通信异常、受访者隐私保护等问题,导致最终收集的时间序列数据集中存在缺失值。
数据缺失将会严重影响数据使用者后续的深入分析与应用,那么如何对现实场景下部分观测时间序列(POTS)进行机器学习建模成为一个亟需解决的问题。
当前市面上也还没有适用于POTS的机器学习专用工具箱。因此,旨在填补该空白的“PyPOTS”工具箱应运而生。
⦿ 应用意义: PyPOTS(发音为"Pie Pots")旨在成为一个让POTS的机器学习任务变得简单的工具箱。工程师和研究人员可以通过PyPOTS轻松处理其数据集中的缺失部分,
进而让他们能够聚焦于解决核心问题。PyPOTS目前已涵盖大量经典的以及先进的多变量POTS机器学习算法,后续也将持续整合该领域最新的算法。除了各种算法外,
PyPOTS还将拥有统一的API以及详细文档和交互式案例教程。
🤗 如果您认为PyPOTS是一个有用的工具箱,请将该项目设为星标🌟,以帮助更多人关注到它。
🤗 如果PyPOTS对您的研究有帮助,请在您的成果中 引用 PyPOTS。这对我们的开源研究工作具有重大意义,感谢您的支持!
该说明文档的后续内容如下: ❖ 支持的算法, ❖ PyPOTS 生态系统, ❖ 安装说明, ❖ 应用案例, ❖ 引用 PyPOTS, ❖ 贡献声明, ❖ 项目社区。
PyPOTS当前支持多变量POTS的填充,分类,聚类,预测以及异常检测任务。下表描述了当前PyPOTS中所集成的算法以及对应支持的任务类型。 符号 ✅ 表示该算法当前支持相应的任务(注请意,模型将在未来持续更新以,应对当前不暂支持的任务,敬请期待!),相关参考文献见本文档末尾。
🌟 在 v0.2版本更新后, PyPOTS中所有神经网络模型都具备超参数优化功能。此功能基于 Microsoft NNI 框架实现。 您可以参考我们的时间序列填充综述项目 Awesome_Imputation,了解如何配置和调整超参数。
🔥 请注意:Transformer, Crossformer, PatchTST, DLinear, ETSformer, FEDformer, Informer, Autoformer 模型在其原始论文中并未提出如何用作填充方法,并且这些模型也不接受POTS作为输入。 为了使上述模型能够适用于POTS数据,我们采用了与 SAITS paper 中相同的嵌入策略和训练方法(ORT+MIT)进行改进。
| 类型 | 算法 | 填充 | 预测 | 分类 | 聚类 | 异常检测 | 年份 |
|---|---|---|---|---|---|---|---|
| Neural Net | SAITS[^1] | ✅ | 2023 | ||||
| Neural Net | Crossformer[^16] | ✅ | 2023 | ||||
| Neural Net | TimesNet[^14] | ✅ | 2023 | ||||
| Neural Net | PatchTST[^18] | ✅ | 2023 | ||||
| Neural Net | DLinear[^17] | ✅ | 2023 | ||||
| Neural Net | ETSformer[^19] | ✅ | 2023 | ||||
| Neural Net | FEDformer[^20] | ✅ | 2022 | ||||
| Neural Net | Raindrop[^5] | ✅ | 2022 | ||||
| Neural Net | Informer[^21] | ✅ | 2021 | ||||
| Neural Net | Autoformer[^15] | ✅ | 2021 | ||||
| Neural Net | CSDI[^12] | ✅ | ✅ | 2021 | |||
| Neural Net | US-GAN[^10] | ✅ | 2021 | ||||
| Neural Net | CRLI[^6] | ✅ | 2021 | ||||
| Probabilistic | BTTF[^8] | ✅ | 2021 | ||||
| Neural Net | GP-VAE[^16] | ✅ | 2020 | ||||
| Neural Net | VaDER[^7] | ✅ | 2019 | ||||
| Neural Net | M-RNN[^9] | ✅ | 2019 | ||||
| Neural Net | BRITS[^3] | ✅ | ✅ | 2018 | |||
| Neural Net | GRU-D[^4] | ✅ | ✅ | 2018 | |||
| Neural Net | Transformer[^2] | ✅ | 2017 | ||||
| Naive | LOCF/NOCB | ✅ | |||||
| Naive | Mean | ✅ | |||||
| Naive | Median | ✅ |
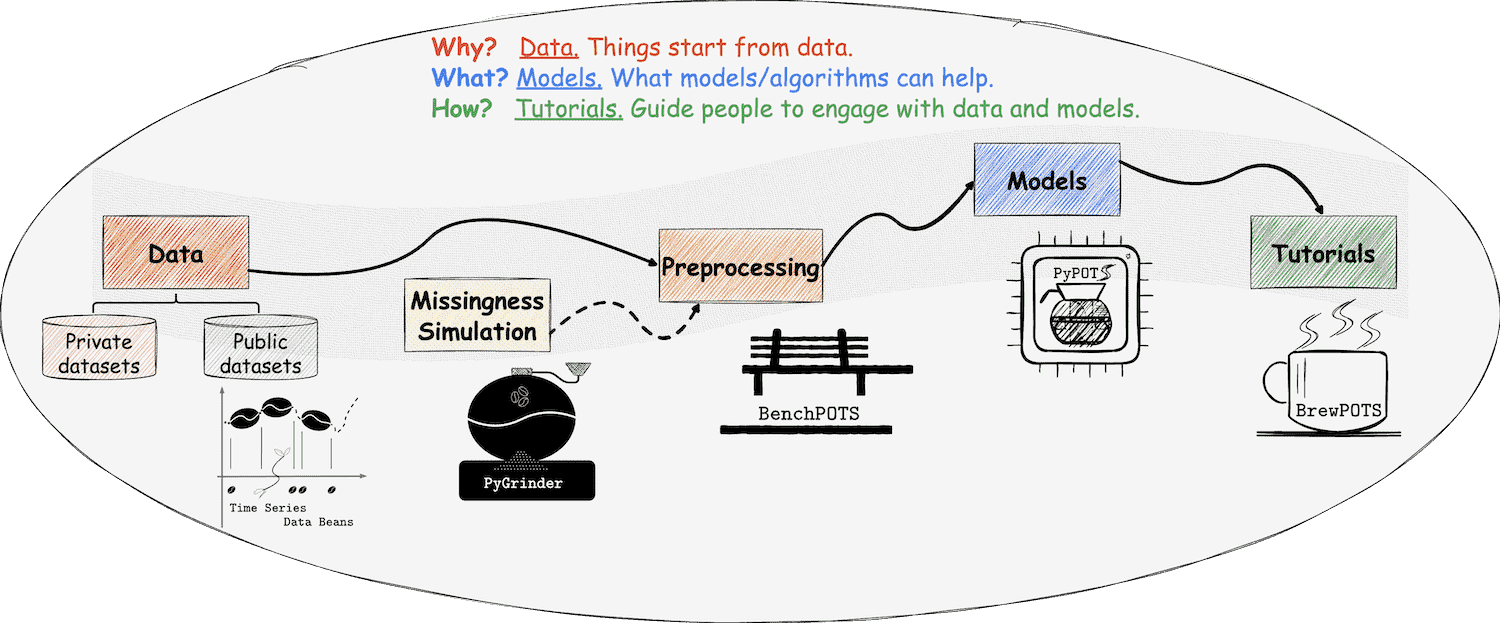
在PyPOTS生态系统中,一切都与我们熟悉的咖啡息息相关,甚至可以将其视为一杯咖啡的诞生过程! 如您所见,PyPOTS的标志中有一个咖啡壶。除此之外还需要什么呢?请听我徐徐道来。
👈 在PyPOTS中,时间序列数据集可以被看作咖啡豆,而POTS数据集则是带缺失部分的不完整咖啡豆。 为了让用户能够轻松使用各种开源的时间序列数据集,我们创建了时间序列数据库:Time Series Data Beans (TSDB)(可以将其视为咖啡豆仓库),使加载时间序列数据集变得超级简单! 访问 TSDB,了解更多关于该工具🛠的信息,它目前总共支持168个开源数据集!
👉 为了在真实数据中模拟缺失进而获得不完整的咖啡豆,我们创建了生态系统中的另一个库:PyGrinder(可以将其视为磨豆机), 帮助您在输入数据集中模拟缺失。根据Robin的理论[^13],缺失模式分为三类:完全随机缺失(MCAR)、随机缺失(MAR)和非随机缺失(MNAR)。 PyGrinder支持以上所有模式并提供与缺失相关的其他功能。通过PyGrinder,您可以仅仅通过一行代码将模拟缺失引入您的数据集中。
👈 现在我们有了咖啡豆、磨豆机和咖啡壶,那么如何给自己冲一杯咖啡呢?冲泡教程是必不可少的!考虑到未来的工作量, PyPOTS的相关教程将发布在一个独立的仓库:BrewPOTS中。点击查看案例,学习如何冲泡您的POTS数据集!
☕️ 欢迎来到 PyPOTS 生态系统 !
您可以参考PyPOTS文档中的 安装说明 以获取更详细的指南。 PyPOTS可以在 PyPI 和 Anaconda 上安装。 您可以按照以下方式安装PyPOTS,TSDB以及PyGrinder:
# 通过 pip
pip install pypots # 首次安装
pip install pypots --upgrade # 更新为最新版本
# 利用最新源代码安装,可能带有尚未正式发布的最新功能
pip install https://github.com/WenjieDu/PyPOTS/archive/main.zip
# 通过 conda
conda install -c conda-forge pypots # 首次安装
conda update -c conda-forge pypots # 更新为最新版本除了 BrewPOTS 之外, 您还可以在 Google Colab
上找到一个简单快速的入门教程。如果您有其他问题,请参考 PyPOTS文档。您也可以在我们的 社区 中 提出问题。
下面是使用PyPOTS进行POTS填充的示例用法,您可以点击下方进行查看。
[!注意] [2024年2月更新] 😎 我们的综述论文 Deep Learning for Multivariate Time Series Imputation: A Survey 已在 arXiv 上发布, 代码在GitHub 项目(Awesome_Imputation )上开源。 我们全面综述了最新基于深度学习的时间序列填充方法文献并对现有的方法进行分类,除此之外,还讨论了该领域当前的挑战和未来发展方向。
[2023年6月更新] 🎉 PyPOTS论文的精简版已被 第9届SIGKDD时间序列挖掘和学习 国际研讨会(MiLeTS'23)接收。 此外,PyPOTS已被纳入PyTorch 生态系统。
介绍PyPOTS的论文可以通过该 地址 在arXiv上获取,我们正在努力将其发表在更具影响力的学术期刊上, 例如持续跟进 机器学习开源软件 的JMLR期刊。 如果您在工作中使用了PyPOTS,请按照以下格式引用并为将项目设为星标🌟,以便让更多人关注它,对此我们深表感谢🤗。
据不完全统计,该 列表 为当前使用PyPOTS并在其论文中进行引用的科学研究项目
@article{du2023pypots,
title={{PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series}},
author={Wenjie Du},
year={2023},
eprint={2305.18811},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2305.18811},
doi={10.48550/arXiv.2305.18811},
}或者
Wenjie Du. (2023). PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series. arXiv, abs/2305.18811.https://arxiv.org/abs/2305.18811
非常欢迎您为这个优质的项目做出贡献!
通过提交您的代码,您将能收获:
模板 (如:
pypots/imputation/template) 进行快速开发;您也可以通过为该项目设置星标🌟 ,帮助更多人关注它。 您的星标🌟 既是对PyPOTS的认可,也是对PyPOTS发展所做出的重要贡献!
👀 在 PyPOTS 网站 上可以查看我们用户所属机构的完整列表!
我们非常关心用户的反馈,因此我们正在建立PyPOTS社区:
如果您有任何建议,想法,或打算分享与时间序列相关的论文,请加入我们并告诉我们。 PyPOTS社区一个开放、透明、友好的社区,让我们共同努力建设和改进PyPOTS!
[^1]: Du, W., Cote, D., & Liu, Y. (2023). SAITS: Self-Attention-based Imputation for Time Series. Expert systems with applications. [^2]: Vaswani, A., Shazeer, N.M., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., & Polosukhin, I. (2017). Attention is All you Need. NeurIPS 2017. [^3]: Cao, W., Wang, D., Li, J., Zhou, H., Li, L., & Li, Y. (2018). BRITS: Bidirectional Recurrent Imputation for Time Series. NeurIPS 2018. [^4]: Che, Z., Purushotham, S., Cho, K., Sontag, D.A., & Liu, Y. (2018). Recurrent Neural Networks for Multivariate Time Series with Missing Values. Scientific Reports. [^5]: Zhang, X., Zeman, M., Tsiligkaridis, T., & Zitnik, M. (2022). Graph-Guided Network for Irregularly Sampled Multivariate Time Series. ICLR 2022. [^6]: Ma, Q., Chen, C., Li, S., & Cottrell, G. W. (2021). Learning Representations for Incomplete Time Series Clustering. AAAI 2021. [^7]: Jong, J.D., Emon, M.A., Wu, P., Karki, R., Sood, M., Godard, P., Ahmad, A., Vrooman, H.A., Hofmann-Apitius, M., & Fröhlich, H. (2019). Deep learning for clustering of multivariate clinical patient trajectories with missing values. GigaScience. [^8]: Chen, X., & Sun, L. (2021). Bayesian Temporal Factorization for Multidimensional Time Series Prediction. IEEE transactions on pattern analysis and machine intelligence. [^9]: Yoon, J., Zame, W. R., & van der Schaar, M. (2019). Estimating Missing Data in Temporal Data Streams Using Multi-Directional Recurrent Neural Networks. IEEE Transactions on Biomedical Engineering. [^10]: Miao, X., Wu, Y., Wang, J., Gao, Y., Mao, X., & Yin, J. (2021). Generative Semi-supervised Learning for Multivariate Time Series Imputation. AAAI 2021. [^11]: Fortuin, V., Baranchuk, D., Raetsch, G. & Mandt, S. (2020). GP-VAE: Deep Probabilistic Time Series Imputation. AISTATS 2020. [^12]: Tashiro, Y., Song, J., Song, Y., & Ermon, S. (2021). CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation. NeurIPS 2021. [^13]: Rubin, D. B. (1976). Inference and missing data. Biometrika. [^14]: Wu, H., Hu, T., Liu, Y., Zhou, H., Wang, J., & Long, M. (2023). TimesNet: Temporal 2d-variation modeling for general time series analysis. ICLR 2023 [^15]: Wu, H., Xu, J., Wang, J., & Long, M. (2021). Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. NeurIPS 2021. [^16]: Zhang, Y., & Yan, J. (2023). Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. ICLR 2023. [^17]: Zeng, A., Chen, M., Zhang, L., & Xu, Q. (2023). Are transformers effective for time series forecasting?. AAAI 2023 [^18]: Nie, Y., Nguyen, N. H., Sinthong, P., & Kalagnanam, J. (2023). A time series is worth 64 words: Long-term forecasting with transformers. ICLR 2023 [^19]: Woo, G., Liu, C., Sahoo, D., Kumar, A., & Hoi, S. (2023). ETSformer: Exponential Smoothing Transformers for Time-series Forecasting. ICLR 2023 [^20]: Zhou, T., Ma, Z., Wen, Q., Wang, X., Sun, L., & Jin, R. (2022). FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting. ICML 2022. [^21]: Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., & Zhang, W. (2021). Informer: Beyond efficient transformer for long sequence time-series forecasting. AAAI 2021.
 phoebeysj
commented
7 months ago
phoebeysj
commented
7 months ago hi ,我按照自己的理解修改了几个部分:
 CowboyH
commented
7 months ago
CowboyH
commented
7 months ago 建议专业术语和专有名词给出英语的全称和简称,我的主要修改如下: ⦿动机:由于传感器故障、通信受阻和不可预见的错误等原因,现实环境中收集的时间序列常存在缺失值。这使得部分观测时间序列(partially-observed time series,简称为POTS)成为开放世界建模中普遍存在的问题,但大多数方法无法面向POTS建模。尽管存在巨大的研究,工程和实践空白,但当前没有专门针对POTS开发的工具箱。PyPOTS就是为了填补这一空白而诞生并进行后续迭代。 ⦿愿景:PyPOTS(发音为 "Pie Pots")是一个易上手的工具箱,以帮助工程师,研究者更加专注于面向PyPOTS建模的核心问题,而不是花费大量精力进行繁琐的数据预处理。PyPOTS会持续不断的更新关于部分观测多变量时间序列(partially-observed multivariate time series)的经典算法和当前最优算法。除此之外,PyPOTS还提供了统一的应用程序接口(Application programming interfaces,简称为APIs),详细的算法学习指南和应用示例。
PyPOTS 支持对多变量部分观测时间序列进行插补、分类、聚类、预测和异常检测。下表显示了 PyPOTS 中每个算法在不同任务中的可用性。符号 ✅ 表示该算法可用于相应的任务(请注意,模型将来会不断更新以处理当前不支持的任务。敬请关注❗️)
根据 Robin 的理论,缺失模式分为三类:完全随机缺失(missing completely at random,简称为MCAR)、随机缺失(missing at random,简称为MAR)和非随机缺失(missing not at random,简称为MNAR )。
示例代码的第一个注释建议修改为:使用PyPOTS帮助完成繁琐的数据预处理
Justin0388
commented
7 months ago 汇总了一下近期各位伙伴们给出的修改建议,下面是 中文ReadmeV2.0,再一起看看还有没有润色改进的空间!
Justin0388
commented
7 months ago 一个致力于部分观测时间序列(POTS)机器学习任务的Python工具箱
⦿ 开发背景: 由于传感器故障、通信异常以及不可预见的未知原因,在现实环境中收集的时间序列数据普遍存在缺失值,这使得部分观测时间序列(partially-observed time series,简称为POTS)成为开放世界建模中普遍存在的问题。
数据缺失将会严重影响数据使用者后续的深入分析与应用,那么如何面向POTS建模成为一个亟需解决的问题。尽管已存在大量的研究,但当前没有专门针对POTS建模开发的工具箱。基于此,旨在填补该领域空白的“PyPOTS”工具箱应运而生。
⦿ 应用意义: PyPOTS(发音为"Pie Pots")是一个易上手的工具箱,工程师和研究人员可以通过PyPOTS轻松处理其数据集中的缺失部分,进而将注意力更多地聚焦在要解决的核心问题上。PyPOTS会持续不断的更新关于部分观测多变量时间序列(partially-observed multivariate time series)的经典算法和先进算法。除此之外,PyPOTS还提供了统一的应用程序接口(Application programming interfaces,简称为APIs),详细的算法学习指南和应用示例。
🤗 如果您认为PyPOTS是一个有用的工具箱,请将该项目设为星标🌟,以帮助它被更多人所了解。
🤗 如果PyPOTS对您的研究有帮助,请在您的成果中 引用 PyPOTS。这是对我们开源研究工作的最大支持,感谢您的支持!
该说明文档的后续内容如下: ❖ 支持的算法, ❖ PyPOTS 生态系统, ❖ 安装教程, ❖ 使用案例, ❖ 引用 PyPOTS, ❖ 贡献声明, ❖ 项目社区。
PyPOTS当前支持多变量POTS数据的插补,预测,分类,聚类以及异常检测五类任务。下表描述了当前PyPOTS中所集成的算法以及对应不同任务的可用性。 符号 ✅ 表示该算法当前可用于相应的任务(请注意,我们将在未来持续发布更新以支持当前暂不支持的任务,敬请关注哦!),相关参考文献见本文档末尾。
🌟 在 v0.2版本更新后, PyPOTS中所有神经网络模型都支持超参数优化。此功能基于 Microsoft NNI 框架实现。 您可以通过参考我们的时间序列插补综述项目 Awesome_Imputation,了解如何配置和调整模型超参数。
🔥 请注意:Transformer, Crossformer, PatchTST, DLinear, ETSformer, FEDformer, Informer, Autoformer 模型在其原始论文中并未提及用作插补方法,并且这些模型也不接受POTS数据作为输入。 为了使上述模型能够适用于POTS数据,我们采用了与 SAITS paper 中相同的嵌入策略和训练方法(ORT+MIT)进行改进。
| 类型 | 算法 | 插补 | 预测 | 分类 | 聚类 | 异常检测 | 年份 |
|---|---|---|---|---|---|---|---|
| Neural Net | SAITS[^1] | ✅ | 2023 | ||||
| Neural Net | Crossformer[^16] | ✅ | 2023 | ||||
| Neural Net | TimesNet[^14] | ✅ | 2023 | ||||
| Neural Net | PatchTST[^18] | ✅ | 2023 | ||||
| Neural Net | DLinear[^17] | ✅ | 2023 | ||||
| Neural Net | ETSformer[^19] | ✅ | 2023 | ||||
| Neural Net | FEDformer[^20] | ✅ | 2022 | ||||
| Neural Net | Raindrop[^5] | ✅ | 2022 | ||||
| Neural Net | Informer[^21] | ✅ | 2021 | ||||
| Neural Net | Autoformer[^15] | ✅ | 2021 | ||||
| Neural Net | CSDI[^12] | ✅ | ✅ | 2021 | |||
| Neural Net | US-GAN[^10] | ✅ | 2021 | ||||
| Neural Net | CRLI[^6] | ✅ | 2021 | ||||
| Probabilistic | BTTF[^8] | ✅ | 2021 | ||||
| Neural Net | GP-VAE[^16] | ✅ | 2020 | ||||
| Neural Net | VaDER[^7] | ✅ | 2019 | ||||
| Neural Net | M-RNN[^9] | ✅ | 2019 | ||||
| Neural Net | BRITS[^3] | ✅ | ✅ | 2018 | |||
| Neural Net | GRU-D[^4] | ✅ | ✅ | 2018 | |||
| Neural Net | Transformer[^2] | ✅ | 2017 | ||||
| Naive | LOCF/NOCB | ✅ | |||||
| Naive | Mean | ✅ | |||||
| Naive | Median | ✅ |
在PyPOTS生态系统中,一切都与我们熟悉的咖啡息息相关,甚至可以将其视为一杯咖啡的诞生过程! 如您所见,PyPOTS的标志中有一个咖啡壶。除此之外还需要什么呢?请听我徐徐道来。
👈 在PyPOTS中,时间序列数据可以被看作一连串的咖啡豆,而POTS数据则是带缺失部分的不完整咖啡豆。 为了让用户能够轻松使用各种开源的时间序列数据集,我们创建了时间序列数据库:Time Series Data Beans (TSDB)(可以将其视为咖啡豆仓库),使加载时间序列数据集变得超级简单! 访问 TSDB,了解更多关于该工具🛠的信息,它目前总共支持168个开源数据集!
👉 为了在真实数据中模拟缺失进而获得不完整的咖啡豆,我们创建了生态系统中的另一个库:PyGrinder(可以将其视为磨豆机), 帮助您在输入数据集中模拟缺失。根据Robin的理论[^13],缺失模式分为三类:完全随机缺失(missing completely at random,简称为MCAR)、随机缺失(missing at random,简称为MAR)和非随机缺失(missing not at random,简称为MNAR )。 PyGrinder支持以上所有模式并提供与缺失相关的其他功能。通过PyGrinder,您可以仅仅通过一行代码将模拟缺失引入您的数据集中。
👈 现在我们有了咖啡豆、磨豆机和咖啡壶,那么如何给自己冲一杯咖啡呢?冲泡教程是必不可少的!考虑到未来的工作量, PyPOTS的相关教程将发布在一个独立的仓库:BrewPOTS中。点击查看案例,学习如何冲泡您的POTS数据!
☕️ 欢迎来到 PyPOTS 生态系统 !
您可以参考PyPOTS文档中的 安装说明 以获取更详细的指南。 PyPOTS可以在 PyPI 和 Anaconda 上安装。 您可以按照以下方式安装PyPOTS,TSDB以及PyGrinder:
# 通过 pip
pip install pypots # 首次安装
pip install pypots --upgrade # 更新为最新版本
# 利用最新源代码安装最新版本,可能带有尚未正式发布的最新功能
pip install https://github.com/WenjieDu/PyPOTS/archive/main.zip
# 通过 conda
conda install -c conda-forge pypots # 首次安装
conda update -c conda-forge pypots # 更新为最新版本除了 BrewPOTS 之外, 您还可以在 Google Colab
上找到一个简单且快速的入门教程。如果您有其他问题,请参考 PyPOTS文档。您也可以在我们的 社区 中 提出问题。
下面,我们为您演示使用PyPOTS进行POTS数据插补的示例,您可以点击以下链接查看:
:bulb: 注意 [2024年2月更新] 😎 我们的综述论文 Deep Learning for Multivariate Time Series Imputation: A Survey 已在 arXiv 上发布, 代码已在GitHub 项目(Awesome_Imputation )上开源。 我们全面综述了最新基于深度学习的时间序列插补方法文献并对现有的方法进行分类,除此之外,还讨论了该领域当前的挑战和未来发展方向。
[2023年6月更新] 🎉 PyPOTS论文的精简版已被第9届SIGKDD 时间序列挖掘和学习 国际研讨会(MiLeTS'23)接收。 此外,PyPOTS已被纳入PyTorch 生态系统。
介绍PyPOTS的论文可以通过该 地址 在arXiv上获取,我们正在努力将其发表在更具影响力的学术期刊上, 例如持续跟进 机器学习开源软件 的JMLR期刊。 如果您在工作中使用了PyPOTS,请按照以下格式引用并为将项目设为星标🌟,以便让更多人关注到它,对此我们深表感谢🤗。
据不完全统计,该 列表 为当前使用PyPOTS并在其论文中引用PyPOTS的科学研究项目
@article{du2023pypots,
title={{PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series}},
author={Wenjie Du},
year={2023},
eprint={2305.18811},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2305.18811},
doi={10.48550/arXiv.2305.18811},
}或者
Wenjie Du. (2023). PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series. arXiv, abs/2305.18811.https://arxiv.org/abs/2305.18811
非常欢迎您为这个有趣的项目做出贡献!
通过提交您的代码,您将能收获:
模板 (如:
pypots/imputation/template) 进行快速开发;您也可以通过为该项目设置星标🌟 ,帮助更多人关注它。 您的星标🌟 既是对PyPOTS的认可,也是对PyPOTS发展所做出的重要贡献!
👀 在 PyPOTS 网站 上可以查看我们用户所属机构的完整列表!
我们非常关心用户的反馈,因此我们正在建立PyPOTS社区:
如果您有任何建议、想法、或打算分享与时间序列相关的论文,请加入我们并告诉我们。 PyPOTS社区一个开放、透明、友好的社区,让我们共同努力建设和改进PyPOTS!
[^1]: Du, W., Cote, D., & Liu, Y. (2023). SAITS: Self-Attention-based Imputation for Time Series. Expert systems with applications. [^2]: Vaswani, A., Shazeer, N.M., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., & Polosukhin, I. (2017). Attention is All you Need. NeurIPS 2017. [^3]: Cao, W., Wang, D., Li, J., Zhou, H., Li, L., & Li, Y. (2018). BRITS: Bidirectional Recurrent Imputation for Time Series. NeurIPS 2018. [^4]: Che, Z., Purushotham, S., Cho, K., Sontag, D.A., & Liu, Y. (2018). Recurrent Neural Networks for Multivariate Time Series with Missing Values. Scientific Reports. [^5]: Zhang, X., Zeman, M., Tsiligkaridis, T., & Zitnik, M. (2022). Graph-Guided Network for Irregularly Sampled Multivariate Time Series. ICLR 2022. [^6]: Ma, Q., Chen, C., Li, S., & Cottrell, G. W. (2021). Learning Representations for Incomplete Time Series Clustering. AAAI 2021. [^7]: Jong, J.D., Emon, M.A., Wu, P., Karki, R., Sood, M., Godard, P., Ahmad, A., Vrooman, H.A., Hofmann-Apitius, M., & Fröhlich, H. (2019). Deep learning for clustering of multivariate clinical patient trajectories with missing values. GigaScience. [^8]: Chen, X., & Sun, L. (2021). Bayesian Temporal Factorization for Multidimensional Time Series Prediction. IEEE transactions on pattern analysis and machine intelligence. [^9]: Yoon, J., Zame, W. R., & van der Schaar, M. (2019). Estimating Missing Data in Temporal Data Streams Using Multi-Directional Recurrent Neural Networks. IEEE Transactions on Biomedical Engineering. [^10]: Miao, X., Wu, Y., Wang, J., Gao, Y., Mao, X., & Yin, J. (2021). Generative Semi-supervised Learning for Multivariate Time Series Imputation. AAAI 2021. [^11]: Fortuin, V., Baranchuk, D., Raetsch, G. & Mandt, S. (2020). GP-VAE: Deep Probabilistic Time Series Imputation. AISTATS 2020. [^12]: Tashiro, Y., Song, J., Song, Y., & Ermon, S. (2021). CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation. NeurIPS 2021. [^13]: Rubin, D. B. (1976). Inference and missing data. Biometrika. [^14]: Wu, H., Hu, T., Liu, Y., Zhou, H., Wang, J., & Long, M. (2023). TimesNet: Temporal 2d-variation modeling for general time series analysis. ICLR 2023 [^15]: Wu, H., Xu, J., Wang, J., & Long, M. (2021). Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. NeurIPS 2021. [^16]: Zhang, Y., & Yan, J. (2023). Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. ICLR 2023. [^17]: Zeng, A., Chen, M., Zhang, L., & Xu, Q. (2023). Are transformers effective for time series forecasting?. AAAI 2023 [^18]: Nie, Y., Nguyen, N. H., Sinthong, P., & Kalagnanam, J. (2023). A time series is worth 64 words: Long-term forecasting with transformers. ICLR 2023 [^19]: Woo, G., Liu, C., Sahoo, D., Kumar, A., & Hoi, S. (2023). ETSformer: Exponential Smoothing Transformers for Time-series Forecasting. ICLR 2023 [^20]: Zhou, T., Ma, Z., Wen, Q., Wang, X., Sun, L., & Jin, R. (2022). FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting. ICML 2022. [^21]: Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., & Zhang, W. (2021). Informer: Beyond efficient transformer for long sequence time-series forecasting. AAAI 2021.
 WenjieDu
commented
7 months ago
WenjieDu
commented
7 months ago 谢谢佳欣 @Justin0388,也谢谢思佳和海涛的建议!
佳欣请新建一个PR把最新版本提交,新建文件名为README_zh.md。有些小问题我会在merge之后帮忙修改。
再次感谢大家的贡献!🤗
Issue description
为了方便国内中文用户的使用以及中文的检索,我们需要一个中文版本的README